Compare commits
23 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
86960cdbb0 | ||
|
|
8b0afa0e57 | ||
|
|
ab21fbfd89 | ||
|
|
bdc72ec355 | ||
|
|
c8a5e36be8 | ||
|
|
1368caf66f | ||
|
|
30ea423ce8 | ||
|
|
19b0ddce40 | ||
|
|
383db35925 | ||
|
|
55ac056920 | ||
|
|
085c1c6875 | ||
|
|
a18e5b95ad | ||
|
|
3696c74bfb | ||
|
|
bbcff8dcd0 | ||
|
|
77c5bc9da9 | ||
|
|
65e24c942e | ||
|
|
22d1bda185 | ||
|
|
ab271ebe10 | ||
|
|
e1befe5077 | ||
|
|
fff237e111 | ||
|
|
598c25d43e | ||
|
|
5c03f2e7cc | ||
|
|
8d7a98d2ff |
@@ -0,0 +1,342 @@
|
||||
# Hermes Agent v0.8.0 (v2026.4.8)
|
||||
|
||||
**Release Date:** April 8, 2026
|
||||
|
||||
> The intelligence release — native Google AI Studio provider, live model switching across all platforms, self-optimized GPT/Codex guidance, smart inactivity timeouts, approval buttons, interactive model pickers, MCP OAuth 2.1, and 209 merged PRs with 82 resolved issues.
|
||||
|
||||
---
|
||||
|
||||
## ✨ Highlights
|
||||
|
||||
- **Google AI Studio (Gemini) Native Provider** — Direct access to Gemini models through Google's AI Studio API. Includes automatic models.dev registry integration for real-time context length detection across any provider. ([#5577](https://github.com/NousResearch/hermes-agent/pull/5577))
|
||||
|
||||
- **Live Model Switching (`/model` Command)** — Switch models and providers mid-session from CLI, Telegram, Discord, Slack, or any gateway platform. Aggregator-aware resolution keeps you on OpenRouter/Nous when possible, with automatic cross-provider fallback when needed. Interactive model pickers on Telegram and Discord with inline buttons. ([#5181](https://github.com/NousResearch/hermes-agent/pull/5181), [#5742](https://github.com/NousResearch/hermes-agent/pull/5742))
|
||||
|
||||
- **Self-Optimized GPT/Codex Tool-Use Guidance** — The agent diagnosed and patched 5 failure modes in GPT and Codex tool calling through automated behavioral benchmarking, dramatically improving reliability on OpenAI models. Includes execution discipline guidance and thinking-only prefill continuation for structured reasoning. ([#6120](https://github.com/NousResearch/hermes-agent/pull/6120), [#5414](https://github.com/NousResearch/hermes-agent/pull/5414), [#5931](https://github.com/NousResearch/hermes-agent/pull/5931))
|
||||
|
||||
- **Inactivity-Based Agent Timeouts** — Gateway and cron timeouts now track actual tool activity instead of wall-clock time. Long-running tasks that are actively working will never be killed — only truly idle agents time out. ([#5389](https://github.com/NousResearch/hermes-agent/pull/5389), [#5440](https://github.com/NousResearch/hermes-agent/pull/5440))
|
||||
|
||||
- **Approval Buttons on Slack & Telegram** — Dangerous command approval via native platform buttons instead of typing `/approve`. Slack gets thread context preservation; Telegram gets emoji reactions for approval status. ([#5890](https://github.com/NousResearch/hermes-agent/pull/5890), [#5975](https://github.com/NousResearch/hermes-agent/pull/5975))
|
||||
|
||||
- **MCP OAuth 2.1 PKCE + OSV Malware Scanning** — Full standards-compliant OAuth for MCP server authentication, plus automatic malware scanning of MCP extension packages via the OSV vulnerability database. ([#5420](https://github.com/NousResearch/hermes-agent/pull/5420), [#5305](https://github.com/NousResearch/hermes-agent/pull/5305))
|
||||
|
||||
- **Centralized Logging & Config Validation** — Structured logging to `~/.hermes/logs/` (agent.log + errors.log) with the `hermes logs` command for tailing and filtering. Config structure validation catches malformed YAML at startup before it causes cryptic failures. ([#5430](https://github.com/NousResearch/hermes-agent/pull/5430), [#5426](https://github.com/NousResearch/hermes-agent/pull/5426))
|
||||
|
||||
- **Plugin System Expansion** — Plugins can now register CLI subcommands, receive request-scoped API hooks with correlation IDs, prompt for required env vars during install, and hook into session lifecycle events (finalize/reset). ([#5295](https://github.com/NousResearch/hermes-agent/pull/5295), [#5427](https://github.com/NousResearch/hermes-agent/pull/5427), [#5470](https://github.com/NousResearch/hermes-agent/pull/5470), [#6129](https://github.com/NousResearch/hermes-agent/pull/6129))
|
||||
|
||||
- **Matrix Tier 1 & Platform Hardening** — Matrix gets reactions, read receipts, rich formatting, and room management. Discord adds channel controls and ignored channels. Signal gets full MEDIA: tag delivery. Mattermost gets file attachments. Comprehensive reliability fixes across all platforms. ([#5275](https://github.com/NousResearch/hermes-agent/pull/5275), [#5975](https://github.com/NousResearch/hermes-agent/pull/5975), [#5602](https://github.com/NousResearch/hermes-agent/pull/5602))
|
||||
|
||||
- **Security Hardening Pass** — Consolidated SSRF protections, timing attack mitigations, tar traversal prevention, credential leakage guards, cron path traversal hardening, and cross-session isolation. Terminal workdir sanitization across all backends. ([#5944](https://github.com/NousResearch/hermes-agent/pull/5944), [#5613](https://github.com/NousResearch/hermes-agent/pull/5613), [#5629](https://github.com/NousResearch/hermes-agent/pull/5629))
|
||||
|
||||
---
|
||||
|
||||
## 🏗️ Core Agent & Architecture
|
||||
|
||||
### Provider & Model Support
|
||||
- **Native Google AI Studio (Gemini) provider** with models.dev integration for automatic context length detection ([#5577](https://github.com/NousResearch/hermes-agent/pull/5577))
|
||||
- **`/model` command — full provider+model system overhaul** — live switching across CLI and all gateway platforms with aggregator-aware resolution ([#5181](https://github.com/NousResearch/hermes-agent/pull/5181))
|
||||
- **Interactive model picker for Telegram and Discord** — inline button-based model selection ([#5742](https://github.com/NousResearch/hermes-agent/pull/5742))
|
||||
- **Nous Portal free-tier model gating** with pricing display in model selection ([#5880](https://github.com/NousResearch/hermes-agent/pull/5880))
|
||||
- **Model pricing display** for OpenRouter and Nous Portal providers ([#5416](https://github.com/NousResearch/hermes-agent/pull/5416))
|
||||
- **xAI (Grok) prompt caching** via `x-grok-conv-id` header ([#5604](https://github.com/NousResearch/hermes-agent/pull/5604))
|
||||
- **Grok added to tool-use enforcement models** for direct xAI usage ([#5595](https://github.com/NousResearch/hermes-agent/pull/5595))
|
||||
- **MiniMax TTS provider** (speech-2.8) ([#4963](https://github.com/NousResearch/hermes-agent/pull/4963))
|
||||
- **Non-agentic model warning** — warns users when loading Hermes LLM models not designed for tool use ([#5378](https://github.com/NousResearch/hermes-agent/pull/5378))
|
||||
- **Ollama Cloud auth, /model switch persistence**, and alias tab completion ([#5269](https://github.com/NousResearch/hermes-agent/pull/5269))
|
||||
- **Preserve dots in OpenCode Go model names** (minimax-m2.7, glm-4.5, kimi-k2.5) ([#5597](https://github.com/NousResearch/hermes-agent/pull/5597))
|
||||
- **MiniMax models 404 fix** — strip /v1 from Anthropic base URL for OpenCode Go ([#4918](https://github.com/NousResearch/hermes-agent/pull/4918))
|
||||
- **Provider credential reset windows** honored in pooled failover ([#5188](https://github.com/NousResearch/hermes-agent/pull/5188))
|
||||
- **OAuth token sync** between credential pool and credentials file ([#4981](https://github.com/NousResearch/hermes-agent/pull/4981))
|
||||
- **Stale OAuth credentials** no longer block OpenRouter users on auto-detect ([#5746](https://github.com/NousResearch/hermes-agent/pull/5746))
|
||||
- **Codex OAuth credential pool disconnect** + expired token import fix ([#5681](https://github.com/NousResearch/hermes-agent/pull/5681))
|
||||
- **Codex pool entry sync** from `~/.codex/auth.json` on exhaustion — @GratefulDave ([#5610](https://github.com/NousResearch/hermes-agent/pull/5610))
|
||||
- **Auxiliary client payment fallback** — retry with next provider on 402 ([#5599](https://github.com/NousResearch/hermes-agent/pull/5599))
|
||||
- **Auxiliary client resolves named custom providers** and 'main' alias ([#5978](https://github.com/NousResearch/hermes-agent/pull/5978))
|
||||
- **Use mimo-v2-pro** for non-vision auxiliary tasks on Nous free tier ([#6018](https://github.com/NousResearch/hermes-agent/pull/6018))
|
||||
- **Vision auto-detection** tries main provider first ([#6041](https://github.com/NousResearch/hermes-agent/pull/6041))
|
||||
- **Provider re-ordering and Quick Install** — @austinpickett ([#4664](https://github.com/NousResearch/hermes-agent/pull/4664))
|
||||
- **Nous OAuth access_token** no longer used as inference API key — @SHL0MS ([#5564](https://github.com/NousResearch/hermes-agent/pull/5564))
|
||||
- **HERMES_PORTAL_BASE_URL env var** respected during Nous login — @benbarclay ([#5745](https://github.com/NousResearch/hermes-agent/pull/5745))
|
||||
- **Env var overrides** for Nous portal/inference URLs ([#5419](https://github.com/NousResearch/hermes-agent/pull/5419))
|
||||
- **Z.AI endpoint auto-detect** via probe and cache ([#5763](https://github.com/NousResearch/hermes-agent/pull/5763))
|
||||
- **MiniMax context lengths, model catalog, thinking guard, aux model, and config base_url** corrections ([#6082](https://github.com/NousResearch/hermes-agent/pull/6082))
|
||||
- **Community provider/model resolution fixes** — salvaged 4 community PRs + MiniMax aux URL ([#5983](https://github.com/NousResearch/hermes-agent/pull/5983))
|
||||
|
||||
### Agent Loop & Conversation
|
||||
- **Self-optimized GPT/Codex tool-use guidance** via automated behavioral benchmarking — agent self-diagnosed and patched 5 failure modes ([#6120](https://github.com/NousResearch/hermes-agent/pull/6120))
|
||||
- **GPT/Codex execution discipline guidance** in system prompts ([#5414](https://github.com/NousResearch/hermes-agent/pull/5414))
|
||||
- **Thinking-only prefill continuation** for structured reasoning responses ([#5931](https://github.com/NousResearch/hermes-agent/pull/5931))
|
||||
- **Accept reasoning-only responses** without retries — set content to "(empty)" instead of infinite retry ([#5278](https://github.com/NousResearch/hermes-agent/pull/5278))
|
||||
- **Jittered retry backoff** — exponential backoff with jitter for API retries ([#6048](https://github.com/NousResearch/hermes-agent/pull/6048))
|
||||
- **Smart thinking block signature management** — preserve and manage Anthropic thinking signatures across turns ([#6112](https://github.com/NousResearch/hermes-agent/pull/6112))
|
||||
- **Coerce tool call arguments** to match JSON Schema types — fixes models that send strings instead of numbers/booleans ([#5265](https://github.com/NousResearch/hermes-agent/pull/5265))
|
||||
- **Save oversized tool results to file** instead of destructive truncation ([#5210](https://github.com/NousResearch/hermes-agent/pull/5210))
|
||||
- **Sandbox-aware tool result persistence** ([#6085](https://github.com/NousResearch/hermes-agent/pull/6085))
|
||||
- **Streaming fallback** improved after edit failures ([#6110](https://github.com/NousResearch/hermes-agent/pull/6110))
|
||||
- **Codex empty-output gaps** covered in fallback + normalizer + auxiliary client ([#5724](https://github.com/NousResearch/hermes-agent/pull/5724), [#5730](https://github.com/NousResearch/hermes-agent/pull/5730), [#5734](https://github.com/NousResearch/hermes-agent/pull/5734))
|
||||
- **Codex stream output backfill** from output_item.done events ([#5689](https://github.com/NousResearch/hermes-agent/pull/5689))
|
||||
- **Stream consumer creates new message** after tool boundaries ([#5739](https://github.com/NousResearch/hermes-agent/pull/5739))
|
||||
- **Codex validation aligned** with normalization for empty stream output ([#5940](https://github.com/NousResearch/hermes-agent/pull/5940))
|
||||
- **Bridge tool-calls** in copilot-acp adapter ([#5460](https://github.com/NousResearch/hermes-agent/pull/5460))
|
||||
- **Filter transcript-only roles** from chat-completions payload ([#4880](https://github.com/NousResearch/hermes-agent/pull/4880))
|
||||
- **Context compaction failures fixed** on temperature-restricted models — @MadKangYu ([#5608](https://github.com/NousResearch/hermes-agent/pull/5608))
|
||||
- **Sanitize tool_calls for all strict APIs** (Fireworks, Mistral, etc.) — @lumethegreat ([#5183](https://github.com/NousResearch/hermes-agent/pull/5183))
|
||||
|
||||
### Memory & Sessions
|
||||
- **Supermemory memory provider** — new memory plugin with multi-container, search_mode, identity template, and env var override ([#5737](https://github.com/NousResearch/hermes-agent/pull/5737), [#5933](https://github.com/NousResearch/hermes-agent/pull/5933))
|
||||
- **Shared thread sessions** by default — multi-user thread support across gateway platforms ([#5391](https://github.com/NousResearch/hermes-agent/pull/5391))
|
||||
- **Subagent sessions linked to parent** and hidden from session list ([#5309](https://github.com/NousResearch/hermes-agent/pull/5309))
|
||||
- **Profile-scoped memory isolation** and clone support ([#4845](https://github.com/NousResearch/hermes-agent/pull/4845))
|
||||
- **Thread gateway user_id to memory plugins** for per-user scoping ([#5895](https://github.com/NousResearch/hermes-agent/pull/5895))
|
||||
- **Honcho plugin drift overhaul** + plugin CLI registration system ([#5295](https://github.com/NousResearch/hermes-agent/pull/5295))
|
||||
- **Honcho holographic prompt and trust score** rendering preserved ([#4872](https://github.com/NousResearch/hermes-agent/pull/4872))
|
||||
- **Honcho doctor fix** — use recall_mode instead of memory_mode — @techguysimon ([#5645](https://github.com/NousResearch/hermes-agent/pull/5645))
|
||||
- **RetainDB** — API routes, write queue, dialectic, agent model, file tools fixes ([#5461](https://github.com/NousResearch/hermes-agent/pull/5461))
|
||||
- **Hindsight memory plugin overhaul** + memory setup wizard fixes ([#5094](https://github.com/NousResearch/hermes-agent/pull/5094))
|
||||
- **mem0 API v2 compat**, prefetch context fencing, secret redaction ([#5423](https://github.com/NousResearch/hermes-agent/pull/5423))
|
||||
- **mem0 env vars merged** with mem0.json instead of either/or ([#4939](https://github.com/NousResearch/hermes-agent/pull/4939))
|
||||
- **Clean user message** used for all memory provider operations ([#4940](https://github.com/NousResearch/hermes-agent/pull/4940))
|
||||
- **Silent memory flush failure** on /new and /resume fixed — @ryanautomated ([#5640](https://github.com/NousResearch/hermes-agent/pull/5640))
|
||||
- **OpenViking atexit safety net** for session commit ([#5664](https://github.com/NousResearch/hermes-agent/pull/5664))
|
||||
- **OpenViking tenant-scoping headers** for multi-tenant servers ([#4936](https://github.com/NousResearch/hermes-agent/pull/4936))
|
||||
- **ByteRover brv query** runs synchronously before LLM call ([#4831](https://github.com/NousResearch/hermes-agent/pull/4831))
|
||||
|
||||
---
|
||||
|
||||
## 📱 Messaging Platforms (Gateway)
|
||||
|
||||
### Gateway Core
|
||||
- **Inactivity-based agent timeout** — replaces wall-clock timeout with smart activity tracking; long-running active tasks never killed ([#5389](https://github.com/NousResearch/hermes-agent/pull/5389))
|
||||
- **Approval buttons for Slack & Telegram** + Slack thread context preservation ([#5890](https://github.com/NousResearch/hermes-agent/pull/5890))
|
||||
- **Live-stream /update output** + forward interactive prompts to user ([#5180](https://github.com/NousResearch/hermes-agent/pull/5180))
|
||||
- **Infinite timeout support** + periodic notifications + actionable error messages ([#4959](https://github.com/NousResearch/hermes-agent/pull/4959))
|
||||
- **Duplicate message prevention** — gateway dedup + partial stream guard ([#4878](https://github.com/NousResearch/hermes-agent/pull/4878))
|
||||
- **Webhook delivery_info persistence** + full session id in /status ([#5942](https://github.com/NousResearch/hermes-agent/pull/5942))
|
||||
- **Tool preview truncation** respects tool_preview_length in all/new progress modes ([#5937](https://github.com/NousResearch/hermes-agent/pull/5937))
|
||||
- **Short preview truncation** restored for all/new tool progress modes ([#4935](https://github.com/NousResearch/hermes-agent/pull/4935))
|
||||
- **Update-pending state** written atomically to prevent corruption ([#4923](https://github.com/NousResearch/hermes-agent/pull/4923))
|
||||
- **Approval session key isolated** per turn ([#4884](https://github.com/NousResearch/hermes-agent/pull/4884))
|
||||
- **Active-session guard bypass** for /approve, /deny, /stop, /new ([#4926](https://github.com/NousResearch/hermes-agent/pull/4926), [#5765](https://github.com/NousResearch/hermes-agent/pull/5765))
|
||||
- **Typing indicator paused** during approval waits ([#5893](https://github.com/NousResearch/hermes-agent/pull/5893))
|
||||
- **Caption check** uses exact line-by-line match instead of substring (all platforms) ([#5939](https://github.com/NousResearch/hermes-agent/pull/5939))
|
||||
- **MEDIA: tags stripped** from streamed gateway messages ([#5152](https://github.com/NousResearch/hermes-agent/pull/5152))
|
||||
- **MEDIA: tags extracted** from cron delivery before sending ([#5598](https://github.com/NousResearch/hermes-agent/pull/5598))
|
||||
- **Profile-aware service units** + voice transcription cleanup ([#5972](https://github.com/NousResearch/hermes-agent/pull/5972))
|
||||
- **Thread-safe PairingStore** with atomic writes — @CharlieKerfoot ([#5656](https://github.com/NousResearch/hermes-agent/pull/5656))
|
||||
- **Sanitize media URLs** in base platform logs — @WAXLYY ([#5631](https://github.com/NousResearch/hermes-agent/pull/5631))
|
||||
- **Reduce Telegram fallback IP activation log noise** — @MadKangYu ([#5615](https://github.com/NousResearch/hermes-agent/pull/5615))
|
||||
- **Cron static method wrappers** to prevent self-binding ([#5299](https://github.com/NousResearch/hermes-agent/pull/5299))
|
||||
- **Stale 'hermes login' replaced** with 'hermes auth' + credential removal re-seeding fix ([#5670](https://github.com/NousResearch/hermes-agent/pull/5670))
|
||||
|
||||
### Telegram
|
||||
- **Group topics skill binding** for supergroup forum topics ([#4886](https://github.com/NousResearch/hermes-agent/pull/4886))
|
||||
- **Emoji reactions** for approval status and notifications ([#5975](https://github.com/NousResearch/hermes-agent/pull/5975))
|
||||
- **Duplicate message delivery prevented** on send timeout ([#5153](https://github.com/NousResearch/hermes-agent/pull/5153))
|
||||
- **Command names sanitized** to strip invalid characters ([#5596](https://github.com/NousResearch/hermes-agent/pull/5596))
|
||||
- **Per-platform disabled skills** respected in Telegram menu and gateway dispatch ([#4799](https://github.com/NousResearch/hermes-agent/pull/4799))
|
||||
- **/approve and /deny** routed through running-agent guard ([#4798](https://github.com/NousResearch/hermes-agent/pull/4798))
|
||||
|
||||
### Discord
|
||||
- **Channel controls** — ignored_channels and no_thread_channels config options ([#5975](https://github.com/NousResearch/hermes-agent/pull/5975))
|
||||
- **Skills registered as native slash commands** via shared gateway logic ([#5603](https://github.com/NousResearch/hermes-agent/pull/5603))
|
||||
- **/approve, /deny, /queue, /background, /btw** registered as native slash commands ([#4800](https://github.com/NousResearch/hermes-agent/pull/4800), [#5477](https://github.com/NousResearch/hermes-agent/pull/5477))
|
||||
- **Unnecessary members intent** removed on startup + token lock leak fix ([#5302](https://github.com/NousResearch/hermes-agent/pull/5302))
|
||||
|
||||
### Slack
|
||||
- **Thread engagement** — auto-respond in bot-started and mentioned threads ([#5897](https://github.com/NousResearch/hermes-agent/pull/5897))
|
||||
- **mrkdwn in edit_message** + thread replies without @mentions ([#5733](https://github.com/NousResearch/hermes-agent/pull/5733))
|
||||
|
||||
### Matrix
|
||||
- **Tier 1 feature parity** — reactions, read receipts, rich formatting, room management ([#5275](https://github.com/NousResearch/hermes-agent/pull/5275))
|
||||
- **MATRIX_REQUIRE_MENTION and MATRIX_AUTO_THREAD** support ([#5106](https://github.com/NousResearch/hermes-agent/pull/5106))
|
||||
- **Comprehensive reliability** — encrypted media, auth recovery, cron E2EE, Synapse compat ([#5271](https://github.com/NousResearch/hermes-agent/pull/5271))
|
||||
- **CJK input, E2EE, and reconnect** fixes ([#5665](https://github.com/NousResearch/hermes-agent/pull/5665))
|
||||
|
||||
### Signal
|
||||
- **Full MEDIA: tag delivery** — send_image_file, send_voice, and send_video implemented ([#5602](https://github.com/NousResearch/hermes-agent/pull/5602))
|
||||
|
||||
### Mattermost
|
||||
- **File attachments** — set message type to DOCUMENT when post has file attachments — @nericervin ([#5609](https://github.com/NousResearch/hermes-agent/pull/5609))
|
||||
|
||||
### Feishu
|
||||
- **Interactive card approval buttons** ([#6043](https://github.com/NousResearch/hermes-agent/pull/6043))
|
||||
- **Reconnect and ACL** fixes ([#5665](https://github.com/NousResearch/hermes-agent/pull/5665))
|
||||
|
||||
### Webhooks
|
||||
- **`{__raw__}` template token** and thread_id passthrough for forum topics ([#5662](https://github.com/NousResearch/hermes-agent/pull/5662))
|
||||
|
||||
---
|
||||
|
||||
## 🖥️ CLI & User Experience
|
||||
|
||||
### Interactive CLI
|
||||
- **Defer response content** until reasoning block completes ([#5773](https://github.com/NousResearch/hermes-agent/pull/5773))
|
||||
- **Ghost status-bar lines cleared** on terminal resize ([#4960](https://github.com/NousResearch/hermes-agent/pull/4960))
|
||||
- **Normalise \r\n and \r line endings** in pasted text ([#4849](https://github.com/NousResearch/hermes-agent/pull/4849))
|
||||
- **ChatConsole errors, curses scroll, skin-aware banner, git state** banner fixes ([#5974](https://github.com/NousResearch/hermes-agent/pull/5974))
|
||||
- **Native Windows image paste** support ([#5917](https://github.com/NousResearch/hermes-agent/pull/5917))
|
||||
- **--yolo and other flags** no longer silently dropped when placed before 'chat' subcommand ([#5145](https://github.com/NousResearch/hermes-agent/pull/5145))
|
||||
|
||||
### Setup & Configuration
|
||||
- **Config structure validation** — detect malformed YAML at startup with actionable error messages ([#5426](https://github.com/NousResearch/hermes-agent/pull/5426))
|
||||
- **Centralized logging** to `~/.hermes/logs/` — agent.log (INFO+), errors.log (WARNING+) with `hermes logs` command ([#5430](https://github.com/NousResearch/hermes-agent/pull/5430))
|
||||
- **Docs links added** to setup wizard sections ([#5283](https://github.com/NousResearch/hermes-agent/pull/5283))
|
||||
- **Doctor diagnostics** — sync provider checks, config migration, WAL and mem0 diagnostics ([#5077](https://github.com/NousResearch/hermes-agent/pull/5077))
|
||||
- **Timeout debug logging** and user-facing diagnostics improved ([#5370](https://github.com/NousResearch/hermes-agent/pull/5370))
|
||||
- **Reasoning effort unified** to config.yaml only ([#6118](https://github.com/NousResearch/hermes-agent/pull/6118))
|
||||
- **Permanent command allowlist** loaded on startup ([#5076](https://github.com/NousResearch/hermes-agent/pull/5076))
|
||||
- **`hermes auth remove`** now clears env-seeded credentials permanently ([#5285](https://github.com/NousResearch/hermes-agent/pull/5285))
|
||||
- **Bundled skills synced to all profiles** during update ([#5795](https://github.com/NousResearch/hermes-agent/pull/5795))
|
||||
- **`hermes update` no longer kills** freshly-restarted gateway service ([#5448](https://github.com/NousResearch/hermes-agent/pull/5448))
|
||||
- **Subprocess.run() timeouts** added to all gateway CLI commands ([#5424](https://github.com/NousResearch/hermes-agent/pull/5424))
|
||||
- **Actionable error message** when Codex refresh token is reused — @tymrtn ([#5612](https://github.com/NousResearch/hermes-agent/pull/5612))
|
||||
- **Google-workspace skill scripts** can now run directly — @xinbenlv ([#5624](https://github.com/NousResearch/hermes-agent/pull/5624))
|
||||
|
||||
### Cron System
|
||||
- **Inactivity-based cron timeout** — replaces wall-clock; active tasks run indefinitely ([#5440](https://github.com/NousResearch/hermes-agent/pull/5440))
|
||||
- **Pre-run script injection** for data collection and change detection ([#5082](https://github.com/NousResearch/hermes-agent/pull/5082))
|
||||
- **Delivery failure tracking** in job status ([#6042](https://github.com/NousResearch/hermes-agent/pull/6042))
|
||||
- **Delivery guidance** in cron prompts — stops send_message thrashing ([#5444](https://github.com/NousResearch/hermes-agent/pull/5444))
|
||||
- **MEDIA files delivered** as native platform attachments ([#5921](https://github.com/NousResearch/hermes-agent/pull/5921))
|
||||
- **[SILENT] suppression** works anywhere in response — @auspic7 ([#5654](https://github.com/NousResearch/hermes-agent/pull/5654))
|
||||
- **Cron path traversal** hardening ([#5147](https://github.com/NousResearch/hermes-agent/pull/5147))
|
||||
|
||||
---
|
||||
|
||||
## 🔧 Tool System
|
||||
|
||||
### Terminal & Execution
|
||||
- **Execute_code on remote backends** — code execution now works on Docker, SSH, Modal, and other remote terminal backends ([#5088](https://github.com/NousResearch/hermes-agent/pull/5088))
|
||||
- **Exit code context** for common CLI tools in terminal results — helps agent understand what went wrong ([#5144](https://github.com/NousResearch/hermes-agent/pull/5144))
|
||||
- **Progressive subdirectory hint discovery** — agent learns project structure as it navigates ([#5291](https://github.com/NousResearch/hermes-agent/pull/5291))
|
||||
- **notify_on_complete for background processes** — get notified when long-running tasks finish ([#5779](https://github.com/NousResearch/hermes-agent/pull/5779))
|
||||
- **Docker env config** — explicit container environment variables via docker_env config ([#4738](https://github.com/NousResearch/hermes-agent/pull/4738))
|
||||
- **Approval metadata included** in terminal tool results ([#5141](https://github.com/NousResearch/hermes-agent/pull/5141))
|
||||
- **Workdir parameter sanitized** in terminal tool across all backends ([#5629](https://github.com/NousResearch/hermes-agent/pull/5629))
|
||||
- **Detached process crash recovery** state corrected ([#6101](https://github.com/NousResearch/hermes-agent/pull/6101))
|
||||
- **Agent-browser paths with spaces** preserved — @Vasanthdev2004 ([#6077](https://github.com/NousResearch/hermes-agent/pull/6077))
|
||||
- **Portable base64 encoding** for image reading on macOS — @CharlieKerfoot ([#5657](https://github.com/NousResearch/hermes-agent/pull/5657))
|
||||
|
||||
### Browser
|
||||
- **Switch managed browser provider** from Browserbase to Browser Use — @benbarclay ([#5750](https://github.com/NousResearch/hermes-agent/pull/5750))
|
||||
- **Firecrawl cloud browser** provider — @alt-glitch ([#5628](https://github.com/NousResearch/hermes-agent/pull/5628))
|
||||
- **JS evaluation** via browser_console expression parameter ([#5303](https://github.com/NousResearch/hermes-agent/pull/5303))
|
||||
- **Windows browser** fixes ([#5665](https://github.com/NousResearch/hermes-agent/pull/5665))
|
||||
|
||||
### MCP
|
||||
- **MCP OAuth 2.1 PKCE** — full standards-compliant OAuth client support ([#5420](https://github.com/NousResearch/hermes-agent/pull/5420))
|
||||
- **OSV malware check** for MCP extension packages ([#5305](https://github.com/NousResearch/hermes-agent/pull/5305))
|
||||
- **Prefer structuredContent over text** + no_mcp sentinel ([#5979](https://github.com/NousResearch/hermes-agent/pull/5979))
|
||||
- **Unknown toolsets warning suppressed** for MCP server names ([#5279](https://github.com/NousResearch/hermes-agent/pull/5279))
|
||||
|
||||
### Web & Files
|
||||
- **.zip document support** + auto-mount cache dirs into remote backends ([#4846](https://github.com/NousResearch/hermes-agent/pull/4846))
|
||||
- **Redact query secrets** in send_message errors — @WAXLYY ([#5650](https://github.com/NousResearch/hermes-agent/pull/5650))
|
||||
|
||||
### Delegation
|
||||
- **Credential pool sharing** + workspace path hints for subagents ([#5748](https://github.com/NousResearch/hermes-agent/pull/5748))
|
||||
|
||||
### ACP (VS Code / Zed / JetBrains)
|
||||
- **Aggregate ACP improvements** — auth compat, protocol fixes, command ads, delegation, SSE events ([#5292](https://github.com/NousResearch/hermes-agent/pull/5292))
|
||||
|
||||
---
|
||||
|
||||
## 🧩 Skills Ecosystem
|
||||
|
||||
### Skills System
|
||||
- **Skill config interface** — skills can declare required config.yaml settings, prompted during setup, injected at load time ([#5635](https://github.com/NousResearch/hermes-agent/pull/5635))
|
||||
- **Plugin CLI registration system** — plugins register their own CLI subcommands without touching main.py ([#5295](https://github.com/NousResearch/hermes-agent/pull/5295))
|
||||
- **Request-scoped API hooks** with tool call correlation IDs for plugins ([#5427](https://github.com/NousResearch/hermes-agent/pull/5427))
|
||||
- **Session lifecycle hooks** — on_session_finalize and on_session_reset for CLI + gateway ([#6129](https://github.com/NousResearch/hermes-agent/pull/6129))
|
||||
- **Prompt for required env vars** during plugin install — @kshitijk4poor ([#5470](https://github.com/NousResearch/hermes-agent/pull/5470))
|
||||
- **Plugin name validation** — reject names that resolve to plugins root ([#5368](https://github.com/NousResearch/hermes-agent/pull/5368))
|
||||
- **pre_llm_call plugin context** moved to user message to preserve prompt cache ([#5146](https://github.com/NousResearch/hermes-agent/pull/5146))
|
||||
|
||||
### New & Updated Skills
|
||||
- **popular-web-designs** — 54 production website design systems ([#5194](https://github.com/NousResearch/hermes-agent/pull/5194))
|
||||
- **p5js creative coding** — @SHL0MS ([#5600](https://github.com/NousResearch/hermes-agent/pull/5600))
|
||||
- **manim-video** — mathematical and technical animations — @SHL0MS ([#4930](https://github.com/NousResearch/hermes-agent/pull/4930))
|
||||
- **llm-wiki** — Karpathy's LLM Wiki skill ([#5635](https://github.com/NousResearch/hermes-agent/pull/5635))
|
||||
- **gitnexus-explorer** — codebase indexing and knowledge serving ([#5208](https://github.com/NousResearch/hermes-agent/pull/5208))
|
||||
- **research-paper-writing** — AI-Scientist & GPT-Researcher patterns — @SHL0MS ([#5421](https://github.com/NousResearch/hermes-agent/pull/5421))
|
||||
- **blogwatcher** updated to JulienTant's fork ([#5759](https://github.com/NousResearch/hermes-agent/pull/5759))
|
||||
- **claude-code skill** comprehensive rewrite v2.0 + v2.2 ([#5155](https://github.com/NousResearch/hermes-agent/pull/5155), [#5158](https://github.com/NousResearch/hermes-agent/pull/5158))
|
||||
- **Code verification skills** consolidated into one ([#4854](https://github.com/NousResearch/hermes-agent/pull/4854))
|
||||
- **Manim CE reference docs** expanded — geometry, animations, LaTeX — @leotrs ([#5791](https://github.com/NousResearch/hermes-agent/pull/5791))
|
||||
- **Manim-video references** — design thinking, updaters, paper explainer, decorations, production quality — @SHL0MS ([#5588](https://github.com/NousResearch/hermes-agent/pull/5588), [#5408](https://github.com/NousResearch/hermes-agent/pull/5408))
|
||||
|
||||
---
|
||||
|
||||
## 🔒 Security & Reliability
|
||||
|
||||
### Security Hardening
|
||||
- **Consolidated security** — SSRF protections, timing attack mitigations, tar traversal prevention, credential leakage guards ([#5944](https://github.com/NousResearch/hermes-agent/pull/5944))
|
||||
- **Cross-session isolation** + cron path traversal hardening ([#5613](https://github.com/NousResearch/hermes-agent/pull/5613))
|
||||
- **Workdir parameter sanitized** in terminal tool across all backends ([#5629](https://github.com/NousResearch/hermes-agent/pull/5629))
|
||||
- **Approval 'once' session escalation** prevented + cron delivery platform validation ([#5280](https://github.com/NousResearch/hermes-agent/pull/5280))
|
||||
- **Profile-scoped Google Workspace OAuth tokens** protected ([#4910](https://github.com/NousResearch/hermes-agent/pull/4910))
|
||||
|
||||
### Reliability
|
||||
- **Aggressive worktree and branch cleanup** to prevent accumulation ([#6134](https://github.com/NousResearch/hermes-agent/pull/6134))
|
||||
- **O(n²) catastrophic backtracking** in redact regex fixed — 100x improvement on large outputs ([#4962](https://github.com/NousResearch/hermes-agent/pull/4962))
|
||||
- **Runtime stability fixes** across core, web, delegate, and browser tools ([#4843](https://github.com/NousResearch/hermes-agent/pull/4843))
|
||||
- **API server streaming fix** + conversation history support ([#5977](https://github.com/NousResearch/hermes-agent/pull/5977))
|
||||
- **OpenViking API endpoint paths** and response parsing corrected ([#5078](https://github.com/NousResearch/hermes-agent/pull/5078))
|
||||
|
||||
---
|
||||
|
||||
## 🐛 Notable Bug Fixes
|
||||
|
||||
- **9 community bugfixes salvaged** — gateway, cron, deps, macOS launchd in one batch ([#5288](https://github.com/NousResearch/hermes-agent/pull/5288))
|
||||
- **Batch core bug fixes** — model config, session reset, alias fallback, launchctl, delegation, atomic writes ([#5630](https://github.com/NousResearch/hermes-agent/pull/5630))
|
||||
- **Batch gateway/platform fixes** — matrix E2EE, CJK input, Windows browser, Feishu reconnect + ACL ([#5665](https://github.com/NousResearch/hermes-agent/pull/5665))
|
||||
- **Stale test skips removed**, regex backtracking, file search bug, and test flakiness ([#4969](https://github.com/NousResearch/hermes-agent/pull/4969))
|
||||
- **Nix flake** — read version, regen uv.lock, add hermes_logging — @alt-glitch ([#5651](https://github.com/NousResearch/hermes-agent/pull/5651))
|
||||
- **Lowercase variable redaction** regression tests ([#5185](https://github.com/NousResearch/hermes-agent/pull/5185))
|
||||
|
||||
---
|
||||
|
||||
## 🧪 Testing
|
||||
|
||||
- **57 failing CI tests repaired** across 14 files ([#5823](https://github.com/NousResearch/hermes-agent/pull/5823))
|
||||
- **Test suite re-architecture** + CI failure fixes — @alt-glitch ([#5946](https://github.com/NousResearch/hermes-agent/pull/5946))
|
||||
- **Codebase-wide lint cleanup** — unused imports, dead code, and inefficient patterns ([#5821](https://github.com/NousResearch/hermes-agent/pull/5821))
|
||||
- **browser_close tool removed** — auto-cleanup handles it ([#5792](https://github.com/NousResearch/hermes-agent/pull/5792))
|
||||
|
||||
---
|
||||
|
||||
## 📚 Documentation
|
||||
|
||||
- **Comprehensive documentation audit** — fix stale info, expand thin pages, add depth ([#5393](https://github.com/NousResearch/hermes-agent/pull/5393))
|
||||
- **40+ discrepancies fixed** between documentation and codebase ([#5818](https://github.com/NousResearch/hermes-agent/pull/5818))
|
||||
- **13 features documented** from last week's PRs ([#5815](https://github.com/NousResearch/hermes-agent/pull/5815))
|
||||
- **Guides section overhaul** — fix existing + add 3 new tutorials ([#5735](https://github.com/NousResearch/hermes-agent/pull/5735))
|
||||
- **Salvaged 4 docs PRs** — docker setup, post-update validation, local LLM guide, signal-cli install ([#5727](https://github.com/NousResearch/hermes-agent/pull/5727))
|
||||
- **Discord configuration reference** ([#5386](https://github.com/NousResearch/hermes-agent/pull/5386))
|
||||
- **Community FAQ entries** for common workflows and troubleshooting ([#4797](https://github.com/NousResearch/hermes-agent/pull/4797))
|
||||
- **WSL2 networking guide** for local model servers ([#5616](https://github.com/NousResearch/hermes-agent/pull/5616))
|
||||
- **Honcho CLI reference** + plugin CLI registration docs ([#5308](https://github.com/NousResearch/hermes-agent/pull/5308))
|
||||
- **Obsidian Headless setup** for servers in llm-wiki ([#5660](https://github.com/NousResearch/hermes-agent/pull/5660))
|
||||
- **Hermes Mod visual skin editor** added to skins page ([#6095](https://github.com/NousResearch/hermes-agent/pull/6095))
|
||||
|
||||
---
|
||||
|
||||
## 👥 Contributors
|
||||
|
||||
### Core
|
||||
- **@teknium1** — 179 PRs
|
||||
|
||||
### Top Community Contributors
|
||||
- **@SHL0MS** (7 PRs) — p5js creative coding skill, manim-video skill + 5 reference expansions, research-paper-writing, Nous OAuth fix, manim font fix
|
||||
- **@alt-glitch** (3 PRs) — Firecrawl cloud browser provider, test re-architecture + CI fixes, Nix flake fixes
|
||||
- **@benbarclay** (2 PRs) — Browser Use managed provider switch, Nous portal base URL fix
|
||||
- **@CharlieKerfoot** (2 PRs) — macOS portable base64 encoding, thread-safe PairingStore
|
||||
- **@WAXLYY** (2 PRs) — send_message secret redaction, gateway media URL sanitization
|
||||
- **@MadKangYu** (2 PRs) — Telegram log noise reduction, context compaction fix for temperature-restricted models
|
||||
|
||||
### All Contributors
|
||||
@alt-glitch, @austinpickett, @auspic7, @benbarclay, @CharlieKerfoot, @GratefulDave, @kshitijk4poor, @leotrs, @lumethegreat, @MadKangYu, @nericervin, @ryanautomated, @SHL0MS, @techguysimon, @tymrtn, @Vasanthdev2004, @WAXLYY, @xinbenlv
|
||||
|
||||
---
|
||||
|
||||
**Full Changelog**: [v2026.4.3...v2026.4.8](https://github.com/NousResearch/hermes-agent/compare/v2026.4.3...v2026.4.8)
|
||||
@@ -1102,7 +1102,15 @@ def convert_messages_to_anthropic(
|
||||
curr_content = [{"type": "text", "text": curr_content}]
|
||||
fixed[-1]["content"] = prev_content + curr_content
|
||||
else:
|
||||
# Consecutive assistant messages — merge text content
|
||||
# Consecutive assistant messages — merge text content.
|
||||
# Drop thinking blocks from the *second* message: their
|
||||
# signature was computed against a different turn boundary
|
||||
# and becomes invalid once merged.
|
||||
if isinstance(m["content"], list):
|
||||
m["content"] = [
|
||||
b for b in m["content"]
|
||||
if not (isinstance(b, dict) and b.get("type") in ("thinking", "redacted_thinking"))
|
||||
]
|
||||
prev_blocks = fixed[-1]["content"]
|
||||
curr_blocks = m["content"]
|
||||
if isinstance(prev_blocks, list) and isinstance(curr_blocks, list):
|
||||
@@ -1120,6 +1128,68 @@ def convert_messages_to_anthropic(
|
||||
fixed.append(m)
|
||||
result = fixed
|
||||
|
||||
# ── Thinking block signature management ──────────────────────────
|
||||
# Anthropic signs thinking blocks against the full turn content.
|
||||
# Any upstream mutation (context compression, session truncation,
|
||||
# orphan stripping, message merging) invalidates the signature,
|
||||
# causing HTTP 400 "Invalid signature in thinking block".
|
||||
#
|
||||
# Strategy (following clawdbot/OpenClaw pattern):
|
||||
# 1. Strip thinking/redacted_thinking from all assistant messages
|
||||
# EXCEPT the last one — preserves reasoning continuity on the
|
||||
# current tool-use chain while avoiding stale signature errors.
|
||||
# 2. Downgrade unsigned thinking blocks (no signature) to text —
|
||||
# Anthropic can't validate them and will reject them.
|
||||
# 3. Strip cache_control from thinking/redacted_thinking blocks —
|
||||
# cache markers can interfere with signature validation.
|
||||
_THINKING_TYPES = frozenset(("thinking", "redacted_thinking"))
|
||||
|
||||
last_assistant_idx = None
|
||||
for i in range(len(result) - 1, -1, -1):
|
||||
if result[i].get("role") == "assistant":
|
||||
last_assistant_idx = i
|
||||
break
|
||||
|
||||
for idx, m in enumerate(result):
|
||||
if m.get("role") != "assistant" or not isinstance(m.get("content"), list):
|
||||
continue
|
||||
|
||||
if idx != last_assistant_idx:
|
||||
# Strip ALL thinking blocks from non-latest assistant messages
|
||||
stripped = [
|
||||
b for b in m["content"]
|
||||
if not (isinstance(b, dict) and b.get("type") in _THINKING_TYPES)
|
||||
]
|
||||
m["content"] = stripped or [{"type": "text", "text": "(thinking elided)"}]
|
||||
else:
|
||||
# Latest assistant: keep signed thinking blocks for reasoning
|
||||
# continuity; downgrade unsigned ones to plain text.
|
||||
new_content = []
|
||||
for b in m["content"]:
|
||||
if not isinstance(b, dict) or b.get("type") not in _THINKING_TYPES:
|
||||
new_content.append(b)
|
||||
continue
|
||||
if b.get("type") == "redacted_thinking":
|
||||
# Redacted blocks use 'data' for the signature payload
|
||||
if b.get("data"):
|
||||
new_content.append(b)
|
||||
# else: drop — no data means it can't be validated
|
||||
elif b.get("signature"):
|
||||
# Signed thinking block — keep it
|
||||
new_content.append(b)
|
||||
else:
|
||||
# Unsigned thinking — downgrade to text so it's not lost
|
||||
thinking_text = b.get("thinking", "")
|
||||
if thinking_text:
|
||||
new_content.append({"type": "text", "text": thinking_text})
|
||||
m["content"] = new_content or [{"type": "text", "text": "(empty)"}]
|
||||
|
||||
# Strip cache_control from any remaining thinking/redacted_thinking
|
||||
# blocks — cache markers interfere with signature validation.
|
||||
for b in m["content"]:
|
||||
if isinstance(b, dict) and b.get("type") in _THINKING_TYPES:
|
||||
b.pop("cache_control", None)
|
||||
|
||||
return system, result
|
||||
|
||||
|
||||
@@ -1224,9 +1294,9 @@ def build_anthropic_kwargs(
|
||||
# Map reasoning_config to Anthropic's thinking parameter.
|
||||
# Claude 4.6 models use adaptive thinking + output_config.effort.
|
||||
# Older models use manual thinking with budget_tokens.
|
||||
# Haiku models do NOT support extended thinking at all — skip entirely.
|
||||
# Haiku and MiniMax models do NOT support extended thinking — skip entirely.
|
||||
if reasoning_config and isinstance(reasoning_config, dict):
|
||||
if reasoning_config.get("enabled") is not False and "haiku" not in model.lower():
|
||||
if reasoning_config.get("enabled") is not False and "haiku" not in model.lower() and "minimax" not in model.lower():
|
||||
effort = str(reasoning_config.get("effort", "medium")).lower()
|
||||
budget = THINKING_BUDGET.get(effort, 8000)
|
||||
if _supports_adaptive_thinking(model):
|
||||
|
||||
+107
-53
@@ -59,13 +59,48 @@ from hermes_constants import OPENROUTER_BASE_URL
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
_PROVIDER_ALIASES = {
|
||||
"google": "gemini",
|
||||
"google-gemini": "gemini",
|
||||
"google-ai-studio": "gemini",
|
||||
"glm": "zai",
|
||||
"z-ai": "zai",
|
||||
"z.ai": "zai",
|
||||
"zhipu": "zai",
|
||||
"kimi": "kimi-coding",
|
||||
"moonshot": "kimi-coding",
|
||||
"minimax-china": "minimax-cn",
|
||||
"minimax_cn": "minimax-cn",
|
||||
"claude": "anthropic",
|
||||
"claude-code": "anthropic",
|
||||
}
|
||||
|
||||
|
||||
def _normalize_aux_provider(provider: Optional[str], *, for_vision: bool = False) -> str:
|
||||
normalized = (provider or "auto").strip().lower()
|
||||
if normalized.startswith("custom:"):
|
||||
suffix = normalized.split(":", 1)[1].strip()
|
||||
if not suffix:
|
||||
return "custom"
|
||||
normalized = suffix if not for_vision else "custom"
|
||||
if normalized == "codex":
|
||||
return "openai-codex"
|
||||
if normalized == "main":
|
||||
# Resolve to the user's actual main provider so named custom providers
|
||||
# and non-aggregator providers (DeepSeek, Alibaba, etc.) work correctly.
|
||||
main_prov = _read_main_provider()
|
||||
if main_prov and main_prov not in ("auto", "main", ""):
|
||||
return main_prov
|
||||
return "custom"
|
||||
return _PROVIDER_ALIASES.get(normalized, normalized)
|
||||
|
||||
# Default auxiliary models for direct API-key providers (cheap/fast for side tasks)
|
||||
_API_KEY_PROVIDER_AUX_MODELS: Dict[str, str] = {
|
||||
"gemini": "gemini-3-flash-preview",
|
||||
"zai": "glm-4.5-flash",
|
||||
"kimi-coding": "kimi-k2-turbo-preview",
|
||||
"minimax": "MiniMax-M2.7-highspeed",
|
||||
"minimax-cn": "MiniMax-M2.7-highspeed",
|
||||
"minimax": "MiniMax-M2.7",
|
||||
"minimax-cn": "MiniMax-M2.7",
|
||||
"anthropic": "claude-haiku-4-5-20251001",
|
||||
"ai-gateway": "google/gemini-3-flash",
|
||||
"opencode-zen": "gemini-3-flash",
|
||||
@@ -92,6 +127,7 @@ auxiliary_is_nous: bool = False
|
||||
_OPENROUTER_MODEL = "google/gemini-3-flash-preview"
|
||||
_NOUS_MODEL = "google/gemini-3-flash-preview"
|
||||
_NOUS_FREE_TIER_VISION_MODEL = "xiaomi/mimo-v2-omni"
|
||||
_NOUS_FREE_TIER_AUX_MODEL = "xiaomi/mimo-v2-pro"
|
||||
_NOUS_DEFAULT_BASE_URL = "https://inference-api.nousresearch.com/v1"
|
||||
_ANTHROPIC_DEFAULT_BASE_URL = "https://api.anthropic.com"
|
||||
_AUTH_JSON_PATH = get_hermes_home() / "auth.json"
|
||||
@@ -105,6 +141,23 @@ _CODEX_AUX_MODEL = "gpt-5.2-codex"
|
||||
_CODEX_AUX_BASE_URL = "https://chatgpt.com/backend-api/codex"
|
||||
|
||||
|
||||
def _to_openai_base_url(base_url: str) -> str:
|
||||
"""Normalize an Anthropic-style base URL to OpenAI-compatible format.
|
||||
|
||||
Some providers (MiniMax, MiniMax-CN) expose an ``/anthropic`` endpoint for
|
||||
the Anthropic Messages API and a separate ``/v1`` endpoint for OpenAI chat
|
||||
completions. The auxiliary client uses the OpenAI SDK, so it must hit the
|
||||
``/v1`` surface. Passing the raw ``inference_base_url`` causes requests to
|
||||
land on ``/anthropic/chat/completions`` — a 404.
|
||||
"""
|
||||
url = str(base_url or "").strip().rstrip("/")
|
||||
if url.endswith("/anthropic"):
|
||||
rewritten = url[: -len("/anthropic")] + "/v1"
|
||||
logger.debug("Auxiliary client: rewrote base URL %s → %s", url, rewritten)
|
||||
return rewritten
|
||||
return url
|
||||
|
||||
|
||||
def _select_pool_entry(provider: str) -> Tuple[bool, Optional[Any]]:
|
||||
"""Return (pool_exists_for_provider, selected_entry)."""
|
||||
try:
|
||||
@@ -634,7 +687,9 @@ def _resolve_api_key_provider() -> Tuple[Optional[OpenAI], Optional[str]]:
|
||||
if not api_key:
|
||||
continue
|
||||
|
||||
base_url = _pool_runtime_base_url(entry, pconfig.inference_base_url) or pconfig.inference_base_url
|
||||
base_url = _to_openai_base_url(
|
||||
_pool_runtime_base_url(entry, pconfig.inference_base_url) or pconfig.inference_base_url
|
||||
)
|
||||
model = _API_KEY_PROVIDER_AUX_MODELS.get(provider_id, "default")
|
||||
logger.debug("Auxiliary text client: %s (%s) via pool", pconfig.name, model)
|
||||
extra = {}
|
||||
@@ -651,7 +706,9 @@ def _resolve_api_key_provider() -> Tuple[Optional[OpenAI], Optional[str]]:
|
||||
if not api_key:
|
||||
continue
|
||||
|
||||
base_url = str(creds.get("base_url", "")).strip().rstrip("/") or pconfig.inference_base_url
|
||||
base_url = _to_openai_base_url(
|
||||
str(creds.get("base_url", "")).strip().rstrip("/") or pconfig.inference_base_url
|
||||
)
|
||||
model = _API_KEY_PROVIDER_AUX_MODELS.get(provider_id, "default")
|
||||
logger.debug("Auxiliary text client: %s (%s)", pconfig.name, model)
|
||||
extra = {}
|
||||
@@ -713,7 +770,7 @@ def _try_openrouter() -> Tuple[Optional[OpenAI], Optional[str]]:
|
||||
default_headers=_OR_HEADERS), _OPENROUTER_MODEL
|
||||
|
||||
|
||||
def _try_nous() -> Tuple[Optional[OpenAI], Optional[str]]:
|
||||
def _try_nous(vision: bool = False) -> Tuple[Optional[OpenAI], Optional[str]]:
|
||||
nous = _read_nous_auth()
|
||||
if not nous:
|
||||
return None, None
|
||||
@@ -725,12 +782,13 @@ def _try_nous() -> Tuple[Optional[OpenAI], Optional[str]]:
|
||||
else:
|
||||
model = _NOUS_MODEL
|
||||
# Free-tier users can't use paid auxiliary models — use the free
|
||||
# multimodal model instead so vision/browser-vision still works.
|
||||
# models instead: mimo-v2-omni for vision, mimo-v2-pro for text tasks.
|
||||
try:
|
||||
from hermes_cli.models import check_nous_free_tier
|
||||
if check_nous_free_tier():
|
||||
model = _NOUS_FREE_TIER_VISION_MODEL
|
||||
logger.debug("Free-tier Nous account — using %s for auxiliary/vision", model)
|
||||
model = _NOUS_FREE_TIER_VISION_MODEL if vision else _NOUS_FREE_TIER_AUX_MODEL
|
||||
logger.debug("Free-tier Nous account — using %s for auxiliary/%s",
|
||||
model, "vision" if vision else "text")
|
||||
except Exception:
|
||||
pass
|
||||
return (
|
||||
@@ -776,7 +834,7 @@ def _read_main_provider() -> str:
|
||||
if isinstance(model_cfg, dict):
|
||||
provider = model_cfg.get("provider", "")
|
||||
if isinstance(provider, str) and provider.strip():
|
||||
return provider.strip().lower()
|
||||
return _normalize_aux_provider(provider)
|
||||
except Exception:
|
||||
pass
|
||||
return ""
|
||||
@@ -1138,17 +1196,7 @@ def resolve_provider_client(
|
||||
(client, resolved_model) or (None, None) if auth is unavailable.
|
||||
"""
|
||||
# Normalise aliases
|
||||
provider = (provider or "auto").strip().lower()
|
||||
if provider == "codex":
|
||||
provider = "openai-codex"
|
||||
if provider == "main":
|
||||
# Resolve to the user's actual main provider so named custom providers
|
||||
# and non-aggregator providers (DeepSeek, Alibaba, etc.) work correctly.
|
||||
main_prov = _read_main_provider()
|
||||
if main_prov and main_prov not in ("auto", "main", ""):
|
||||
provider = main_prov
|
||||
else:
|
||||
provider = "custom"
|
||||
provider = _normalize_aux_provider(provider)
|
||||
|
||||
# ── Auto: try all providers in priority order ────────────────────
|
||||
if provider == "auto":
|
||||
@@ -1298,7 +1346,9 @@ def resolve_provider_client(
|
||||
provider, ", ".join(tried_sources))
|
||||
return None, None
|
||||
|
||||
base_url = str(creds.get("base_url", "")).strip().rstrip("/") or pconfig.inference_base_url
|
||||
base_url = _to_openai_base_url(
|
||||
str(creds.get("base_url", "")).strip().rstrip("/") or pconfig.inference_base_url
|
||||
)
|
||||
|
||||
default_model = _API_KEY_PROVIDER_AUX_MODELS.get(provider, "")
|
||||
final_model = model or default_model
|
||||
@@ -1375,24 +1425,11 @@ def get_async_text_auxiliary_client(task: str = ""):
|
||||
_VISION_AUTO_PROVIDER_ORDER = (
|
||||
"openrouter",
|
||||
"nous",
|
||||
"openai-codex",
|
||||
"anthropic",
|
||||
"custom",
|
||||
)
|
||||
|
||||
|
||||
def _normalize_vision_provider(provider: Optional[str]) -> str:
|
||||
provider = (provider or "auto").strip().lower()
|
||||
if provider == "codex":
|
||||
return "openai-codex"
|
||||
if provider == "main":
|
||||
# Resolve to actual main provider — named custom providers and
|
||||
# non-aggregator providers need to pass through as their real name.
|
||||
main_prov = _read_main_provider()
|
||||
if main_prov and main_prov not in ("auto", "main", ""):
|
||||
return main_prov
|
||||
return "custom"
|
||||
return provider
|
||||
return _normalize_aux_provider(provider, for_vision=True)
|
||||
|
||||
|
||||
def _resolve_strict_vision_backend(provider: str) -> Tuple[Optional[Any], Optional[str]]:
|
||||
@@ -1400,7 +1437,7 @@ def _resolve_strict_vision_backend(provider: str) -> Tuple[Optional[Any], Option
|
||||
if provider == "openrouter":
|
||||
return _try_openrouter()
|
||||
if provider == "nous":
|
||||
return _try_nous()
|
||||
return _try_nous(vision=True)
|
||||
if provider == "openai-codex":
|
||||
return _try_codex()
|
||||
if provider == "anthropic":
|
||||
@@ -1433,17 +1470,20 @@ def _preferred_main_vision_provider() -> Optional[str]:
|
||||
def get_available_vision_backends() -> List[str]:
|
||||
"""Return the currently available vision backends in auto-selection order.
|
||||
|
||||
This is the single source of truth for setup, tool gating, and runtime
|
||||
auto-routing of vision tasks. The selected main provider is preferred when
|
||||
it is also a known-good vision backend; otherwise Hermes falls back through
|
||||
the standard conservative order.
|
||||
Order: OpenRouter → Nous → active provider. This is the single source
|
||||
of truth for setup, tool gating, and runtime auto-routing of vision tasks.
|
||||
"""
|
||||
ordered = list(_VISION_AUTO_PROVIDER_ORDER)
|
||||
preferred = _preferred_main_vision_provider()
|
||||
if preferred in ordered:
|
||||
ordered.remove(preferred)
|
||||
ordered.insert(0, preferred)
|
||||
return [provider for provider in ordered if _strict_vision_backend_available(provider)]
|
||||
available = [p for p in _VISION_AUTO_PROVIDER_ORDER
|
||||
if _strict_vision_backend_available(p)]
|
||||
# Also check the user's active provider (may be DeepSeek, Alibaba, named
|
||||
# custom, etc.) — resolve_provider_client handles all provider types.
|
||||
main_provider = _read_main_provider()
|
||||
if (main_provider and main_provider not in ("auto", "")
|
||||
and main_provider not in available):
|
||||
client, _ = resolve_provider_client(main_provider, _read_main_model())
|
||||
if client is not None:
|
||||
available.append(main_provider)
|
||||
return available
|
||||
|
||||
|
||||
def resolve_vision_provider_client(
|
||||
@@ -1488,16 +1528,30 @@ def resolve_vision_provider_client(
|
||||
return "custom", client, final_model
|
||||
|
||||
if requested == "auto":
|
||||
ordered = list(_VISION_AUTO_PROVIDER_ORDER)
|
||||
preferred = _preferred_main_vision_provider()
|
||||
if preferred in ordered:
|
||||
ordered.remove(preferred)
|
||||
ordered.insert(0, preferred)
|
||||
|
||||
for candidate in ordered:
|
||||
# Vision auto-detection order:
|
||||
# 1. OpenRouter (known vision-capable default model)
|
||||
# 2. Nous Portal (known vision-capable default model)
|
||||
# 3. Active provider + model (user's main chat config)
|
||||
# 4. Stop
|
||||
for candidate in _VISION_AUTO_PROVIDER_ORDER:
|
||||
sync_client, default_model = _resolve_strict_vision_backend(candidate)
|
||||
if sync_client is not None:
|
||||
return _finalize(candidate, sync_client, default_model)
|
||||
|
||||
# Fall back to the user's active provider + model.
|
||||
main_provider = _read_main_provider()
|
||||
main_model = _read_main_model()
|
||||
if main_provider and main_provider not in ("auto", ""):
|
||||
sync_client, resolved_model = resolve_provider_client(
|
||||
main_provider, main_model)
|
||||
if sync_client is not None:
|
||||
logger.info(
|
||||
"Vision auto-detect: using active provider %s (%s)",
|
||||
main_provider, resolved_model or main_model,
|
||||
)
|
||||
return _finalize(
|
||||
main_provider, sync_client, resolved_model or main_model)
|
||||
|
||||
logger.debug("Auxiliary vision client: none available")
|
||||
return None, None, None
|
||||
|
||||
|
||||
+63
-3
@@ -113,8 +113,15 @@ DEFAULT_CONTEXT_LENGTHS = {
|
||||
"llama": 131072,
|
||||
# Qwen
|
||||
"qwen": 131072,
|
||||
# MiniMax
|
||||
"minimax": 204800,
|
||||
# MiniMax (lowercase — lookup lowercases model names at line 973)
|
||||
"minimax-m1-256k": 1000000,
|
||||
"minimax-m1-128k": 1000000,
|
||||
"minimax-m1-80k": 1000000,
|
||||
"minimax-m1-40k": 1000000,
|
||||
"minimax-m1": 1000000,
|
||||
"minimax-m2.5": 1048576,
|
||||
"minimax-m2.7": 1048576,
|
||||
"minimax": 1048576,
|
||||
# GLM
|
||||
"glm": 202752,
|
||||
# Kimi
|
||||
@@ -127,7 +134,7 @@ DEFAULT_CONTEXT_LENGTHS = {
|
||||
"deepseek-ai/DeepSeek-V3.2": 65536,
|
||||
"moonshotai/Kimi-K2.5": 262144,
|
||||
"moonshotai/Kimi-K2-Thinking": 262144,
|
||||
"MiniMaxAI/MiniMax-M2.5": 204800,
|
||||
"minimaxai/minimax-m2.5": 1048576,
|
||||
"XiaomiMiMo/MiMo-V2-Flash": 32768,
|
||||
"mimo-v2-pro": 1048576,
|
||||
"mimo-v2-omni": 1048576,
|
||||
@@ -611,6 +618,59 @@ def _model_id_matches(candidate_id: str, lookup_model: str) -> bool:
|
||||
return False
|
||||
|
||||
|
||||
def query_ollama_num_ctx(model: str, base_url: str) -> Optional[int]:
|
||||
"""Query an Ollama server for the model's context length.
|
||||
|
||||
Returns the model's maximum context from GGUF metadata via ``/api/show``,
|
||||
or the explicit ``num_ctx`` from the Modelfile if set. Returns None if
|
||||
the server is unreachable or not Ollama.
|
||||
|
||||
This is the value that should be passed as ``num_ctx`` in Ollama chat
|
||||
requests to override the default 2048.
|
||||
"""
|
||||
import httpx
|
||||
|
||||
bare_model = _strip_provider_prefix(model)
|
||||
server_url = base_url.rstrip("/")
|
||||
if server_url.endswith("/v1"):
|
||||
server_url = server_url[:-3]
|
||||
|
||||
try:
|
||||
server_type = detect_local_server_type(base_url)
|
||||
except Exception:
|
||||
return None
|
||||
if server_type != "ollama":
|
||||
return None
|
||||
|
||||
try:
|
||||
with httpx.Client(timeout=3.0) as client:
|
||||
resp = client.post(f"{server_url}/api/show", json={"name": bare_model})
|
||||
if resp.status_code != 200:
|
||||
return None
|
||||
data = resp.json()
|
||||
|
||||
# Prefer explicit num_ctx from Modelfile parameters (user override)
|
||||
params = data.get("parameters", "")
|
||||
if "num_ctx" in params:
|
||||
for line in params.split("\n"):
|
||||
if "num_ctx" in line:
|
||||
parts = line.strip().split()
|
||||
if len(parts) >= 2:
|
||||
try:
|
||||
return int(parts[-1])
|
||||
except ValueError:
|
||||
pass
|
||||
|
||||
# Fall back to GGUF model_info context_length (training max)
|
||||
model_info = data.get("model_info", {})
|
||||
for key, value in model_info.items():
|
||||
if "context_length" in key and isinstance(value, (int, float)):
|
||||
return int(value)
|
||||
except Exception:
|
||||
pass
|
||||
return None
|
||||
|
||||
|
||||
def _query_local_context_length(model: str, base_url: str) -> Optional[int]:
|
||||
"""Query a local server for the model's context length."""
|
||||
import httpx
|
||||
|
||||
@@ -204,6 +204,30 @@ OPENAI_MODEL_EXECUTION_GUIDANCE = (
|
||||
"the result.\n"
|
||||
"</tool_persistence>\n"
|
||||
"\n"
|
||||
"<mandatory_tool_use>\n"
|
||||
"NEVER answer these from memory or mental computation — ALWAYS use a tool:\n"
|
||||
"- Arithmetic, math, calculations → use terminal or execute_code\n"
|
||||
"- Hashes, encodings, checksums → use terminal (e.g. sha256sum, base64)\n"
|
||||
"- Current time, date, timezone → use terminal (e.g. date)\n"
|
||||
"- System state: OS, CPU, memory, disk, ports, processes → use terminal\n"
|
||||
"- File contents, sizes, line counts → use read_file, search_files, or terminal\n"
|
||||
"- Git history, branches, diffs → use terminal\n"
|
||||
"- Current facts (weather, news, versions) → use web_search\n"
|
||||
"Your memory and user profile describe the USER, not the system you are "
|
||||
"running on. The execution environment may differ from what the user profile "
|
||||
"says about their personal setup.\n"
|
||||
"</mandatory_tool_use>\n"
|
||||
"\n"
|
||||
"<act_dont_ask>\n"
|
||||
"When a question has an obvious default interpretation, act on it immediately "
|
||||
"instead of asking for clarification. Examples:\n"
|
||||
"- 'Is port 443 open?' → check THIS machine (don't ask 'open where?')\n"
|
||||
"- 'What OS am I running?' → check the live system (don't use user profile)\n"
|
||||
"- 'What time is it?' → run `date` (don't guess)\n"
|
||||
"Only ask for clarification when the ambiguity genuinely changes what tool "
|
||||
"you would call.\n"
|
||||
"</act_dont_ask>\n"
|
||||
"\n"
|
||||
"<prerequisite_checks>\n"
|
||||
"- Before taking an action, check whether prerequisite discovery, lookup, or "
|
||||
"context-gathering steps are needed.\n"
|
||||
|
||||
@@ -0,0 +1,57 @@
|
||||
"""Retry utilities — jittered backoff for decorrelated retries.
|
||||
|
||||
Replaces fixed exponential backoff with jittered delays to prevent
|
||||
thundering-herd retry spikes when multiple sessions hit the same
|
||||
rate-limited provider concurrently.
|
||||
"""
|
||||
|
||||
import random
|
||||
import threading
|
||||
import time
|
||||
|
||||
# Monotonic counter for jitter seed uniqueness within the same process.
|
||||
# Protected by a lock to avoid race conditions in concurrent retry paths
|
||||
# (e.g. multiple gateway sessions retrying simultaneously).
|
||||
_jitter_counter = 0
|
||||
_jitter_lock = threading.Lock()
|
||||
|
||||
|
||||
def jittered_backoff(
|
||||
attempt: int,
|
||||
*,
|
||||
base_delay: float = 5.0,
|
||||
max_delay: float = 120.0,
|
||||
jitter_ratio: float = 0.5,
|
||||
) -> float:
|
||||
"""Compute a jittered exponential backoff delay.
|
||||
|
||||
Args:
|
||||
attempt: 1-based retry attempt number.
|
||||
base_delay: Base delay in seconds for attempt 1.
|
||||
max_delay: Maximum delay cap in seconds.
|
||||
jitter_ratio: Fraction of computed delay to use as random jitter
|
||||
range. 0.5 means jitter is uniform in [0, 0.5 * delay].
|
||||
|
||||
Returns:
|
||||
Delay in seconds: min(base * 2^(attempt-1), max_delay) + jitter.
|
||||
|
||||
The jitter decorrelates concurrent retries so multiple sessions
|
||||
hitting the same provider don't all retry at the same instant.
|
||||
"""
|
||||
global _jitter_counter
|
||||
with _jitter_lock:
|
||||
_jitter_counter += 1
|
||||
tick = _jitter_counter
|
||||
|
||||
exponent = max(0, attempt - 1)
|
||||
if exponent >= 63 or base_delay <= 0:
|
||||
delay = max_delay
|
||||
else:
|
||||
delay = min(base_delay * (2 ** exponent), max_delay)
|
||||
|
||||
# Seed from time + counter for decorrelation even with coarse clocks.
|
||||
seed = (time.time_ns() ^ (tick * 0x9E3779B9)) & 0xFFFFFFFF
|
||||
rng = random.Random(seed)
|
||||
jitter = rng.uniform(0, jitter_ratio * delay)
|
||||
|
||||
return delay + jitter
|
||||
@@ -612,6 +612,11 @@ def _run_cleanup():
|
||||
pass
|
||||
# Shut down memory provider (on_session_end + shutdown_all) at actual
|
||||
# session boundary — NOT per-turn inside run_conversation().
|
||||
try:
|
||||
from hermes_cli.plugins import invoke_hook as _invoke_hook
|
||||
_invoke_hook("on_session_finalize", session_id=_active_agent_ref.session_id if _active_agent_ref else None, platform="cli")
|
||||
except Exception:
|
||||
pass
|
||||
try:
|
||||
if _active_agent_ref and hasattr(_active_agent_ref, 'shutdown_memory_provider'):
|
||||
_active_agent_ref.shutdown_memory_provider(
|
||||
@@ -755,7 +760,10 @@ def _setup_worktree(repo_root: str = None) -> Optional[Dict[str, str]]:
|
||||
def _cleanup_worktree(info: Dict[str, str] = None) -> None:
|
||||
"""Remove a worktree and its branch on exit.
|
||||
|
||||
If the worktree has uncommitted changes, warn and keep it.
|
||||
Preserves the worktree only if it has unpushed commits (real work
|
||||
that hasn't been pushed to any remote). Uncommitted changes alone
|
||||
(untracked files, test artifacts) are not enough to keep it — agent
|
||||
work lives in commits/PRs, not the working tree.
|
||||
"""
|
||||
global _active_worktree
|
||||
info = info or _active_worktree
|
||||
@@ -771,23 +779,27 @@ def _cleanup_worktree(info: Dict[str, str] = None) -> None:
|
||||
if not Path(wt_path).exists():
|
||||
return
|
||||
|
||||
# Check for uncommitted changes
|
||||
# Check for unpushed commits — commits reachable from HEAD but not
|
||||
# from any remote branch. These represent real work the agent did
|
||||
# but didn't push.
|
||||
has_unpushed = False
|
||||
try:
|
||||
status = subprocess.run(
|
||||
["git", "status", "--porcelain"],
|
||||
result = subprocess.run(
|
||||
["git", "log", "--oneline", "HEAD", "--not", "--remotes"],
|
||||
capture_output=True, text=True, timeout=10, cwd=wt_path,
|
||||
)
|
||||
has_changes = bool(status.stdout.strip())
|
||||
has_unpushed = bool(result.stdout.strip())
|
||||
except Exception:
|
||||
has_changes = True # Assume dirty on error — don't delete
|
||||
has_unpushed = True # Assume unpushed on error — don't delete
|
||||
|
||||
if has_changes:
|
||||
print(f"\n\033[33m⚠ Worktree has uncommitted changes, keeping: {wt_path}\033[0m")
|
||||
print(f" To clean up manually: git worktree remove {wt_path}")
|
||||
if has_unpushed:
|
||||
print(f"\n\033[33m⚠ Worktree has unpushed commits, keeping: {wt_path}\033[0m")
|
||||
print(f" To clean up manually: git worktree remove --force {wt_path}")
|
||||
_active_worktree = None
|
||||
return
|
||||
|
||||
# Remove worktree
|
||||
# Remove worktree (even if working tree is dirty — uncommitted
|
||||
# changes without unpushed commits are just artifacts)
|
||||
try:
|
||||
subprocess.run(
|
||||
["git", "worktree", "remove", wt_path, "--force"],
|
||||
@@ -796,7 +808,7 @@ def _cleanup_worktree(info: Dict[str, str] = None) -> None:
|
||||
except Exception as e:
|
||||
logger.debug("Failed to remove worktree: %s", e)
|
||||
|
||||
# Delete the branch (only if it was never pushed / has no upstream)
|
||||
# Delete the branch
|
||||
try:
|
||||
subprocess.run(
|
||||
["git", "branch", "-D", branch],
|
||||
@@ -810,19 +822,27 @@ def _cleanup_worktree(info: Dict[str, str] = None) -> None:
|
||||
|
||||
|
||||
def _prune_stale_worktrees(repo_root: str, max_age_hours: int = 24) -> None:
|
||||
"""Remove worktrees older than max_age_hours that have no uncommitted changes.
|
||||
"""Remove stale worktrees and orphaned branches on startup.
|
||||
|
||||
Runs silently on startup to clean up after crashed/killed sessions.
|
||||
Age-based tiers:
|
||||
- Under max_age_hours (24h): skip — session may still be active.
|
||||
- 24h–72h: remove if no unpushed commits.
|
||||
- Over 72h: force remove regardless (nothing should sit this long).
|
||||
|
||||
Also prunes orphaned ``hermes/*`` and ``pr-*`` local branches that
|
||||
have no corresponding worktree.
|
||||
"""
|
||||
import subprocess
|
||||
import time
|
||||
|
||||
worktrees_dir = Path(repo_root) / ".worktrees"
|
||||
if not worktrees_dir.exists():
|
||||
_prune_orphaned_branches(repo_root)
|
||||
return
|
||||
|
||||
now = time.time()
|
||||
cutoff = now - (max_age_hours * 3600)
|
||||
soft_cutoff = now - (max_age_hours * 3600) # 24h default
|
||||
hard_cutoff = now - (max_age_hours * 3 * 3600) # 72h default
|
||||
|
||||
for entry in worktrees_dir.iterdir():
|
||||
if not entry.is_dir() or not entry.name.startswith("hermes-"):
|
||||
@@ -831,21 +851,24 @@ def _prune_stale_worktrees(repo_root: str, max_age_hours: int = 24) -> None:
|
||||
# Check age
|
||||
try:
|
||||
mtime = entry.stat().st_mtime
|
||||
if mtime > cutoff:
|
||||
if mtime > soft_cutoff:
|
||||
continue # Too recent — skip
|
||||
except Exception:
|
||||
continue
|
||||
|
||||
# Check for uncommitted changes
|
||||
try:
|
||||
status = subprocess.run(
|
||||
["git", "status", "--porcelain"],
|
||||
capture_output=True, text=True, timeout=5, cwd=str(entry),
|
||||
)
|
||||
if status.stdout.strip():
|
||||
continue # Has changes — skip
|
||||
except Exception:
|
||||
continue # Can't check — skip
|
||||
force = mtime <= hard_cutoff # Over 72h — force remove
|
||||
|
||||
if not force:
|
||||
# 24h–72h tier: only remove if no unpushed commits
|
||||
try:
|
||||
result = subprocess.run(
|
||||
["git", "log", "--oneline", "HEAD", "--not", "--remotes"],
|
||||
capture_output=True, text=True, timeout=5, cwd=str(entry),
|
||||
)
|
||||
if result.stdout.strip():
|
||||
continue # Has unpushed commits — skip
|
||||
except Exception:
|
||||
continue # Can't check — skip
|
||||
|
||||
# Safe to remove
|
||||
try:
|
||||
@@ -864,10 +887,81 @@ def _prune_stale_worktrees(repo_root: str, max_age_hours: int = 24) -> None:
|
||||
["git", "branch", "-D", branch],
|
||||
capture_output=True, text=True, timeout=10, cwd=repo_root,
|
||||
)
|
||||
logger.debug("Pruned stale worktree: %s", entry.name)
|
||||
logger.debug("Pruned stale worktree: %s (force=%s)", entry.name, force)
|
||||
except Exception as e:
|
||||
logger.debug("Failed to prune worktree %s: %s", entry.name, e)
|
||||
|
||||
_prune_orphaned_branches(repo_root)
|
||||
|
||||
|
||||
def _prune_orphaned_branches(repo_root: str) -> None:
|
||||
"""Delete local ``hermes/hermes-*`` and ``pr-*`` branches with no worktree.
|
||||
|
||||
These are auto-generated by ``hermes -w`` sessions and PR review
|
||||
workflows respectively. Once their worktree is gone they serve no
|
||||
purpose and just accumulate.
|
||||
"""
|
||||
import subprocess
|
||||
|
||||
try:
|
||||
result = subprocess.run(
|
||||
["git", "branch", "--format=%(refname:short)"],
|
||||
capture_output=True, text=True, timeout=10, cwd=repo_root,
|
||||
)
|
||||
if result.returncode != 0:
|
||||
return
|
||||
all_branches = [b.strip() for b in result.stdout.strip().split("\n") if b.strip()]
|
||||
except Exception:
|
||||
return
|
||||
|
||||
# Collect branches that are actively checked out in a worktree
|
||||
active_branches: set = set()
|
||||
try:
|
||||
wt_result = subprocess.run(
|
||||
["git", "worktree", "list", "--porcelain"],
|
||||
capture_output=True, text=True, timeout=10, cwd=repo_root,
|
||||
)
|
||||
for line in wt_result.stdout.split("\n"):
|
||||
if line.startswith("branch refs/heads/"):
|
||||
active_branches.add(line.split("branch refs/heads/", 1)[-1].strip())
|
||||
except Exception:
|
||||
return # Can't determine active branches — bail
|
||||
|
||||
# Also protect the currently checked-out branch and main
|
||||
try:
|
||||
head_result = subprocess.run(
|
||||
["git", "branch", "--show-current"],
|
||||
capture_output=True, text=True, timeout=5, cwd=repo_root,
|
||||
)
|
||||
current = head_result.stdout.strip()
|
||||
if current:
|
||||
active_branches.add(current)
|
||||
except Exception:
|
||||
pass
|
||||
active_branches.add("main")
|
||||
|
||||
orphaned = [
|
||||
b for b in all_branches
|
||||
if b not in active_branches
|
||||
and (b.startswith("hermes/hermes-") or b.startswith("pr-"))
|
||||
]
|
||||
|
||||
if not orphaned:
|
||||
return
|
||||
|
||||
# Delete in batches
|
||||
for i in range(0, len(orphaned), 50):
|
||||
batch = orphaned[i:i + 50]
|
||||
try:
|
||||
subprocess.run(
|
||||
["git", "branch", "-D"] + batch,
|
||||
capture_output=True, text=True, timeout=30, cwd=repo_root,
|
||||
)
|
||||
except Exception as e:
|
||||
logger.debug("Failed to prune orphaned branches: %s", e)
|
||||
|
||||
logger.debug("Pruned %d orphaned branches", len(orphaned))
|
||||
|
||||
# ============================================================================
|
||||
# ASCII Art & Branding
|
||||
# ============================================================================
|
||||
@@ -3314,6 +3408,22 @@ class HermesCLI:
|
||||
flush_tool_summary()
|
||||
print()
|
||||
|
||||
def _notify_session_boundary(self, event_type: str) -> None:
|
||||
"""Fire a session-boundary plugin hook (on_session_finalize or on_session_reset).
|
||||
|
||||
Non-blocking — errors are caught and logged. Safe to call from any
|
||||
lifecycle point (shutdown, /new, /reset).
|
||||
"""
|
||||
try:
|
||||
from hermes_cli.plugins import invoke_hook as _invoke_hook
|
||||
_invoke_hook(
|
||||
event_type,
|
||||
session_id=self.agent.session_id if self.agent else None,
|
||||
platform=getattr(self, "platform", None) or "cli",
|
||||
)
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
def new_session(self, silent=False):
|
||||
"""Start a fresh session with a new session ID and cleared agent state."""
|
||||
if self.agent and self.conversation_history:
|
||||
@@ -3321,6 +3431,10 @@ class HermesCLI:
|
||||
self.agent.flush_memories(self.conversation_history)
|
||||
except (Exception, KeyboardInterrupt):
|
||||
pass
|
||||
self._notify_session_boundary("on_session_finalize")
|
||||
elif self.agent:
|
||||
# First session or empty history — still finalize the old session
|
||||
self._notify_session_boundary("on_session_finalize")
|
||||
|
||||
old_session_id = self.session_id
|
||||
if self._session_db and old_session_id:
|
||||
@@ -3365,6 +3479,7 @@ class HermesCLI:
|
||||
)
|
||||
except Exception:
|
||||
pass
|
||||
self._notify_session_boundary("on_session_reset")
|
||||
|
||||
if not silent:
|
||||
print("(^_^)v New session started!")
|
||||
|
||||
+7
-1
@@ -574,12 +574,16 @@ def remove_job(job_id: str) -> bool:
|
||||
return False
|
||||
|
||||
|
||||
def mark_job_run(job_id: str, success: bool, error: Optional[str] = None):
|
||||
def mark_job_run(job_id: str, success: bool, error: Optional[str] = None,
|
||||
delivery_error: Optional[str] = None):
|
||||
"""
|
||||
Mark a job as having been run.
|
||||
|
||||
Updates last_run_at, last_status, increments completed count,
|
||||
computes next_run_at, and auto-deletes if repeat limit reached.
|
||||
|
||||
``delivery_error`` is tracked separately from the agent error — a job
|
||||
can succeed (agent produced output) but fail delivery (platform down).
|
||||
"""
|
||||
jobs = load_jobs()
|
||||
for i, job in enumerate(jobs):
|
||||
@@ -588,6 +592,8 @@ def mark_job_run(job_id: str, success: bool, error: Optional[str] = None):
|
||||
job["last_run_at"] = now
|
||||
job["last_status"] = "ok" if success else "error"
|
||||
job["last_error"] = error if not success else None
|
||||
# Track delivery failures separately — cleared on successful delivery
|
||||
job["last_delivery_error"] = delivery_error
|
||||
|
||||
# Increment completed count
|
||||
if job.get("repeat"):
|
||||
|
||||
+32
-25
@@ -196,7 +196,7 @@ def _send_media_via_adapter(adapter, chat_id: str, media_files: list, metadata:
|
||||
logger.warning("Job '%s': failed to send media %s: %s", job.get("id", "?"), media_path, e)
|
||||
|
||||
|
||||
def _deliver_result(job: dict, content: str, adapters=None, loop=None) -> None:
|
||||
def _deliver_result(job: dict, content: str, adapters=None, loop=None) -> Optional[str]:
|
||||
"""
|
||||
Deliver job output to the configured target (origin chat, specific platform, etc.).
|
||||
|
||||
@@ -204,16 +204,16 @@ def _deliver_result(job: dict, content: str, adapters=None, loop=None) -> None:
|
||||
use the live adapter first — this supports E2EE rooms (e.g. Matrix) where
|
||||
the standalone HTTP path cannot encrypt. Falls back to standalone send if
|
||||
the adapter path fails or is unavailable.
|
||||
|
||||
Returns None on success, or an error string on failure.
|
||||
"""
|
||||
target = _resolve_delivery_target(job)
|
||||
if not target:
|
||||
if job.get("deliver", "local") != "local":
|
||||
logger.warning(
|
||||
"Job '%s' deliver=%s but no concrete delivery target could be resolved",
|
||||
job["id"],
|
||||
job.get("deliver", "local"),
|
||||
)
|
||||
return
|
||||
msg = f"no delivery target resolved for deliver={job.get('deliver', 'local')}"
|
||||
logger.warning("Job '%s': %s", job["id"], msg)
|
||||
return msg
|
||||
return None # local-only jobs don't deliver — not a failure
|
||||
|
||||
platform_name = target["platform"]
|
||||
chat_id = target["chat_id"]
|
||||
@@ -239,19 +239,22 @@ def _deliver_result(job: dict, content: str, adapters=None, loop=None) -> None:
|
||||
}
|
||||
platform = platform_map.get(platform_name.lower())
|
||||
if not platform:
|
||||
logger.warning("Job '%s': unknown platform '%s' for delivery", job["id"], platform_name)
|
||||
return
|
||||
msg = f"unknown platform '{platform_name}'"
|
||||
logger.warning("Job '%s': %s", job["id"], msg)
|
||||
return msg
|
||||
|
||||
try:
|
||||
config = load_gateway_config()
|
||||
except Exception as e:
|
||||
logger.error("Job '%s': failed to load gateway config for delivery: %s", job["id"], e)
|
||||
return
|
||||
msg = f"failed to load gateway config: {e}"
|
||||
logger.error("Job '%s': %s", job["id"], msg)
|
||||
return msg
|
||||
|
||||
pconfig = config.platforms.get(platform)
|
||||
if not pconfig or not pconfig.enabled:
|
||||
logger.warning("Job '%s': platform '%s' not configured/enabled", job["id"], platform_name)
|
||||
return
|
||||
msg = f"platform '{platform_name}' not configured/enabled"
|
||||
logger.warning("Job '%s': %s", job["id"], msg)
|
||||
return msg
|
||||
|
||||
# Optionally wrap the content with a header/footer so the user knows this
|
||||
# is a cron delivery. Wrapping is on by default; set cron.wrap_response: false
|
||||
@@ -307,7 +310,7 @@ def _deliver_result(job: dict, content: str, adapters=None, loop=None) -> None:
|
||||
|
||||
if adapter_ok:
|
||||
logger.info("Job '%s': delivered to %s:%s via live adapter", job["id"], platform_name, chat_id)
|
||||
return
|
||||
return None
|
||||
except Exception as e:
|
||||
logger.warning(
|
||||
"Job '%s': live adapter delivery to %s:%s failed (%s), falling back to standalone",
|
||||
@@ -329,13 +332,17 @@ def _deliver_result(job: dict, content: str, adapters=None, loop=None) -> None:
|
||||
future = pool.submit(asyncio.run, _send_to_platform(platform, pconfig, chat_id, cleaned_delivery_content, thread_id=thread_id, media_files=media_files))
|
||||
result = future.result(timeout=30)
|
||||
except Exception as e:
|
||||
logger.error("Job '%s': delivery to %s:%s failed: %s", job["id"], platform_name, chat_id, e)
|
||||
return
|
||||
msg = f"delivery to {platform_name}:{chat_id} failed: {e}"
|
||||
logger.error("Job '%s': %s", job["id"], msg)
|
||||
return msg
|
||||
|
||||
if result and result.get("error"):
|
||||
logger.error("Job '%s': delivery error: %s", job["id"], result["error"])
|
||||
else:
|
||||
logger.info("Job '%s': delivered to %s:%s", job["id"], platform_name, chat_id)
|
||||
msg = f"delivery error: {result['error']}"
|
||||
logger.error("Job '%s': %s", job["id"], msg)
|
||||
return msg
|
||||
|
||||
logger.info("Job '%s': delivered to %s:%s", job["id"], platform_name, chat_id)
|
||||
return None
|
||||
|
||||
|
||||
_SCRIPT_TIMEOUT = 120 # seconds
|
||||
@@ -578,11 +585,9 @@ def run_job(job: dict) -> tuple[bool, str, str, Optional[str]]:
|
||||
except Exception as e:
|
||||
logger.warning("Job '%s': failed to load config.yaml, using defaults: %s", job_id, e)
|
||||
|
||||
# Reasoning config from env or config.yaml
|
||||
# Reasoning config from config.yaml
|
||||
from hermes_constants import parse_reasoning_effort
|
||||
effort = os.getenv("HERMES_REASONING_EFFORT", "")
|
||||
if not effort:
|
||||
effort = str(_cfg.get("agent", {}).get("reasoning_effort", "")).strip()
|
||||
effort = str(_cfg.get("agent", {}).get("reasoning_effort", "")).strip()
|
||||
reasoning_config = parse_reasoning_effort(effort)
|
||||
|
||||
# Prefill messages from env or config.yaml
|
||||
@@ -868,13 +873,15 @@ def tick(verbose: bool = True, adapters=None, loop=None) -> int:
|
||||
logger.info("Job '%s': agent returned %s — skipping delivery", job["id"], SILENT_MARKER)
|
||||
should_deliver = False
|
||||
|
||||
delivery_error = None
|
||||
if should_deliver:
|
||||
try:
|
||||
_deliver_result(job, deliver_content, adapters=adapters, loop=loop)
|
||||
delivery_error = _deliver_result(job, deliver_content, adapters=adapters, loop=loop)
|
||||
except Exception as de:
|
||||
delivery_error = str(de)
|
||||
logger.error("Delivery failed for job %s: %s", job["id"], de)
|
||||
|
||||
mark_job_run(job["id"], success, error)
|
||||
mark_job_run(job["id"], success, error, delivery_error=delivery_error)
|
||||
executed += 1
|
||||
|
||||
except Exception as e:
|
||||
|
||||
@@ -21,6 +21,8 @@ from dataclasses import dataclass, field
|
||||
from typing import Any, Dict, List, Optional, Set
|
||||
|
||||
from model_tools import handle_function_call
|
||||
from tools.terminal_tool import get_active_env
|
||||
from tools.tool_result_storage import maybe_persist_tool_result, enforce_turn_budget
|
||||
|
||||
# Thread pool for running sync tool calls that internally use asyncio.run()
|
||||
# (e.g., the Modal/Docker/Daytona terminal backends). Running them in a separate
|
||||
@@ -138,6 +140,7 @@ class HermesAgentLoop:
|
||||
temperature: float = 1.0,
|
||||
max_tokens: Optional[int] = None,
|
||||
extra_body: Optional[Dict[str, Any]] = None,
|
||||
budget_config: Optional["BudgetConfig"] = None,
|
||||
):
|
||||
"""
|
||||
Initialize the agent loop.
|
||||
@@ -154,7 +157,11 @@ class HermesAgentLoop:
|
||||
extra_body: Extra parameters passed to the OpenAI client's create() call.
|
||||
Used for OpenRouter provider preferences, transforms, etc.
|
||||
e.g. {"provider": {"ignore": ["DeepInfra"]}}
|
||||
budget_config: Tool result persistence budget. Controls per-tool
|
||||
thresholds, per-turn aggregate budget, and preview size.
|
||||
If None, uses DEFAULT_BUDGET (current hardcoded values).
|
||||
"""
|
||||
from tools.budget_config import DEFAULT_BUDGET
|
||||
self.server = server
|
||||
self.tool_schemas = tool_schemas
|
||||
self.valid_tool_names = valid_tool_names
|
||||
@@ -163,6 +170,7 @@ class HermesAgentLoop:
|
||||
self.temperature = temperature
|
||||
self.max_tokens = max_tokens
|
||||
self.extra_body = extra_body
|
||||
self.budget_config = budget_config or DEFAULT_BUDGET
|
||||
|
||||
async def run(self, messages: List[Dict[str, Any]]) -> AgentResult:
|
||||
"""
|
||||
@@ -446,8 +454,15 @@ class HermesAgentLoop:
|
||||
except (json.JSONDecodeError, TypeError):
|
||||
pass
|
||||
|
||||
# Add tool response to conversation
|
||||
tc_id = tc.get("id", "") if isinstance(tc, dict) else tc.id
|
||||
tool_result = maybe_persist_tool_result(
|
||||
content=tool_result,
|
||||
tool_name=tool_name,
|
||||
tool_use_id=tc_id,
|
||||
env=get_active_env(self.task_id),
|
||||
config=self.budget_config,
|
||||
)
|
||||
|
||||
messages.append(
|
||||
{
|
||||
"role": "tool",
|
||||
@@ -456,6 +471,14 @@ class HermesAgentLoop:
|
||||
}
|
||||
)
|
||||
|
||||
num_tcs = len(assistant_msg.tool_calls)
|
||||
if num_tcs > 0:
|
||||
enforce_turn_budget(
|
||||
messages[-num_tcs:],
|
||||
env=get_active_env(self.task_id),
|
||||
config=self.budget_config,
|
||||
)
|
||||
|
||||
turn_elapsed = _time.monotonic() - turn_start
|
||||
logger.info(
|
||||
"[%s] turn %d: api=%.1fs, %d tools, turn_total=%.1fs",
|
||||
|
||||
@@ -1048,6 +1048,7 @@ class AgenticOPDEnv(HermesAgentBaseEnv):
|
||||
temperature=0.0,
|
||||
max_tokens=self.config.max_token_length,
|
||||
extra_body=self.config.extra_body,
|
||||
budget_config=self.config.build_budget_config(),
|
||||
)
|
||||
result = await agent.run(messages)
|
||||
|
||||
|
||||
@@ -541,6 +541,7 @@ class TerminalBench2EvalEnv(HermesAgentBaseEnv):
|
||||
temperature=self.config.agent_temperature,
|
||||
max_tokens=self.config.max_token_length,
|
||||
extra_body=self.config.extra_body,
|
||||
budget_config=self.config.build_budget_config(),
|
||||
)
|
||||
result = await agent.run(messages)
|
||||
else:
|
||||
@@ -553,6 +554,7 @@ class TerminalBench2EvalEnv(HermesAgentBaseEnv):
|
||||
temperature=self.config.agent_temperature,
|
||||
max_tokens=self.config.max_token_length,
|
||||
extra_body=self.config.extra_body,
|
||||
budget_config=self.config.build_budget_config(),
|
||||
)
|
||||
result = await agent.run(messages)
|
||||
|
||||
|
||||
@@ -549,6 +549,7 @@ class YCBenchEvalEnv(HermesAgentBaseEnv):
|
||||
temperature=self.config.agent_temperature,
|
||||
max_tokens=self.config.max_token_length,
|
||||
extra_body=self.config.extra_body,
|
||||
budget_config=self.config.build_budget_config(),
|
||||
)
|
||||
result = await agent.run(messages)
|
||||
|
||||
|
||||
@@ -62,6 +62,11 @@ from atroposlib.type_definitions import Item
|
||||
|
||||
from environments.agent_loop import AgentResult, HermesAgentLoop
|
||||
from environments.tool_context import ToolContext
|
||||
from tools.budget_config import (
|
||||
DEFAULT_RESULT_SIZE_CHARS,
|
||||
DEFAULT_TURN_BUDGET_CHARS,
|
||||
DEFAULT_PREVIEW_SIZE_CHARS,
|
||||
)
|
||||
|
||||
# Import hermes-agent toolset infrastructure
|
||||
from model_tools import get_tool_definitions
|
||||
@@ -160,6 +165,32 @@ class HermesAgentEnvConfig(BaseEnvConfig):
|
||||
"Options: hermes, mistral, llama3_json, qwen, deepseek_v3, etc.",
|
||||
)
|
||||
|
||||
# --- Tool result budget ---
|
||||
# Defaults imported from tools.budget_config (single source of truth).
|
||||
default_result_size_chars: int = Field(
|
||||
default=DEFAULT_RESULT_SIZE_CHARS,
|
||||
description="Default per-tool threshold (chars) for persisting large results "
|
||||
"to sandbox. Results exceeding this are written to /tmp/hermes-results/ "
|
||||
"and replaced with a preview. Per-tool registry values take precedence "
|
||||
"unless overridden via tool_result_overrides.",
|
||||
)
|
||||
turn_budget_chars: int = Field(
|
||||
default=DEFAULT_TURN_BUDGET_CHARS,
|
||||
description="Aggregate char budget per assistant turn. If all tool results "
|
||||
"in a single turn exceed this, the largest are persisted to disk first.",
|
||||
)
|
||||
preview_size_chars: int = Field(
|
||||
default=DEFAULT_PREVIEW_SIZE_CHARS,
|
||||
description="Size of the inline preview shown after a tool result is persisted.",
|
||||
)
|
||||
tool_result_overrides: Optional[Dict[str, int]] = Field(
|
||||
default=None,
|
||||
description="Per-tool threshold overrides (chars). Keys are tool names, "
|
||||
"values are char thresholds. Overrides both the default and registry "
|
||||
"per-tool values. Example: {'terminal': 10000, 'search_files': 5000}. "
|
||||
"Note: read_file is pinned to infinity and cannot be overridden.",
|
||||
)
|
||||
|
||||
# --- Provider-specific parameters ---
|
||||
# Passed as extra_body to the OpenAI client's chat.completions.create() call.
|
||||
# Useful for OpenRouter provider preferences, transforms, route settings, etc.
|
||||
@@ -176,6 +207,16 @@ class HermesAgentEnvConfig(BaseEnvConfig):
|
||||
"transforms, and other provider-specific settings.",
|
||||
)
|
||||
|
||||
def build_budget_config(self):
|
||||
"""Build a BudgetConfig from env config fields."""
|
||||
from tools.budget_config import BudgetConfig
|
||||
return BudgetConfig(
|
||||
default_result_size=self.default_result_size_chars,
|
||||
turn_budget=self.turn_budget_chars,
|
||||
preview_size=self.preview_size_chars,
|
||||
tool_overrides=dict(self.tool_result_overrides) if self.tool_result_overrides else {},
|
||||
)
|
||||
|
||||
|
||||
class HermesAgentBaseEnv(BaseEnv):
|
||||
"""
|
||||
@@ -490,6 +531,7 @@ class HermesAgentBaseEnv(BaseEnv):
|
||||
temperature=self.config.agent_temperature,
|
||||
max_tokens=self.config.max_token_length,
|
||||
extra_body=self.config.extra_body,
|
||||
budget_config=self.config.build_budget_config(),
|
||||
)
|
||||
result = await agent.run(messages)
|
||||
except NotImplementedError:
|
||||
@@ -507,6 +549,7 @@ class HermesAgentBaseEnv(BaseEnv):
|
||||
temperature=self.config.agent_temperature,
|
||||
max_tokens=self.config.max_token_length,
|
||||
extra_body=self.config.extra_body,
|
||||
budget_config=self.config.build_budget_config(),
|
||||
)
|
||||
result = await agent.run(messages)
|
||||
else:
|
||||
@@ -520,6 +563,7 @@ class HermesAgentBaseEnv(BaseEnv):
|
||||
temperature=self.config.agent_temperature,
|
||||
max_tokens=self.config.max_token_length,
|
||||
extra_body=self.config.extra_body,
|
||||
budget_config=self.config.build_budget_config(),
|
||||
)
|
||||
result = await agent.run(messages)
|
||||
|
||||
|
||||
@@ -472,6 +472,7 @@ class WebResearchEnv(HermesAgentBaseEnv):
|
||||
temperature=0.0, # Deterministic for eval
|
||||
max_tokens=self.config.max_token_length,
|
||||
extra_body=self.config.extra_body,
|
||||
budget_config=self.config.build_budget_config(),
|
||||
)
|
||||
result = await agent.run(messages)
|
||||
|
||||
|
||||
@@ -20,6 +20,7 @@ from __future__ import annotations
|
||||
import asyncio
|
||||
import hashlib
|
||||
import hmac
|
||||
import itertools
|
||||
import json
|
||||
import logging
|
||||
import mimetypes
|
||||
@@ -1052,6 +1053,9 @@ class FeishuAdapter(BasePlatformAdapter):
|
||||
self._media_batch_state = FeishuBatchState()
|
||||
self._pending_media_batches = self._media_batch_state.events
|
||||
self._pending_media_batch_tasks = self._media_batch_state.tasks
|
||||
# Exec approval button state (approval_id → {session_key, message_id, chat_id})
|
||||
self._approval_state: Dict[int, Dict[str, str]] = {}
|
||||
self._approval_counter = itertools.count(1)
|
||||
self._load_seen_message_ids()
|
||||
|
||||
@staticmethod
|
||||
@@ -1394,6 +1398,104 @@ class FeishuAdapter(BasePlatformAdapter):
|
||||
logger.error("[Feishu] Failed to edit message %s: %s", message_id, exc, exc_info=True)
|
||||
return SendResult(success=False, error=str(exc))
|
||||
|
||||
async def send_exec_approval(
|
||||
self, chat_id: str, command: str, session_key: str,
|
||||
description: str = "dangerous command",
|
||||
metadata: Optional[Dict[str, Any]] = None,
|
||||
) -> SendResult:
|
||||
"""Send an interactive card with approval buttons.
|
||||
|
||||
The buttons carry ``hermes_action`` in their value dict so that
|
||||
``_handle_card_action_event`` can intercept them and call
|
||||
``resolve_gateway_approval()`` to unblock the waiting agent thread.
|
||||
"""
|
||||
if not self._client:
|
||||
return SendResult(success=False, error="Not connected")
|
||||
|
||||
try:
|
||||
approval_id = next(self._approval_counter)
|
||||
cmd_preview = command[:3000] + "..." if len(command) > 3000 else command
|
||||
|
||||
def _btn(label: str, action_name: str, btn_type: str = "default") -> dict:
|
||||
return {
|
||||
"tag": "button",
|
||||
"text": {"tag": "plain_text", "content": label},
|
||||
"type": btn_type,
|
||||
"value": {"hermes_action": action_name, "approval_id": approval_id},
|
||||
}
|
||||
|
||||
card = {
|
||||
"config": {"wide_screen_mode": True},
|
||||
"header": {
|
||||
"title": {"content": "⚠️ Command Approval Required", "tag": "plain_text"},
|
||||
"template": "orange",
|
||||
},
|
||||
"elements": [
|
||||
{
|
||||
"tag": "markdown",
|
||||
"content": f"```\n{cmd_preview}\n```\n**Reason:** {description}",
|
||||
},
|
||||
{
|
||||
"tag": "action",
|
||||
"actions": [
|
||||
_btn("✅ Allow Once", "approve_once", "primary"),
|
||||
_btn("✅ Session", "approve_session"),
|
||||
_btn("✅ Always", "approve_always"),
|
||||
_btn("❌ Deny", "deny", "danger"),
|
||||
],
|
||||
},
|
||||
],
|
||||
}
|
||||
|
||||
payload = json.dumps(card, ensure_ascii=False)
|
||||
response = await self._feishu_send_with_retry(
|
||||
chat_id=chat_id,
|
||||
msg_type="interactive",
|
||||
payload=payload,
|
||||
reply_to=None,
|
||||
metadata=metadata,
|
||||
)
|
||||
|
||||
result = self._finalize_send_result(response, "send_exec_approval failed")
|
||||
if result.success:
|
||||
self._approval_state[approval_id] = {
|
||||
"session_key": session_key,
|
||||
"message_id": result.message_id or "",
|
||||
"chat_id": chat_id,
|
||||
}
|
||||
return result
|
||||
except Exception as exc:
|
||||
logger.warning("[Feishu] send_exec_approval failed: %s", exc)
|
||||
return SendResult(success=False, error=str(exc))
|
||||
|
||||
async def _update_approval_card(
|
||||
self, message_id: str, label: str, user_name: str, choice: str,
|
||||
) -> None:
|
||||
"""Replace the approval card with a resolved status card."""
|
||||
if not self._client or not message_id:
|
||||
return
|
||||
icon = "❌" if choice == "deny" else "✅"
|
||||
card = {
|
||||
"config": {"wide_screen_mode": True},
|
||||
"header": {
|
||||
"title": {"content": f"{icon} {label}", "tag": "plain_text"},
|
||||
"template": "red" if choice == "deny" else "green",
|
||||
},
|
||||
"elements": [
|
||||
{
|
||||
"tag": "markdown",
|
||||
"content": f"{icon} **{label}** by {user_name}",
|
||||
},
|
||||
],
|
||||
}
|
||||
try:
|
||||
payload = json.dumps(card, ensure_ascii=False)
|
||||
body = self._build_update_message_body(msg_type="interactive", content=payload)
|
||||
request = self._build_update_message_request(message_id=message_id, request_body=body)
|
||||
await asyncio.to_thread(self._client.im.v1.message.update, request)
|
||||
except Exception as exc:
|
||||
logger.warning("[Feishu] Failed to update approval card %s: %s", message_id, exc)
|
||||
|
||||
async def send_voice(
|
||||
self,
|
||||
chat_id: str,
|
||||
@@ -1820,6 +1922,52 @@ class FeishuAdapter(BasePlatformAdapter):
|
||||
action = getattr(event, "action", None)
|
||||
action_tag = str(getattr(action, "tag", "") or "button")
|
||||
action_value = getattr(action, "value", {}) or {}
|
||||
|
||||
# --- Exec approval button intercept ---
|
||||
hermes_action = action_value.get("hermes_action") if isinstance(action_value, dict) else None
|
||||
if hermes_action:
|
||||
approval_id = action_value.get("approval_id")
|
||||
state = self._approval_state.pop(approval_id, None)
|
||||
if not state:
|
||||
logger.debug("[Feishu] Approval %s already resolved or unknown", approval_id)
|
||||
return
|
||||
|
||||
choice_map = {
|
||||
"approve_once": "once",
|
||||
"approve_session": "session",
|
||||
"approve_always": "always",
|
||||
"deny": "deny",
|
||||
}
|
||||
choice = choice_map.get(hermes_action, "deny")
|
||||
|
||||
label_map = {
|
||||
"once": "Approved once",
|
||||
"session": "Approved for session",
|
||||
"always": "Approved permanently",
|
||||
"deny": "Denied",
|
||||
}
|
||||
label = label_map.get(choice, "Resolved")
|
||||
|
||||
# Resolve sender name for the status card
|
||||
sender_id = SimpleNamespace(open_id=open_id, user_id=None, union_id=None)
|
||||
sender_profile = await self._resolve_sender_profile(sender_id)
|
||||
user_name = sender_profile.get("user_name") or open_id
|
||||
|
||||
# Resolve the approval — unblocks the agent thread
|
||||
try:
|
||||
from tools.approval import resolve_gateway_approval
|
||||
count = resolve_gateway_approval(state["session_key"], choice)
|
||||
logger.info(
|
||||
"Feishu button resolved %d approval(s) for session %s (choice=%s, user=%s)",
|
||||
count, state["session_key"], choice, user_name,
|
||||
)
|
||||
except Exception as exc:
|
||||
logger.error("Failed to resolve gateway approval from Feishu button: %s", exc)
|
||||
|
||||
# Update the card to show the decision
|
||||
await self._update_approval_card(state.get("message_id", ""), label, user_name, choice)
|
||||
return
|
||||
|
||||
synthetic_text = f"/card {action_tag}"
|
||||
if action_value:
|
||||
try:
|
||||
|
||||
+32
-9
@@ -921,12 +921,11 @@ class GatewayRunner:
|
||||
|
||||
@staticmethod
|
||||
def _load_reasoning_config() -> dict | None:
|
||||
"""Load reasoning effort from config with env fallback.
|
||||
"""Load reasoning effort from config.yaml.
|
||||
|
||||
Checks agent.reasoning_effort in config.yaml first, then
|
||||
HERMES_REASONING_EFFORT as a fallback. Valid: "xhigh", "high",
|
||||
"medium", "low", "minimal", "none". Returns None to use default
|
||||
(medium).
|
||||
Reads agent.reasoning_effort from config.yaml. Valid: "xhigh",
|
||||
"high", "medium", "low", "minimal", "none". Returns None to use
|
||||
default (medium).
|
||||
"""
|
||||
from hermes_constants import parse_reasoning_effort
|
||||
effort = ""
|
||||
@@ -939,8 +938,6 @@ class GatewayRunner:
|
||||
effort = str(cfg.get("agent", {}).get("reasoning_effort", "") or "").strip()
|
||||
except Exception:
|
||||
pass
|
||||
if not effort:
|
||||
effort = os.getenv("HERMES_REASONING_EFFORT", "")
|
||||
result = parse_reasoning_effort(effort)
|
||||
if effort and effort.strip() and result is None:
|
||||
logger.warning("Unknown reasoning_effort '%s', using default (medium)", effort)
|
||||
@@ -1484,6 +1481,14 @@ class GatewayRunner:
|
||||
logger.debug("Interrupted running agent for session %s during shutdown", session_key[:20])
|
||||
except Exception as e:
|
||||
logger.debug("Failed interrupting agent during shutdown: %s", e)
|
||||
# Fire plugin on_session_finalize hook before memory shutdown
|
||||
try:
|
||||
from hermes_cli.plugins import invoke_hook as _invoke_hook
|
||||
_invoke_hook("on_session_finalize",
|
||||
session_id=getattr(agent, 'session_id', None),
|
||||
platform="gateway")
|
||||
except Exception:
|
||||
pass
|
||||
# Shut down memory provider at actual session boundary
|
||||
try:
|
||||
if hasattr(agent, 'shutdown_memory_provider'):
|
||||
@@ -3277,6 +3282,15 @@ class GatewayRunner:
|
||||
# the configured default instead of the previously switched model.
|
||||
self._session_model_overrides.pop(session_key, None)
|
||||
|
||||
# Fire plugin on_session_finalize hook (session boundary)
|
||||
try:
|
||||
from hermes_cli.plugins import invoke_hook as _invoke_hook
|
||||
_old_sid = old_entry.session_id if old_entry else None
|
||||
_invoke_hook("on_session_finalize", session_id=_old_sid,
|
||||
platform=source.platform.value if source.platform else "")
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
# Emit session:end hook (session is ending)
|
||||
await self.hooks.emit("session:end", {
|
||||
"platform": source.platform.value if source.platform else "",
|
||||
@@ -3290,7 +3304,7 @@ class GatewayRunner:
|
||||
"user_id": source.user_id,
|
||||
"session_key": session_key,
|
||||
})
|
||||
|
||||
|
||||
# Resolve session config info to surface to the user
|
||||
try:
|
||||
session_info = self._format_session_info()
|
||||
@@ -3301,9 +3315,18 @@ class GatewayRunner:
|
||||
header = "✨ Session reset! Starting fresh."
|
||||
else:
|
||||
# No existing session, just create one
|
||||
self.session_store.get_or_create_session(source, force_new=True)
|
||||
new_entry = self.session_store.get_or_create_session(source, force_new=True)
|
||||
header = "✨ New session started!"
|
||||
|
||||
# Fire plugin on_session_reset hook (new session guaranteed to exist)
|
||||
try:
|
||||
from hermes_cli.plugins import invoke_hook as _invoke_hook
|
||||
_new_sid = new_entry.session_id if new_entry else None
|
||||
_invoke_hook("on_session_reset", session_id=_new_sid,
|
||||
platform=source.platform.value if source.platform else "")
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
if session_info:
|
||||
return f"{header}\n\n{session_info}"
|
||||
return header
|
||||
|
||||
+108
-7
@@ -74,6 +74,8 @@ class GatewayStreamConsumer:
|
||||
self._edit_supported = True # Disabled on first edit failure (Signal/Email/HA)
|
||||
self._last_edit_time = 0.0
|
||||
self._last_sent_text = "" # Track last-sent text to skip redundant edits
|
||||
self._fallback_final_send = False
|
||||
self._fallback_prefix = ""
|
||||
|
||||
@property
|
||||
def already_sent(self) -> bool:
|
||||
@@ -138,12 +140,19 @@ class GatewayStreamConsumer:
|
||||
while (
|
||||
len(self._accumulated) > _safe_limit
|
||||
and self._message_id is not None
|
||||
and self._edit_supported
|
||||
):
|
||||
split_at = self._accumulated.rfind("\n", 0, _safe_limit)
|
||||
if split_at < _safe_limit // 2:
|
||||
split_at = _safe_limit
|
||||
chunk = self._accumulated[:split_at]
|
||||
await self._send_or_edit(chunk)
|
||||
if self._fallback_final_send:
|
||||
# Edit failed while attempting to split an oversized
|
||||
# message. Keep the full accumulated text intact so
|
||||
# the fallback final-send path can deliver the
|
||||
# remaining continuation without dropping content.
|
||||
break
|
||||
self._accumulated = self._accumulated[split_at:].lstrip("\n")
|
||||
self._message_id = None
|
||||
self._last_sent_text = ""
|
||||
@@ -156,9 +165,17 @@ class GatewayStreamConsumer:
|
||||
self._last_edit_time = time.monotonic()
|
||||
|
||||
if got_done:
|
||||
# Final edit without cursor
|
||||
if self._accumulated and self._message_id:
|
||||
await self._send_or_edit(self._accumulated)
|
||||
# Final edit without cursor. If progressive editing failed
|
||||
# mid-stream, send a single continuation/fallback message
|
||||
# here instead of letting the base gateway path send the
|
||||
# full response again.
|
||||
if self._accumulated:
|
||||
if self._fallback_final_send:
|
||||
await self._send_fallback_final(self._accumulated)
|
||||
elif self._message_id:
|
||||
await self._send_or_edit(self._accumulated)
|
||||
elif not self._already_sent:
|
||||
await self._send_or_edit(self._accumulated)
|
||||
return
|
||||
|
||||
# Tool boundary: the should_edit block above already flushed
|
||||
@@ -169,6 +186,8 @@ class GatewayStreamConsumer:
|
||||
self._message_id = None
|
||||
self._accumulated = ""
|
||||
self._last_sent_text = ""
|
||||
self._fallback_final_send = False
|
||||
self._fallback_prefix = ""
|
||||
|
||||
await asyncio.sleep(0.05) # Small yield to not busy-loop
|
||||
|
||||
@@ -207,6 +226,86 @@ class GatewayStreamConsumer:
|
||||
# Strip trailing whitespace/newlines but preserve leading content
|
||||
return cleaned.rstrip()
|
||||
|
||||
def _visible_prefix(self) -> str:
|
||||
"""Return the visible text already shown in the streamed message."""
|
||||
prefix = self._last_sent_text or ""
|
||||
if self.cfg.cursor and prefix.endswith(self.cfg.cursor):
|
||||
prefix = prefix[:-len(self.cfg.cursor)]
|
||||
return self._clean_for_display(prefix)
|
||||
|
||||
def _continuation_text(self, final_text: str) -> str:
|
||||
"""Return only the part of final_text the user has not already seen."""
|
||||
prefix = self._fallback_prefix or self._visible_prefix()
|
||||
if prefix and final_text.startswith(prefix):
|
||||
return final_text[len(prefix):].lstrip()
|
||||
return final_text
|
||||
|
||||
@staticmethod
|
||||
def _split_text_chunks(text: str, limit: int) -> list[str]:
|
||||
"""Split text into reasonably sized chunks for fallback sends."""
|
||||
if len(text) <= limit:
|
||||
return [text]
|
||||
chunks: list[str] = []
|
||||
remaining = text
|
||||
while len(remaining) > limit:
|
||||
split_at = remaining.rfind("\n", 0, limit)
|
||||
if split_at < limit // 2:
|
||||
split_at = limit
|
||||
chunks.append(remaining[:split_at])
|
||||
remaining = remaining[split_at:].lstrip("\n")
|
||||
if remaining:
|
||||
chunks.append(remaining)
|
||||
return chunks
|
||||
|
||||
async def _send_fallback_final(self, text: str) -> None:
|
||||
"""Send the final continuation after streaming edits stop working."""
|
||||
final_text = self._clean_for_display(text)
|
||||
continuation = self._continuation_text(final_text)
|
||||
self._fallback_final_send = False
|
||||
if not continuation.strip():
|
||||
# Nothing new to send — the visible partial already matches final text.
|
||||
self._already_sent = True
|
||||
return
|
||||
|
||||
raw_limit = getattr(self.adapter, "MAX_MESSAGE_LENGTH", 4096)
|
||||
safe_limit = max(500, raw_limit - 100)
|
||||
chunks = self._split_text_chunks(continuation, safe_limit)
|
||||
|
||||
last_message_id: Optional[str] = None
|
||||
last_successful_chunk = ""
|
||||
sent_any_chunk = False
|
||||
for chunk in chunks:
|
||||
result = await self.adapter.send(
|
||||
chat_id=self.chat_id,
|
||||
content=chunk,
|
||||
metadata=self.metadata,
|
||||
)
|
||||
if not result.success:
|
||||
if sent_any_chunk:
|
||||
# Some continuation text already reached the user. Suppress
|
||||
# the base gateway final-send path so we don't resend the
|
||||
# full response and create another duplicate.
|
||||
self._already_sent = True
|
||||
self._message_id = last_message_id
|
||||
self._last_sent_text = last_successful_chunk
|
||||
self._fallback_prefix = ""
|
||||
return
|
||||
# No fallback chunk reached the user — allow the normal gateway
|
||||
# final-send path to try one more time.
|
||||
self._already_sent = False
|
||||
self._message_id = None
|
||||
self._last_sent_text = ""
|
||||
self._fallback_prefix = ""
|
||||
return
|
||||
sent_any_chunk = True
|
||||
last_successful_chunk = chunk
|
||||
last_message_id = result.message_id or last_message_id
|
||||
|
||||
self._message_id = last_message_id
|
||||
self._already_sent = True
|
||||
self._last_sent_text = chunks[-1]
|
||||
self._fallback_prefix = ""
|
||||
|
||||
async def _send_or_edit(self, text: str) -> None:
|
||||
"""Send or edit the streaming message."""
|
||||
# Strip MEDIA: directives so they don't appear as visible text.
|
||||
@@ -232,14 +331,16 @@ class GatewayStreamConsumer:
|
||||
self._last_sent_text = text
|
||||
else:
|
||||
# If an edit fails mid-stream (especially Telegram flood control),
|
||||
# stop progressive edits and let the normal final send path deliver
|
||||
# the complete answer instead of leaving the user with a partial.
|
||||
# stop progressive edits and send only the missing tail once the
|
||||
# final response is available.
|
||||
logger.debug("Edit failed, disabling streaming for this adapter")
|
||||
self._fallback_prefix = self._visible_prefix()
|
||||
self._fallback_final_send = True
|
||||
self._edit_supported = False
|
||||
self._already_sent = False
|
||||
self._already_sent = True
|
||||
else:
|
||||
# Editing not supported — skip intermediate updates.
|
||||
# The final response will be sent by the normal path.
|
||||
# The final response will be sent by the fallback path.
|
||||
pass
|
||||
else:
|
||||
# First message — send new
|
||||
|
||||
@@ -11,5 +11,5 @@ Provides subcommands for:
|
||||
- hermes cron - Manage cron jobs
|
||||
"""
|
||||
|
||||
__version__ = "0.7.0"
|
||||
__release_date__ = "2026.4.3"
|
||||
__version__ = "0.8.0"
|
||||
__release_date__ = "2026.4.8"
|
||||
|
||||
@@ -93,6 +93,21 @@ def cron_list(show_all: bool = False):
|
||||
script = job.get("script")
|
||||
if script:
|
||||
print(f" Script: {script}")
|
||||
|
||||
# Execution history
|
||||
last_status = job.get("last_status")
|
||||
if last_status:
|
||||
last_run = job.get("last_run_at", "?")
|
||||
if last_status == "ok":
|
||||
status_display = color("ok", Colors.GREEN)
|
||||
else:
|
||||
status_display = color(f"{last_status}: {job.get('last_error', '?')}", Colors.RED)
|
||||
print(f" Last run: {last_run} {status_display}")
|
||||
|
||||
delivery_err = job.get("last_delivery_error")
|
||||
if delivery_err:
|
||||
print(f" {color('⚠ Delivery failed:', Colors.YELLOW)} {delivery_err}")
|
||||
|
||||
print()
|
||||
|
||||
from hermes_cli.gateway import find_gateway_pids
|
||||
|
||||
@@ -791,12 +791,12 @@ def list_authenticated_providers(
|
||||
if overlay.auth_type in ("oauth_device_code", "oauth_external", "external_process"):
|
||||
# These use auth stores, not env vars — check for auth.json entries
|
||||
try:
|
||||
from hermes_cli.auth import _read_auth_store
|
||||
store = _read_auth_store()
|
||||
if store and pid in store:
|
||||
from hermes_cli.auth import _load_auth_store
|
||||
store = _load_auth_store()
|
||||
if store and (pid in store.get("providers", {}) or pid in store.get("credential_pool", {})):
|
||||
has_creds = True
|
||||
except Exception:
|
||||
pass
|
||||
except Exception as exc:
|
||||
logger.debug("Auth store check failed for %s: %s", pid, exc)
|
||||
if not has_creds:
|
||||
continue
|
||||
|
||||
|
||||
+12
-8
@@ -144,18 +144,22 @@ _PROVIDER_MODELS: dict[str, list[str]] = {
|
||||
"kimi-k2-0905-preview",
|
||||
],
|
||||
"minimax": [
|
||||
"MiniMax-M2.7",
|
||||
"MiniMax-M2.7-highspeed",
|
||||
"MiniMax-M1",
|
||||
"MiniMax-M1-40k",
|
||||
"MiniMax-M1-80k",
|
||||
"MiniMax-M1-128k",
|
||||
"MiniMax-M1-256k",
|
||||
"MiniMax-M2.5",
|
||||
"MiniMax-M2.5-highspeed",
|
||||
"MiniMax-M2.1",
|
||||
"MiniMax-M2.7",
|
||||
],
|
||||
"minimax-cn": [
|
||||
"MiniMax-M2.7",
|
||||
"MiniMax-M2.7-highspeed",
|
||||
"MiniMax-M1",
|
||||
"MiniMax-M1-40k",
|
||||
"MiniMax-M1-80k",
|
||||
"MiniMax-M1-128k",
|
||||
"MiniMax-M1-256k",
|
||||
"MiniMax-M2.5",
|
||||
"MiniMax-M2.5-highspeed",
|
||||
"MiniMax-M2.1",
|
||||
"MiniMax-M2.7",
|
||||
],
|
||||
"anthropic": [
|
||||
"claude-opus-4-6",
|
||||
|
||||
@@ -61,6 +61,8 @@ VALID_HOOKS: Set[str] = {
|
||||
"post_api_request",
|
||||
"on_session_start",
|
||||
"on_session_end",
|
||||
"on_session_finalize",
|
||||
"on_session_reset",
|
||||
}
|
||||
|
||||
ENTRY_POINTS_GROUP = "hermes_agent.plugins"
|
||||
|
||||
@@ -163,6 +163,16 @@ def _resolve_runtime_from_pool_entry(
|
||||
api_mode = _copilot_runtime_api_mode(model_cfg, getattr(entry, "runtime_api_key", ""))
|
||||
else:
|
||||
configured_provider = str(model_cfg.get("provider") or "").strip().lower()
|
||||
# Honour model.base_url from config.yaml when the configured provider
|
||||
# matches this provider — same pattern as the Anthropic branch above.
|
||||
# Only override when the pool entry has no explicit base_url (i.e. it
|
||||
# fell back to the hardcoded default). Env var overrides win (#6039).
|
||||
pconfig = PROVIDER_REGISTRY.get(provider)
|
||||
pool_url_is_default = pconfig and base_url.rstrip("/") == pconfig.inference_base_url.rstrip("/")
|
||||
if configured_provider == provider and pool_url_is_default:
|
||||
cfg_base_url = str(model_cfg.get("base_url") or "").strip().rstrip("/")
|
||||
if cfg_base_url:
|
||||
base_url = cfg_base_url
|
||||
configured_mode = _parse_api_mode(model_cfg.get("api_mode"))
|
||||
if configured_mode and _provider_supports_explicit_api_mode(provider, configured_provider):
|
||||
api_mode = configured_mode
|
||||
@@ -724,7 +734,15 @@ def resolve_runtime_provider(
|
||||
pconfig = PROVIDER_REGISTRY.get(provider)
|
||||
if pconfig and pconfig.auth_type == "api_key":
|
||||
creds = resolve_api_key_provider_credentials(provider)
|
||||
base_url = creds.get("base_url", "").rstrip("/")
|
||||
# Honour model.base_url from config.yaml when the configured provider
|
||||
# matches this provider — mirrors the Anthropic path above. Without
|
||||
# this, users who set model.base_url to e.g. api.minimaxi.com/anthropic
|
||||
# (China endpoint) still get the hardcoded api.minimax.io default (#6039).
|
||||
cfg_provider = str(model_cfg.get("provider") or "").strip().lower()
|
||||
cfg_base_url = ""
|
||||
if cfg_provider == provider:
|
||||
cfg_base_url = (model_cfg.get("base_url") or "").strip().rstrip("/")
|
||||
base_url = cfg_base_url or creds.get("base_url", "").rstrip("/")
|
||||
api_mode = "chat_completions"
|
||||
if provider == "copilot":
|
||||
api_mode = _copilot_runtime_api_mode(model_cfg, creds.get("api_key", ""))
|
||||
|
||||
+2
-2
@@ -105,8 +105,8 @@ _DEFAULT_PROVIDER_MODELS = {
|
||||
],
|
||||
"zai": ["glm-5", "glm-4.7", "glm-4.5", "glm-4.5-flash"],
|
||||
"kimi-coding": ["kimi-k2.5", "kimi-k2-thinking", "kimi-k2-turbo-preview"],
|
||||
"minimax": ["MiniMax-M2.7", "MiniMax-M2.7-highspeed", "MiniMax-M2.5", "MiniMax-M2.5-highspeed", "MiniMax-M2.1"],
|
||||
"minimax-cn": ["MiniMax-M2.7", "MiniMax-M2.7-highspeed", "MiniMax-M2.5", "MiniMax-M2.5-highspeed", "MiniMax-M2.1"],
|
||||
"minimax": ["MiniMax-M1", "MiniMax-M1-40k", "MiniMax-M1-80k", "MiniMax-M1-128k", "MiniMax-M1-256k", "MiniMax-M2.5", "MiniMax-M2.7"],
|
||||
"minimax-cn": ["MiniMax-M1", "MiniMax-M1-40k", "MiniMax-M1-80k", "MiniMax-M1-128k", "MiniMax-M1-256k", "MiniMax-M2.5", "MiniMax-M2.7"],
|
||||
"ai-gateway": ["anthropic/claude-opus-4.6", "anthropic/claude-sonnet-4.6", "openai/gpt-5", "google/gemini-3-flash"],
|
||||
"kilocode": ["anthropic/claude-opus-4.6", "anthropic/claude-sonnet-4.6", "openai/gpt-5.4", "google/gemini-3-pro-preview", "google/gemini-3-flash-preview"],
|
||||
"opencode-zen": ["gpt-5.4", "gpt-5.3-codex", "claude-sonnet-4-6", "gemini-3-flash", "glm-5", "kimi-k2.5", "minimax-m2.7"],
|
||||
|
||||
@@ -23,6 +23,8 @@ import json
|
||||
import logging
|
||||
import os
|
||||
import threading
|
||||
|
||||
from hermes_constants import get_hermes_home
|
||||
from typing import Any, Dict, List
|
||||
|
||||
from agent.memory_provider import MemoryProvider
|
||||
@@ -142,7 +144,6 @@ def _load_config() -> dict:
|
||||
3. Environment variables
|
||||
"""
|
||||
from pathlib import Path
|
||||
from hermes_constants import get_hermes_home
|
||||
|
||||
# Profile-scoped path (preferred)
|
||||
profile_path = get_hermes_home() / "hindsight" / "config.json"
|
||||
|
||||
+1
-1
@@ -4,7 +4,7 @@ build-backend = "setuptools.build_meta"
|
||||
|
||||
[project]
|
||||
name = "hermes-agent"
|
||||
version = "0.7.0"
|
||||
version = "0.8.0"
|
||||
description = "The self-improving AI agent — creates skills from experience, improves them during use, and runs anywhere"
|
||||
readme = "README.md"
|
||||
requires-python = ">=3.11"
|
||||
|
||||
+99
-68
@@ -66,7 +66,8 @@ from model_tools import (
|
||||
handle_function_call,
|
||||
check_toolset_requirements,
|
||||
)
|
||||
from tools.terminal_tool import cleanup_vm
|
||||
from tools.terminal_tool import cleanup_vm, get_active_env
|
||||
from tools.tool_result_storage import maybe_persist_tool_result, enforce_turn_budget
|
||||
from tools.interrupt import set_interrupt as _set_interrupt
|
||||
from tools.browser_tool import cleanup_browser
|
||||
|
||||
@@ -75,6 +76,7 @@ from hermes_constants import OPENROUTER_BASE_URL
|
||||
|
||||
# Agent internals extracted to agent/ package for modularity
|
||||
from agent.memory_manager import build_memory_context_block
|
||||
from agent.retry_utils import jittered_backoff
|
||||
from agent.prompt_builder import (
|
||||
DEFAULT_AGENT_IDENTITY, PLATFORM_HINTS,
|
||||
MEMORY_GUIDANCE, SESSION_SEARCH_GUIDANCE, SKILLS_GUIDANCE,
|
||||
@@ -85,6 +87,7 @@ from agent.model_metadata import (
|
||||
estimate_tokens_rough, estimate_messages_tokens_rough, estimate_request_tokens_rough,
|
||||
get_next_probe_tier, parse_context_limit_from_error,
|
||||
save_context_length, is_local_endpoint,
|
||||
query_ollama_num_ctx,
|
||||
)
|
||||
from agent.context_compressor import ContextCompressor
|
||||
from agent.subdirectory_hints import SubdirectoryHintTracker
|
||||
@@ -409,63 +412,6 @@ def _strip_budget_warnings_from_history(messages: list) -> None:
|
||||
# Large tool result handler — save oversized output to temp file
|
||||
# =========================================================================
|
||||
|
||||
# Threshold at which tool results are saved to a file instead of kept inline.
|
||||
# 100K chars ≈ 25K tokens — generous for any reasonable output but prevents
|
||||
# catastrophic context explosions.
|
||||
_LARGE_RESULT_CHARS = 100_000
|
||||
|
||||
# How many characters of the original result to include as an inline preview
|
||||
# so the model has immediate context about what the tool returned.
|
||||
_LARGE_RESULT_PREVIEW_CHARS = 1_500
|
||||
|
||||
|
||||
def _save_oversized_tool_result(function_name: str, function_result: str) -> str:
|
||||
"""Replace oversized tool results with a file reference + preview.
|
||||
|
||||
When a tool returns more than ``_LARGE_RESULT_CHARS`` characters, the full
|
||||
content is written to a temporary file under ``HERMES_HOME/cache/tool_responses/``
|
||||
and the result sent to the model is replaced with:
|
||||
• a brief head preview (first ``_LARGE_RESULT_PREVIEW_CHARS`` chars)
|
||||
• the file path so the model can use ``read_file`` / ``search_files``
|
||||
|
||||
Falls back to destructive truncation if the file write fails.
|
||||
"""
|
||||
original_len = len(function_result)
|
||||
if original_len <= _LARGE_RESULT_CHARS:
|
||||
return function_result
|
||||
|
||||
# Build the target directory
|
||||
try:
|
||||
response_dir = os.path.join(get_hermes_home(), "cache", "tool_responses")
|
||||
os.makedirs(response_dir, exist_ok=True)
|
||||
|
||||
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S_%f")
|
||||
# Sanitize tool name for use in filename
|
||||
safe_name = re.sub(r"[^\w\-]", "_", function_name)[:40]
|
||||
filename = f"{safe_name}_{timestamp}.txt"
|
||||
filepath = os.path.join(response_dir, filename)
|
||||
|
||||
with open(filepath, "w", encoding="utf-8") as f:
|
||||
f.write(function_result)
|
||||
|
||||
preview = function_result[:_LARGE_RESULT_PREVIEW_CHARS]
|
||||
return (
|
||||
f"{preview}\n\n"
|
||||
f"[Large tool response: {original_len:,} characters total — "
|
||||
f"only the first {_LARGE_RESULT_PREVIEW_CHARS:,} shown above. "
|
||||
f"Full output saved to: {filepath}\n"
|
||||
f"Use read_file or search_files on that path to access the rest.]"
|
||||
)
|
||||
except Exception as exc:
|
||||
# Fall back to destructive truncation if file write fails
|
||||
logger.warning("Failed to save large tool result to file: %s", exc)
|
||||
return (
|
||||
function_result[:_LARGE_RESULT_CHARS]
|
||||
+ f"\n\n[Truncated: tool response was {original_len:,} chars, "
|
||||
f"exceeding the {_LARGE_RESULT_CHARS:,} char limit. "
|
||||
f"File save failed: {exc}]"
|
||||
)
|
||||
|
||||
|
||||
class AIAgent:
|
||||
"""
|
||||
@@ -1216,6 +1162,33 @@ class AIAgent:
|
||||
self.session_cost_status = "unknown"
|
||||
self.session_cost_source = "none"
|
||||
|
||||
# ── Ollama num_ctx injection ──
|
||||
# Ollama defaults to 2048 context regardless of the model's capabilities.
|
||||
# When running against an Ollama server, detect the model's max context
|
||||
# and pass num_ctx on every chat request so the full window is used.
|
||||
# User override: set model.ollama_num_ctx in config.yaml to cap VRAM use.
|
||||
self._ollama_num_ctx: int | None = None
|
||||
_ollama_num_ctx_override = None
|
||||
if isinstance(_model_cfg, dict):
|
||||
_ollama_num_ctx_override = _model_cfg.get("ollama_num_ctx")
|
||||
if _ollama_num_ctx_override is not None:
|
||||
try:
|
||||
self._ollama_num_ctx = int(_ollama_num_ctx_override)
|
||||
except (TypeError, ValueError):
|
||||
logger.debug("Invalid ollama_num_ctx config value: %r", _ollama_num_ctx_override)
|
||||
if self._ollama_num_ctx is None and self.base_url and is_local_endpoint(self.base_url):
|
||||
try:
|
||||
_detected = query_ollama_num_ctx(self.model, self.base_url)
|
||||
if _detected and _detected > 0:
|
||||
self._ollama_num_ctx = _detected
|
||||
except Exception as exc:
|
||||
logger.debug("Ollama num_ctx detection failed: %s", exc)
|
||||
if self._ollama_num_ctx and not self.quiet_mode:
|
||||
logger.info(
|
||||
"Ollama num_ctx: will request %d tokens (model max from /api/show)",
|
||||
self._ollama_num_ctx,
|
||||
)
|
||||
|
||||
if not self.quiet_mode:
|
||||
if compression_enabled:
|
||||
print(f"📊 Context limit: {self.context_compressor.context_length:,} tokens (compress at {int(compression_threshold*100)}% = {self.context_compressor.threshold_tokens:,})")
|
||||
@@ -5456,6 +5429,15 @@ class AIAgent:
|
||||
if _is_nous:
|
||||
extra_body["tags"] = ["product=hermes-agent"]
|
||||
|
||||
# Ollama num_ctx: override the 2048 default so the model actually
|
||||
# uses the context window it was trained for. Passed via the OpenAI
|
||||
# SDK's extra_body → options.num_ctx, which Ollama's OpenAI-compat
|
||||
# endpoint forwards to the runner as --ctx-size.
|
||||
if self._ollama_num_ctx:
|
||||
options = extra_body.get("options", {})
|
||||
options["num_ctx"] = self._ollama_num_ctx
|
||||
extra_body["options"] = options
|
||||
|
||||
if extra_body:
|
||||
api_kwargs["extra_body"] = extra_body
|
||||
|
||||
@@ -6224,15 +6206,17 @@ class AIAgent:
|
||||
except Exception as cb_err:
|
||||
logging.debug(f"Tool complete callback error: {cb_err}")
|
||||
|
||||
# Save oversized results to file instead of destructive truncation
|
||||
function_result = _save_oversized_tool_result(name, function_result)
|
||||
function_result = maybe_persist_tool_result(
|
||||
content=function_result,
|
||||
tool_name=name,
|
||||
tool_use_id=tc.id,
|
||||
env=get_active_env(effective_task_id),
|
||||
)
|
||||
|
||||
# Discover subdirectory context files from tool arguments
|
||||
subdir_hints = self._subdirectory_hints.check_tool_call(name, args)
|
||||
if subdir_hints:
|
||||
function_result += subdir_hints
|
||||
|
||||
# Append tool result message in order
|
||||
tool_msg = {
|
||||
"role": "tool",
|
||||
"content": function_result,
|
||||
@@ -6240,6 +6224,12 @@ class AIAgent:
|
||||
}
|
||||
messages.append(tool_msg)
|
||||
|
||||
# ── Per-turn aggregate budget enforcement ─────────────────────────
|
||||
num_tools = len(parsed_calls)
|
||||
if num_tools > 0:
|
||||
turn_tool_msgs = messages[-num_tools:]
|
||||
enforce_turn_budget(turn_tool_msgs, env=get_active_env(effective_task_id))
|
||||
|
||||
# ── Budget pressure injection ────────────────────────────────────
|
||||
budget_warning = self._get_budget_warning(api_call_count)
|
||||
if budget_warning and messages and messages[-1].get("role") == "tool":
|
||||
@@ -6524,8 +6514,12 @@ class AIAgent:
|
||||
except Exception as cb_err:
|
||||
logging.debug(f"Tool complete callback error: {cb_err}")
|
||||
|
||||
# Save oversized results to file instead of destructive truncation
|
||||
function_result = _save_oversized_tool_result(function_name, function_result)
|
||||
function_result = maybe_persist_tool_result(
|
||||
content=function_result,
|
||||
tool_name=function_name,
|
||||
tool_use_id=tool_call.id,
|
||||
env=get_active_env(effective_task_id),
|
||||
)
|
||||
|
||||
# Discover subdirectory context files from tool arguments
|
||||
subdir_hints = self._subdirectory_hints.check_tool_call(function_name, function_args)
|
||||
@@ -6563,6 +6557,11 @@ class AIAgent:
|
||||
if self.tool_delay > 0 and i < len(assistant_message.tool_calls):
|
||||
time.sleep(self.tool_delay)
|
||||
|
||||
# ── Per-turn aggregate budget enforcement ─────────────────────────
|
||||
num_tools_seq = len(assistant_message.tool_calls)
|
||||
if num_tools_seq > 0:
|
||||
enforce_turn_budget(messages[-num_tools_seq:], env=get_active_env(effective_task_id))
|
||||
|
||||
# ── Budget pressure injection ─────────────────────────────────
|
||||
# After all tool calls in this turn are processed, check if we're
|
||||
# approaching max_iterations. If so, inject a warning into the LAST
|
||||
@@ -7289,6 +7288,7 @@ class AIAgent:
|
||||
codex_auth_retry_attempted=False
|
||||
anthropic_auth_retry_attempted=False
|
||||
nous_auth_retry_attempted=False
|
||||
thinking_sig_retry_attempted = False
|
||||
has_retried_429 = False
|
||||
restart_with_compressed_messages = False
|
||||
restart_with_length_continuation = False
|
||||
@@ -7504,7 +7504,8 @@ class AIAgent:
|
||||
}
|
||||
|
||||
# Longer backoff for rate limiting (likely cause of None choices)
|
||||
wait_time = min(5 * (2 ** (retry_count - 1)), 120) # 5s, 10s, 20s, 40s, 80s, 120s
|
||||
# Jittered exponential: 5s base, 120s cap + random jitter
|
||||
wait_time = jittered_backoff(retry_count, base_delay=5.0, max_delay=120.0)
|
||||
self._vprint(f"{self.log_prefix}⏳ Retrying in {wait_time}s (extended backoff for possible rate limit)...", force=True)
|
||||
logging.warning(f"Invalid API response (retry {retry_count}/{max_retries}): {', '.join(error_details)} | Provider: {provider_name}")
|
||||
|
||||
@@ -7877,8 +7878,38 @@ class AIAgent:
|
||||
print(f"{self.log_prefix} • Check ANTHROPIC_API_KEY in {_dhh}/.env for API keys or legacy token values")
|
||||
print(f"{self.log_prefix} • For API keys: verify at https://console.anthropic.com/settings/keys")
|
||||
print(f"{self.log_prefix} • For Claude Code: run 'claude /login' to refresh, then retry")
|
||||
print(f"{self.log_prefix} • Clear stale keys: hermes config set ANTHROPIC_TOKEN \"\"")
|
||||
print(f"{self.log_prefix} • Legacy cleanup: hermes config set ANTHROPIC_API_KEY \"\"")
|
||||
print(f"{self.log_prefix} • Legacy cleanup: hermes config set ANTHROPIC_TOKEN \"\"")
|
||||
print(f"{self.log_prefix} • Clear stale keys: hermes config set ANTHROPIC_API_KEY \"\"")
|
||||
|
||||
# ── Thinking block signature recovery ─────────────────
|
||||
# Anthropic signs thinking blocks against the full turn
|
||||
# content. Any upstream mutation (context compression,
|
||||
# session truncation, message merging) invalidates the
|
||||
# signature → HTTP 400. Recovery: strip reasoning_details
|
||||
# from all messages so the next retry sends no thinking
|
||||
# blocks at all. One-shot — don't retry infinitely.
|
||||
if (
|
||||
self.api_mode == "anthropic_messages"
|
||||
and status_code == 400
|
||||
and not thinking_sig_retry_attempted
|
||||
):
|
||||
_err_msg_lower = str(api_error).lower()
|
||||
if "signature" in _err_msg_lower and "thinking" in _err_msg_lower:
|
||||
thinking_sig_retry_attempted = True
|
||||
for _m in messages:
|
||||
if isinstance(_m, dict):
|
||||
_m.pop("reasoning_details", None)
|
||||
self._vprint(
|
||||
f"{self.log_prefix}⚠️ Thinking block signature invalid — "
|
||||
f"stripped all thinking blocks, retrying...",
|
||||
force=True,
|
||||
)
|
||||
logging.warning(
|
||||
"%sThinking block signature recovery: stripped "
|
||||
"reasoning_details from %d messages",
|
||||
self.log_prefix, len(messages),
|
||||
)
|
||||
continue
|
||||
|
||||
retry_count += 1
|
||||
elapsed_time = time.time() - api_start_time
|
||||
@@ -8361,7 +8392,7 @@ class AIAgent:
|
||||
_retry_after = min(int(_ra_raw), 120) # Cap at 2 minutes
|
||||
except (TypeError, ValueError):
|
||||
pass
|
||||
wait_time = _retry_after if _retry_after else min(2 ** retry_count, 60)
|
||||
wait_time = _retry_after if _retry_after else jittered_backoff(retry_count, base_delay=2.0, max_delay=60.0)
|
||||
if is_rate_limited:
|
||||
self._emit_status(f"⏱️ Rate limit reached. Waiting {wait_time}s before retry (attempt {retry_count + 1}/{max_retries})...")
|
||||
else:
|
||||
|
||||
@@ -1276,6 +1276,258 @@ class TestRoleAlternation:
|
||||
assert [m["role"] for m in result] == ["user", "assistant", "user"]
|
||||
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# Thinking block signature management
|
||||
# ---------------------------------------------------------------------------
|
||||
|
||||
|
||||
class TestThinkingBlockSignatureManagement:
|
||||
"""Tests for the thinking block handling strategy:
|
||||
strip from old turns, preserve latest signed, downgrade unsigned."""
|
||||
|
||||
def test_thinking_stripped_from_non_last_assistant(self):
|
||||
"""Thinking blocks are removed from all assistant messages except the last."""
|
||||
messages = [
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": "",
|
||||
"tool_calls": [
|
||||
{"id": "tc_1", "function": {"name": "tool1", "arguments": "{}"}},
|
||||
],
|
||||
"reasoning_details": [
|
||||
{"type": "thinking", "thinking": "Old reasoning.", "signature": "sig_old"},
|
||||
],
|
||||
},
|
||||
{"role": "tool", "tool_call_id": "tc_1", "content": "result 1"},
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": "",
|
||||
"tool_calls": [
|
||||
{"id": "tc_2", "function": {"name": "tool2", "arguments": "{}"}},
|
||||
],
|
||||
"reasoning_details": [
|
||||
{"type": "thinking", "thinking": "Latest reasoning.", "signature": "sig_new"},
|
||||
],
|
||||
},
|
||||
{"role": "tool", "tool_call_id": "tc_2", "content": "result 2"},
|
||||
]
|
||||
_, result = convert_messages_to_anthropic(messages)
|
||||
|
||||
# Find both assistant messages
|
||||
assistants = [m for m in result if m["role"] == "assistant"]
|
||||
assert len(assistants) == 2
|
||||
|
||||
# First (non-last) assistant: no thinking blocks
|
||||
first_types = [b.get("type") for b in assistants[0]["content"]]
|
||||
assert "thinking" not in first_types
|
||||
assert "redacted_thinking" not in first_types
|
||||
assert "tool_use" in first_types # tool_use should survive
|
||||
|
||||
# Last assistant: thinking block preserved with signature
|
||||
last_blocks = assistants[1]["content"]
|
||||
thinking_blocks = [b for b in last_blocks if b.get("type") == "thinking"]
|
||||
assert len(thinking_blocks) == 1
|
||||
assert thinking_blocks[0]["thinking"] == "Latest reasoning."
|
||||
assert thinking_blocks[0]["signature"] == "sig_new"
|
||||
|
||||
def test_signed_thinking_preserved_on_last_turn(self):
|
||||
"""A signed thinking block on the last assistant message is kept."""
|
||||
messages = [
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": "The answer is 42.",
|
||||
"reasoning_details": [
|
||||
{"type": "thinking", "thinking": "Deep thought.", "signature": "sig_valid"},
|
||||
],
|
||||
},
|
||||
]
|
||||
_, result = convert_messages_to_anthropic(messages)
|
||||
blocks = result[0]["content"]
|
||||
thinking = [b for b in blocks if b.get("type") == "thinking"]
|
||||
assert len(thinking) == 1
|
||||
assert thinking[0]["signature"] == "sig_valid"
|
||||
|
||||
def test_unsigned_thinking_downgraded_to_text_on_last_turn(self):
|
||||
"""Unsigned thinking blocks on the last turn become text blocks."""
|
||||
messages = [
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": "Response text.",
|
||||
"reasoning_details": [
|
||||
{"type": "thinking", "thinking": "Unsigned reasoning."},
|
||||
# No 'signature' field
|
||||
],
|
||||
},
|
||||
]
|
||||
_, result = convert_messages_to_anthropic(messages)
|
||||
blocks = result[0]["content"]
|
||||
|
||||
# No thinking blocks should remain
|
||||
assert not any(b.get("type") == "thinking" for b in blocks)
|
||||
# The reasoning text should be preserved as a text block
|
||||
text_contents = [b.get("text", "") for b in blocks if b.get("type") == "text"]
|
||||
assert "Unsigned reasoning." in text_contents
|
||||
|
||||
def test_redacted_thinking_with_data_preserved(self):
|
||||
"""Redacted thinking with 'data' field is kept on last turn."""
|
||||
messages = [
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": "Response.",
|
||||
"reasoning_details": [
|
||||
{"type": "redacted_thinking", "data": "opaque_signature_data"},
|
||||
],
|
||||
},
|
||||
]
|
||||
_, result = convert_messages_to_anthropic(messages)
|
||||
blocks = result[0]["content"]
|
||||
redacted = [b for b in blocks if b.get("type") == "redacted_thinking"]
|
||||
assert len(redacted) == 1
|
||||
assert redacted[0]["data"] == "opaque_signature_data"
|
||||
|
||||
def test_redacted_thinking_without_data_dropped(self):
|
||||
"""Redacted thinking without 'data' is dropped — can't be validated."""
|
||||
messages = [
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": "Response.",
|
||||
"reasoning_details": [
|
||||
{"type": "redacted_thinking"},
|
||||
# No 'data' field
|
||||
],
|
||||
},
|
||||
]
|
||||
_, result = convert_messages_to_anthropic(messages)
|
||||
blocks = result[0]["content"]
|
||||
assert not any(b.get("type") == "redacted_thinking" for b in blocks)
|
||||
|
||||
def test_cache_control_stripped_from_thinking_blocks(self):
|
||||
"""cache_control markers are removed from thinking/redacted_thinking blocks."""
|
||||
messages = [
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": "",
|
||||
"tool_calls": [
|
||||
{"id": "tc_1", "function": {"name": "t", "arguments": "{}"}},
|
||||
],
|
||||
"reasoning_details": [
|
||||
{
|
||||
"type": "thinking",
|
||||
"thinking": "Reasoning.",
|
||||
"signature": "sig_1",
|
||||
"cache_control": {"type": "ephemeral"},
|
||||
},
|
||||
],
|
||||
},
|
||||
{"role": "tool", "tool_call_id": "tc_1", "content": "result"},
|
||||
]
|
||||
_, result = convert_messages_to_anthropic(messages)
|
||||
assistant = next(m for m in result if m["role"] == "assistant")
|
||||
for block in assistant["content"]:
|
||||
if block.get("type") in ("thinking", "redacted_thinking"):
|
||||
assert "cache_control" not in block
|
||||
|
||||
def test_thinking_stripped_from_merged_consecutive_assistants(self):
|
||||
"""When consecutive assistants are merged, second one's thinking is dropped."""
|
||||
messages = [
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": "First response.",
|
||||
"reasoning_details": [
|
||||
{"type": "thinking", "thinking": "First thought.", "signature": "sig_1"},
|
||||
],
|
||||
},
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": "Second response.",
|
||||
"reasoning_details": [
|
||||
{"type": "thinking", "thinking": "Second thought.", "signature": "sig_2"},
|
||||
],
|
||||
},
|
||||
]
|
||||
_, result = convert_messages_to_anthropic(messages)
|
||||
|
||||
# Should be merged into one assistant message
|
||||
assistants = [m for m in result if m["role"] == "assistant"]
|
||||
assert len(assistants) == 1
|
||||
|
||||
# Only the first thinking block should remain (signed, on the last/only assistant)
|
||||
blocks = assistants[0]["content"]
|
||||
thinking = [b for b in blocks if b.get("type") == "thinking"]
|
||||
assert len(thinking) == 1
|
||||
assert thinking[0]["thinking"] == "First thought."
|
||||
|
||||
def test_empty_content_after_strip_gets_placeholder(self):
|
||||
"""If stripping thinking leaves an empty message, a placeholder is added."""
|
||||
messages = [
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": "",
|
||||
"reasoning_details": [
|
||||
{"type": "thinking", "thinking": "Only thinking, no text."},
|
||||
# Unsigned — will be downgraded, but content was empty string
|
||||
],
|
||||
},
|
||||
{"role": "user", "content": "Next message."},
|
||||
{"role": "assistant", "content": "Final."},
|
||||
]
|
||||
_, result = convert_messages_to_anthropic(messages)
|
||||
# First assistant is non-last, so thinking is stripped completely.
|
||||
# The original content was empty and thinking was unsigned → placeholder
|
||||
first_assistant = result[0]
|
||||
assert first_assistant["role"] == "assistant"
|
||||
assert len(first_assistant["content"]) >= 1
|
||||
|
||||
def test_multi_turn_conversation_preserves_only_last(self):
|
||||
"""Full multi-turn conversation: only last assistant keeps thinking."""
|
||||
messages = [
|
||||
{"role": "user", "content": "Question 1"},
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": "Answer 1",
|
||||
"reasoning_details": [
|
||||
{"type": "thinking", "thinking": "Thought 1", "signature": "sig_1"},
|
||||
],
|
||||
},
|
||||
{"role": "user", "content": "Question 2"},
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": "Answer 2",
|
||||
"reasoning_details": [
|
||||
{"type": "thinking", "thinking": "Thought 2", "signature": "sig_2"},
|
||||
],
|
||||
},
|
||||
{"role": "user", "content": "Question 3"},
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": "Answer 3",
|
||||
"reasoning_details": [
|
||||
{"type": "thinking", "thinking": "Thought 3", "signature": "sig_3"},
|
||||
],
|
||||
},
|
||||
]
|
||||
_, result = convert_messages_to_anthropic(messages)
|
||||
|
||||
assistants = [m for m in result if m["role"] == "assistant"]
|
||||
assert len(assistants) == 3
|
||||
|
||||
# First two: no thinking blocks
|
||||
for a in assistants[:2]:
|
||||
assert not any(
|
||||
b.get("type") in ("thinking", "redacted_thinking")
|
||||
for b in a["content"]
|
||||
if isinstance(b, dict)
|
||||
)
|
||||
|
||||
# Last one: thinking preserved
|
||||
last_thinking = [
|
||||
b for b in assistants[2]["content"]
|
||||
if isinstance(b, dict) and b.get("type") == "thinking"
|
||||
]
|
||||
assert len(last_thinking) == 1
|
||||
assert last_thinking[0]["signature"] == "sig_3"
|
||||
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# Tool choice
|
||||
# ---------------------------------------------------------------------------
|
||||
|
||||
@@ -471,6 +471,23 @@ class TestExplicitProviderRouting:
|
||||
client, model = resolve_provider_client("zai")
|
||||
assert client is not None
|
||||
|
||||
def test_explicit_google_alias_uses_gemini_credentials(self):
|
||||
"""provider='google' should route through the gemini API-key provider."""
|
||||
with (
|
||||
patch("hermes_cli.auth.resolve_api_key_provider_credentials", return_value={
|
||||
"api_key": "gemini-key",
|
||||
"base_url": "https://generativelanguage.googleapis.com/v1beta/openai",
|
||||
}),
|
||||
patch("agent.auxiliary_client.OpenAI") as mock_openai,
|
||||
):
|
||||
mock_openai.return_value = MagicMock()
|
||||
client, model = resolve_provider_client("google", model="gemini-3.1-pro-preview")
|
||||
|
||||
assert client is not None
|
||||
assert model == "gemini-3.1-pro-preview"
|
||||
assert mock_openai.call_args.kwargs["api_key"] == "gemini-key"
|
||||
assert mock_openai.call_args.kwargs["base_url"] == "https://generativelanguage.googleapis.com/v1beta/openai"
|
||||
|
||||
def test_explicit_unknown_returns_none(self, monkeypatch):
|
||||
"""Unknown provider should return None."""
|
||||
client, model = resolve_provider_client("nonexistent-provider")
|
||||
@@ -624,12 +641,15 @@ class TestVisionClientFallback:
|
||||
assert client is None
|
||||
assert model is None
|
||||
|
||||
def test_vision_auto_includes_anthropic_when_configured(self, monkeypatch):
|
||||
monkeypatch.setenv("ANTHROPIC_API_KEY", "sk-ant-api03-key")
|
||||
def test_vision_auto_includes_active_provider_when_configured(self, monkeypatch):
|
||||
"""Active provider appears in available backends when credentials exist."""
|
||||
monkeypatch.setenv("ANTHROPIC_API_KEY", "***")
|
||||
with (
|
||||
patch("agent.auxiliary_client._read_nous_auth", return_value=None),
|
||||
patch("agent.auxiliary_client._read_main_provider", return_value="anthropic"),
|
||||
patch("agent.auxiliary_client._read_main_model", return_value="claude-sonnet-4"),
|
||||
patch("agent.anthropic_adapter.build_anthropic_client", return_value=MagicMock()),
|
||||
patch("agent.anthropic_adapter.resolve_anthropic_token", return_value="sk-ant-api03-key"),
|
||||
patch("agent.anthropic_adapter.resolve_anthropic_token", return_value="***"),
|
||||
):
|
||||
backends = get_available_vision_backends()
|
||||
|
||||
@@ -702,88 +722,50 @@ class TestAuxiliaryPoolAwareness:
|
||||
assert call_kwargs["base_url"] == "https://api.githubcopilot.com"
|
||||
assert call_kwargs["default_headers"]["Editor-Version"]
|
||||
|
||||
def test_vision_auto_uses_anthropic_when_no_higher_priority_backend(self, monkeypatch):
|
||||
monkeypatch.setenv("ANTHROPIC_API_KEY", "sk-ant-api03-key")
|
||||
def test_vision_auto_uses_active_provider_as_fallback(self, monkeypatch):
|
||||
"""When no OpenRouter/Nous available, vision auto falls back to active provider."""
|
||||
monkeypatch.setenv("ANTHROPIC_API_KEY", "***")
|
||||
with (
|
||||
patch("agent.auxiliary_client._read_nous_auth", return_value=None),
|
||||
patch("agent.auxiliary_client._read_main_provider", return_value="anthropic"),
|
||||
patch("agent.auxiliary_client._read_main_model", return_value="claude-sonnet-4"),
|
||||
patch("agent.anthropic_adapter.build_anthropic_client", return_value=MagicMock()),
|
||||
patch("agent.anthropic_adapter.resolve_anthropic_token", return_value="sk-ant-api03-key"),
|
||||
patch("agent.anthropic_adapter.resolve_anthropic_token", return_value="***"),
|
||||
):
|
||||
client, model = get_vision_auxiliary_client()
|
||||
|
||||
assert client is not None
|
||||
assert client.__class__.__name__ == "AnthropicAuxiliaryClient"
|
||||
assert model == "claude-haiku-4-5-20251001"
|
||||
|
||||
def test_selected_anthropic_provider_is_preferred_for_vision_auto(self, monkeypatch):
|
||||
def test_vision_auto_prefers_openrouter_over_active_provider(self, monkeypatch):
|
||||
"""OpenRouter is tried before the active provider in vision auto."""
|
||||
monkeypatch.setenv("OPENROUTER_API_KEY", "or-key")
|
||||
monkeypatch.setenv("ANTHROPIC_API_KEY", "sk-ant-api03-key")
|
||||
|
||||
def fake_load_config():
|
||||
return {"model": {"provider": "anthropic", "default": "claude-sonnet-4-6"}}
|
||||
monkeypatch.setenv("ANTHROPIC_API_KEY", "***")
|
||||
|
||||
with (
|
||||
patch("agent.auxiliary_client._read_nous_auth", return_value=None),
|
||||
patch("agent.anthropic_adapter.build_anthropic_client", return_value=MagicMock()),
|
||||
patch("agent.anthropic_adapter.resolve_anthropic_token", return_value="sk-ant-api03-key"),
|
||||
patch("agent.auxiliary_client._read_main_provider", return_value="anthropic"),
|
||||
patch("agent.auxiliary_client._read_main_model", return_value="claude-sonnet-4"),
|
||||
patch("agent.auxiliary_client.OpenAI") as mock_openai,
|
||||
patch("hermes_cli.config.load_config", fake_load_config),
|
||||
):
|
||||
client, model = get_vision_auxiliary_client()
|
||||
|
||||
assert client is not None
|
||||
assert client.__class__.__name__ == "AnthropicAuxiliaryClient"
|
||||
assert model == "claude-haiku-4-5-20251001"
|
||||
|
||||
def test_selected_codex_provider_short_circuits_vision_auto(self, monkeypatch):
|
||||
def fake_load_config():
|
||||
return {"model": {"provider": "openai-codex", "default": "gpt-5.2-codex"}}
|
||||
|
||||
codex_client = MagicMock()
|
||||
with (
|
||||
patch("hermes_cli.config.load_config", fake_load_config),
|
||||
patch("agent.auxiliary_client._try_codex", return_value=(codex_client, "gpt-5.2-codex")) as mock_codex,
|
||||
patch("agent.auxiliary_client._try_openrouter") as mock_openrouter,
|
||||
patch("agent.auxiliary_client._try_nous") as mock_nous,
|
||||
patch("agent.auxiliary_client._try_anthropic") as mock_anthropic,
|
||||
patch("agent.auxiliary_client._try_custom_endpoint") as mock_custom,
|
||||
):
|
||||
provider, client, model = resolve_vision_provider_client()
|
||||
|
||||
assert provider == "openai-codex"
|
||||
assert client is codex_client
|
||||
assert model == "gpt-5.2-codex"
|
||||
mock_codex.assert_called_once()
|
||||
mock_openrouter.assert_not_called()
|
||||
mock_nous.assert_not_called()
|
||||
mock_anthropic.assert_not_called()
|
||||
mock_custom.assert_not_called()
|
||||
# OpenRouter should win over anthropic active provider
|
||||
assert provider == "openrouter"
|
||||
|
||||
def test_vision_auto_includes_codex(self, codex_auth_dir):
|
||||
"""Codex supports vision (gpt-5.3-codex), so auto mode should use it."""
|
||||
with patch("agent.auxiliary_client._read_nous_auth", return_value=None), \
|
||||
patch("agent.auxiliary_client.OpenAI"):
|
||||
client, model = get_vision_auxiliary_client()
|
||||
from agent.auxiliary_client import CodexAuxiliaryClient
|
||||
assert isinstance(client, CodexAuxiliaryClient)
|
||||
assert model == "gpt-5.2-codex"
|
||||
|
||||
def test_vision_auto_falls_back_to_custom_endpoint(self, monkeypatch):
|
||||
"""Custom endpoint is used as fallback in vision auto mode.
|
||||
|
||||
Many local models (Qwen-VL, LLaVA, etc.) support vision.
|
||||
When no OpenRouter/Nous/Codex is available, try the custom endpoint.
|
||||
"""
|
||||
def test_vision_auto_uses_named_custom_as_active_provider(self, monkeypatch):
|
||||
"""Named custom provider works as active provider fallback in vision auto."""
|
||||
monkeypatch.delenv("OPENROUTER_API_KEY", raising=False)
|
||||
monkeypatch.delenv("ANTHROPIC_API_KEY", raising=False)
|
||||
with patch("agent.auxiliary_client._read_nous_auth", return_value=None), \
|
||||
patch("agent.auxiliary_client._select_pool_entry", return_value=(False, None)), \
|
||||
patch("agent.auxiliary_client._read_codex_access_token", return_value=None), \
|
||||
patch("agent.auxiliary_client._resolve_custom_runtime",
|
||||
return_value=("http://localhost:1234/v1", "local-key")), \
|
||||
patch("agent.auxiliary_client.OpenAI") as mock_openai:
|
||||
client, model = get_vision_auxiliary_client()
|
||||
assert client is not None # Custom endpoint picked up as fallback
|
||||
patch("agent.auxiliary_client._read_main_provider", return_value="custom:local"), \
|
||||
patch("agent.auxiliary_client._read_main_model", return_value="my-local-model"), \
|
||||
patch("agent.auxiliary_client.resolve_provider_client",
|
||||
return_value=(MagicMock(), "my-local-model")) as mock_resolve:
|
||||
provider, client, model = resolve_vision_provider_client()
|
||||
assert client is not None
|
||||
assert provider == "custom:local"
|
||||
|
||||
def test_vision_direct_endpoint_override(self, monkeypatch):
|
||||
monkeypatch.setenv("OPENROUTER_API_KEY", "or-key")
|
||||
@@ -822,6 +804,31 @@ class TestAuxiliaryPoolAwareness:
|
||||
assert model == "google/gemini-3-flash-preview"
|
||||
assert client is not None
|
||||
|
||||
def test_vision_config_google_provider_uses_gemini_credentials(self, monkeypatch):
|
||||
config = {
|
||||
"auxiliary": {
|
||||
"vision": {
|
||||
"provider": "google",
|
||||
"model": "gemini-3.1-pro-preview",
|
||||
}
|
||||
}
|
||||
}
|
||||
monkeypatch.setattr("hermes_cli.config.load_config", lambda: config)
|
||||
with (
|
||||
patch("hermes_cli.auth.resolve_api_key_provider_credentials", return_value={
|
||||
"api_key": "gemini-key",
|
||||
"base_url": "https://generativelanguage.googleapis.com/v1beta/openai",
|
||||
}),
|
||||
patch("agent.auxiliary_client.OpenAI") as mock_openai,
|
||||
):
|
||||
resolved_provider, client, model = resolve_vision_provider_client()
|
||||
|
||||
assert resolved_provider == "gemini"
|
||||
assert client is not None
|
||||
assert model == "gemini-3.1-pro-preview"
|
||||
assert mock_openai.call_args.kwargs["api_key"] == "gemini-key"
|
||||
assert mock_openai.call_args.kwargs["base_url"] == "https://generativelanguage.googleapis.com/v1beta/openai"
|
||||
|
||||
def test_vision_forced_main_uses_custom_endpoint(self, monkeypatch):
|
||||
"""When explicitly forced to 'main', vision CAN use custom endpoint."""
|
||||
config = {
|
||||
@@ -846,7 +853,14 @@ class TestAuxiliaryPoolAwareness:
|
||||
monkeypatch.setenv("AUXILIARY_VISION_PROVIDER", "main")
|
||||
monkeypatch.delenv("OPENAI_BASE_URL", raising=False)
|
||||
monkeypatch.delenv("OPENAI_API_KEY", raising=False)
|
||||
# Clear client cache to avoid stale entries from previous tests
|
||||
from agent.auxiliary_client import _client_cache
|
||||
_client_cache.clear()
|
||||
with patch("agent.auxiliary_client._read_nous_auth", return_value=None), \
|
||||
patch("agent.auxiliary_client._read_main_provider", return_value=""), \
|
||||
patch("agent.auxiliary_client._read_main_model", return_value=""), \
|
||||
patch("agent.auxiliary_client._select_pool_entry", return_value=(False, None)), \
|
||||
patch("agent.auxiliary_client._resolve_custom_runtime", return_value=(None, None)), \
|
||||
patch("agent.auxiliary_client._read_codex_access_token", return_value=None), \
|
||||
patch("agent.auxiliary_client._resolve_api_key_provider", return_value=(None, None)):
|
||||
client, model = get_vision_auxiliary_client()
|
||||
|
||||
@@ -0,0 +1,42 @@
|
||||
"""Tests for MiniMax auxiliary client URL normalization.
|
||||
|
||||
MiniMax and MiniMax-CN set inference_base_url to the /anthropic path.
|
||||
The auxiliary client uses the OpenAI SDK, which needs /v1 instead.
|
||||
"""
|
||||
|
||||
import sys
|
||||
import os
|
||||
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(__file__), "..", ".."))
|
||||
|
||||
from agent.auxiliary_client import _to_openai_base_url
|
||||
|
||||
|
||||
class TestToOpenaiBaseUrl:
|
||||
def test_minimax_global_anthropic_suffix_replaced(self):
|
||||
assert _to_openai_base_url("https://api.minimax.io/anthropic") == "https://api.minimax.io/v1"
|
||||
|
||||
def test_minimax_cn_anthropic_suffix_replaced(self):
|
||||
assert _to_openai_base_url("https://api.minimaxi.com/anthropic") == "https://api.minimaxi.com/v1"
|
||||
|
||||
def test_trailing_slash_stripped_before_replace(self):
|
||||
assert _to_openai_base_url("https://api.minimax.io/anthropic/") == "https://api.minimax.io/v1"
|
||||
|
||||
def test_v1_url_unchanged(self):
|
||||
assert _to_openai_base_url("https://api.openai.com/v1") == "https://api.openai.com/v1"
|
||||
|
||||
def test_openrouter_url_unchanged(self):
|
||||
assert _to_openai_base_url("https://openrouter.ai/api/v1") == "https://openrouter.ai/api/v1"
|
||||
|
||||
def test_anthropic_domain_unchanged(self):
|
||||
"""api.anthropic.com doesn't end with /anthropic — should be untouched."""
|
||||
assert _to_openai_base_url("https://api.anthropic.com") == "https://api.anthropic.com"
|
||||
|
||||
def test_anthropic_in_subpath_unchanged(self):
|
||||
assert _to_openai_base_url("https://example.com/anthropic/extra") == "https://example.com/anthropic/extra"
|
||||
|
||||
def test_empty_string(self):
|
||||
assert _to_openai_base_url("") == ""
|
||||
|
||||
def test_none(self):
|
||||
assert _to_openai_base_url(None) == ""
|
||||
@@ -0,0 +1,105 @@
|
||||
"""Tests for MiniMax provider hardening — context lengths, thinking guard, catalog."""
|
||||
|
||||
|
||||
class TestMinimaxContextLengths:
|
||||
"""Verify per-model context length entries for MiniMax models."""
|
||||
|
||||
def test_m1_variants_have_1m_context(self):
|
||||
from agent.model_metadata import DEFAULT_CONTEXT_LENGTHS
|
||||
# Keys are lowercase because the lookup lowercases model names
|
||||
for model in ("minimax-m1", "minimax-m1-40k", "minimax-m1-80k",
|
||||
"minimax-m1-128k", "minimax-m1-256k"):
|
||||
assert model in DEFAULT_CONTEXT_LENGTHS, f"{model} missing from context lengths"
|
||||
assert DEFAULT_CONTEXT_LENGTHS[model] == 1_000_000, f"{model} expected 1M"
|
||||
|
||||
def test_m2_variants_have_1m_context(self):
|
||||
from agent.model_metadata import DEFAULT_CONTEXT_LENGTHS
|
||||
# Keys are lowercase because the lookup lowercases model names
|
||||
for model in ("minimax-m2.5", "minimax-m2.7"):
|
||||
assert model in DEFAULT_CONTEXT_LENGTHS, f"{model} missing from context lengths"
|
||||
assert DEFAULT_CONTEXT_LENGTHS[model] == 1_048_576, f"{model} expected 1048576"
|
||||
|
||||
def test_minimax_prefix_fallback(self):
|
||||
from agent.model_metadata import DEFAULT_CONTEXT_LENGTHS
|
||||
# The generic "minimax" prefix entry should be 1M for unknown models
|
||||
assert DEFAULT_CONTEXT_LENGTHS["minimax"] == 1_048_576
|
||||
|
||||
|
||||
|
||||
class TestMinimaxThinkingGuard:
|
||||
"""Verify that build_anthropic_kwargs does NOT add thinking params for MiniMax models."""
|
||||
|
||||
def test_no_thinking_for_minimax_m27(self):
|
||||
from agent.anthropic_adapter import build_anthropic_kwargs
|
||||
kwargs = build_anthropic_kwargs(
|
||||
model="MiniMax-M2.7",
|
||||
messages=[{"role": "user", "content": "hello"}],
|
||||
tools=None,
|
||||
max_tokens=4096,
|
||||
reasoning_config={"enabled": True, "effort": "medium"},
|
||||
)
|
||||
assert "thinking" not in kwargs
|
||||
assert "output_config" not in kwargs
|
||||
|
||||
def test_no_thinking_for_minimax_m1(self):
|
||||
from agent.anthropic_adapter import build_anthropic_kwargs
|
||||
kwargs = build_anthropic_kwargs(
|
||||
model="MiniMax-M1-128k",
|
||||
messages=[{"role": "user", "content": "hello"}],
|
||||
tools=None,
|
||||
max_tokens=4096,
|
||||
reasoning_config={"enabled": True, "effort": "high"},
|
||||
)
|
||||
assert "thinking" not in kwargs
|
||||
|
||||
def test_thinking_still_works_for_claude(self):
|
||||
from agent.anthropic_adapter import build_anthropic_kwargs
|
||||
kwargs = build_anthropic_kwargs(
|
||||
model="claude-sonnet-4-20250514",
|
||||
messages=[{"role": "user", "content": "hello"}],
|
||||
tools=None,
|
||||
max_tokens=4096,
|
||||
reasoning_config={"enabled": True, "effort": "medium"},
|
||||
)
|
||||
assert "thinking" in kwargs
|
||||
|
||||
|
||||
class TestMinimaxAuxModel:
|
||||
"""Verify auxiliary model is standard (not highspeed)."""
|
||||
|
||||
def test_minimax_aux_is_standard(self):
|
||||
from agent.auxiliary_client import _API_KEY_PROVIDER_AUX_MODELS
|
||||
assert _API_KEY_PROVIDER_AUX_MODELS["minimax"] == "MiniMax-M2.7"
|
||||
assert _API_KEY_PROVIDER_AUX_MODELS["minimax-cn"] == "MiniMax-M2.7"
|
||||
|
||||
def test_minimax_aux_not_highspeed(self):
|
||||
from agent.auxiliary_client import _API_KEY_PROVIDER_AUX_MODELS
|
||||
assert "highspeed" not in _API_KEY_PROVIDER_AUX_MODELS["minimax"]
|
||||
assert "highspeed" not in _API_KEY_PROVIDER_AUX_MODELS["minimax-cn"]
|
||||
|
||||
|
||||
class TestMinimaxModelCatalog:
|
||||
"""Verify the model catalog includes M1 family and excludes deprecated models."""
|
||||
|
||||
def test_catalog_includes_m1_family(self):
|
||||
from hermes_cli.models import _PROVIDER_MODELS
|
||||
for provider in ("minimax", "minimax-cn"):
|
||||
models = _PROVIDER_MODELS[provider]
|
||||
assert "MiniMax-M1" in models
|
||||
assert "MiniMax-M1-40k" in models
|
||||
assert "MiniMax-M1-80k" in models
|
||||
assert "MiniMax-M1-128k" in models
|
||||
assert "MiniMax-M1-256k" in models
|
||||
|
||||
def test_catalog_excludes_deprecated(self):
|
||||
from hermes_cli.models import _PROVIDER_MODELS
|
||||
for provider in ("minimax", "minimax-cn"):
|
||||
models = _PROVIDER_MODELS[provider]
|
||||
assert "MiniMax-M2.1" not in models
|
||||
|
||||
def test_catalog_excludes_highspeed(self):
|
||||
from hermes_cli.models import _PROVIDER_MODELS
|
||||
for provider in ("minimax", "minimax-cn"):
|
||||
models = _PROVIDER_MODELS[provider]
|
||||
assert "MiniMax-M2.7-highspeed" not in models
|
||||
assert "MiniMax-M2.5-highspeed" not in models
|
||||
@@ -0,0 +1,66 @@
|
||||
import pytest
|
||||
from unittest.mock import MagicMock, patch
|
||||
from hermes_cli.plugins import VALID_HOOKS, PluginManager
|
||||
import os
|
||||
import shutil
|
||||
import tempfile
|
||||
from cli import HermesCLI
|
||||
|
||||
|
||||
def test_session_hooks_in_valid_hooks():
|
||||
"""Verify on_session_finalize and on_session_reset are registered as valid hooks."""
|
||||
assert "on_session_finalize" in VALID_HOOKS
|
||||
assert "on_session_reset" in VALID_HOOKS
|
||||
|
||||
|
||||
@patch("hermes_cli.plugins.invoke_hook")
|
||||
def test_session_finalize_on_reset(mock_invoke_hook):
|
||||
"""Verify on_session_finalize fires when /new or /reset is used."""
|
||||
cli = HermesCLI()
|
||||
cli.agent = MagicMock()
|
||||
cli.agent.session_id = "test-session-id"
|
||||
|
||||
# Simulate /new command which triggers on_session_finalize for the old session
|
||||
cli.new_session(silent=True)
|
||||
|
||||
# Check if on_session_finalize was called for the old session
|
||||
mock_invoke_hook.assert_any_call(
|
||||
"on_session_finalize", session_id="test-session-id", platform="cli"
|
||||
)
|
||||
# Check if on_session_reset was called for the new session
|
||||
mock_invoke_hook.assert_any_call(
|
||||
"on_session_reset", session_id=cli.session_id, platform="cli"
|
||||
)
|
||||
|
||||
|
||||
@patch("hermes_cli.plugins.invoke_hook")
|
||||
def test_session_finalize_on_cleanup(mock_invoke_hook):
|
||||
"""Verify on_session_finalize fires during CLI exit cleanup."""
|
||||
import cli as cli_mod
|
||||
|
||||
mock_agent = MagicMock()
|
||||
mock_agent.session_id = "cleanup-session-id"
|
||||
cli_mod._active_agent_ref = mock_agent
|
||||
cli_mod._cleanup_done = False
|
||||
|
||||
cli_mod._run_cleanup()
|
||||
|
||||
mock_invoke_hook.assert_any_call(
|
||||
"on_session_finalize", session_id="cleanup-session-id", platform="cli"
|
||||
)
|
||||
|
||||
|
||||
@patch("hermes_cli.plugins.invoke_hook")
|
||||
def test_hook_errors_are_caught(mock_invoke_hook):
|
||||
"""Verify hook exceptions are caught and don't crash the agent."""
|
||||
mgr = PluginManager()
|
||||
|
||||
# Register a hook that raises
|
||||
def bad_callback(**kwargs):
|
||||
raise Exception("Hook failed")
|
||||
|
||||
mgr._hooks["on_session_finalize"] = [bad_callback]
|
||||
|
||||
# This should not raise
|
||||
results = mgr.invoke_hook("on_session_finalize", session_id="test", platform="cli")
|
||||
assert results == []
|
||||
+231
-24
@@ -33,6 +33,13 @@ def git_repo(tmp_path):
|
||||
["git", "commit", "-m", "Initial commit"],
|
||||
cwd=repo, capture_output=True,
|
||||
)
|
||||
# Add a fake remote ref so cleanup logic sees the initial commit as
|
||||
# "pushed". Without this, `git log HEAD --not --remotes` treats every
|
||||
# commit as unpushed and cleanup refuses to delete worktrees.
|
||||
subprocess.run(
|
||||
["git", "update-ref", "refs/remotes/origin/main", "HEAD"],
|
||||
cwd=repo, capture_output=True,
|
||||
)
|
||||
return repo
|
||||
|
||||
|
||||
@@ -81,7 +88,11 @@ def _setup_worktree(repo_root):
|
||||
|
||||
|
||||
def _cleanup_worktree(info):
|
||||
"""Test version of _cleanup_worktree."""
|
||||
"""Test version of _cleanup_worktree.
|
||||
|
||||
Preserves the worktree only if it has unpushed commits.
|
||||
Dirty working tree alone is not enough to keep it.
|
||||
"""
|
||||
wt_path = info["path"]
|
||||
branch = info["branch"]
|
||||
repo_root = info["repo_root"]
|
||||
@@ -89,15 +100,15 @@ def _cleanup_worktree(info):
|
||||
if not Path(wt_path).exists():
|
||||
return
|
||||
|
||||
# Check for uncommitted changes
|
||||
status = subprocess.run(
|
||||
["git", "status", "--porcelain"],
|
||||
# Check for unpushed commits
|
||||
result = subprocess.run(
|
||||
["git", "log", "--oneline", "HEAD", "--not", "--remotes"],
|
||||
capture_output=True, text=True, timeout=10, cwd=wt_path,
|
||||
)
|
||||
has_changes = bool(status.stdout.strip())
|
||||
has_unpushed = bool(result.stdout.strip())
|
||||
|
||||
if has_changes:
|
||||
return False # Did not clean up
|
||||
if has_unpushed:
|
||||
return False # Did not clean up — has unpushed commits
|
||||
|
||||
subprocess.run(
|
||||
["git", "worktree", "remove", wt_path, "--force"],
|
||||
@@ -204,20 +215,45 @@ class TestWorktreeCleanup:
|
||||
assert result is True
|
||||
assert not Path(info["path"]).exists()
|
||||
|
||||
def test_dirty_worktree_kept(self, git_repo):
|
||||
def test_dirty_worktree_cleaned_when_no_unpushed(self, git_repo):
|
||||
"""Dirty working tree without unpushed commits is cleaned up.
|
||||
|
||||
Agent sessions typically leave untracked files / artifacts behind.
|
||||
Since all real work is in pushed commits, these don't warrant
|
||||
keeping the worktree.
|
||||
"""
|
||||
info = _setup_worktree(str(git_repo))
|
||||
assert info is not None
|
||||
|
||||
# Make uncommitted changes
|
||||
# Make uncommitted changes (untracked file)
|
||||
(Path(info["path"]) / "new-file.txt").write_text("uncommitted")
|
||||
subprocess.run(
|
||||
["git", "add", "new-file.txt"],
|
||||
cwd=info["path"], capture_output=True,
|
||||
)
|
||||
|
||||
# The git_repo fixture already has a fake remote ref so the initial
|
||||
# commit is seen as "pushed". No unpushed commits → cleanup proceeds.
|
||||
result = _cleanup_worktree(info)
|
||||
assert result is False
|
||||
assert Path(info["path"]).exists() # Still there
|
||||
assert result is True # Cleaned up despite dirty working tree
|
||||
assert not Path(info["path"]).exists()
|
||||
|
||||
def test_worktree_with_unpushed_commits_kept(self, git_repo):
|
||||
"""Worktree with unpushed commits is preserved."""
|
||||
info = _setup_worktree(str(git_repo))
|
||||
assert info is not None
|
||||
|
||||
# Make a commit that is NOT on any remote
|
||||
(Path(info["path"]) / "work.txt").write_text("real work")
|
||||
subprocess.run(["git", "add", "work.txt"], cwd=info["path"], capture_output=True)
|
||||
subprocess.run(
|
||||
["git", "commit", "-m", "agent work"],
|
||||
cwd=info["path"], capture_output=True,
|
||||
)
|
||||
|
||||
result = _cleanup_worktree(info)
|
||||
assert result is False # Kept — has unpushed commits
|
||||
assert Path(info["path"]).exists()
|
||||
|
||||
def test_branch_deleted_on_cleanup(self, git_repo):
|
||||
info = _setup_worktree(str(git_repo))
|
||||
@@ -367,7 +403,7 @@ class TestMultipleWorktrees:
|
||||
lines = [l for l in result.stdout.strip().splitlines() if l.strip()]
|
||||
assert len(lines) == 11
|
||||
|
||||
# Cleanup all
|
||||
# Cleanup all (git_repo fixture has a fake remote ref so cleanup works)
|
||||
for info in worktrees:
|
||||
# Discard changes first so cleanup works
|
||||
subprocess.run(
|
||||
@@ -492,33 +528,77 @@ class TestStaleWorktreePruning:
|
||||
assert not pruned
|
||||
assert Path(info["path"]).exists()
|
||||
|
||||
def test_keeps_dirty_old_worktree(self, git_repo):
|
||||
"""Old worktrees with uncommitted changes should NOT be pruned."""
|
||||
def test_keeps_old_worktree_with_unpushed_commits(self, git_repo):
|
||||
"""Old worktrees (24-72h) with unpushed commits should NOT be pruned."""
|
||||
import time
|
||||
|
||||
info = _setup_worktree(str(git_repo))
|
||||
assert info is not None
|
||||
|
||||
# Make it dirty
|
||||
(Path(info["path"]) / "dirty.txt").write_text("uncommitted")
|
||||
# Make an unpushed commit
|
||||
(Path(info["path"]) / "work.txt").write_text("real work")
|
||||
subprocess.run(["git", "add", "work.txt"], cwd=info["path"], capture_output=True)
|
||||
subprocess.run(
|
||||
["git", "add", "dirty.txt"],
|
||||
["git", "commit", "-m", "agent work"],
|
||||
cwd=info["path"], capture_output=True,
|
||||
)
|
||||
|
||||
# Make it old
|
||||
# Make it old (25h — in the 24-72h soft tier)
|
||||
old_time = time.time() - (25 * 3600)
|
||||
os.utime(info["path"], (old_time, old_time))
|
||||
|
||||
# Check if it would be pruned
|
||||
status = subprocess.run(
|
||||
["git", "status", "--porcelain"],
|
||||
# Check for unpushed commits (simulates prune logic)
|
||||
result = subprocess.run(
|
||||
["git", "log", "--oneline", "HEAD", "--not", "--remotes"],
|
||||
capture_output=True, text=True, cwd=info["path"],
|
||||
)
|
||||
has_changes = bool(status.stdout.strip())
|
||||
assert has_changes # Should be dirty → not pruned
|
||||
has_unpushed = bool(result.stdout.strip())
|
||||
assert has_unpushed # Has unpushed commits → not pruned in soft tier
|
||||
assert Path(info["path"]).exists()
|
||||
|
||||
def test_force_prunes_very_old_worktree(self, git_repo):
|
||||
"""Worktrees older than 72h should be force-pruned regardless."""
|
||||
import time
|
||||
|
||||
info = _setup_worktree(str(git_repo))
|
||||
assert info is not None
|
||||
|
||||
# Make an unpushed commit (would normally protect it)
|
||||
(Path(info["path"]) / "work.txt").write_text("stale work")
|
||||
subprocess.run(["git", "add", "work.txt"], cwd=info["path"], capture_output=True)
|
||||
subprocess.run(
|
||||
["git", "commit", "-m", "old agent work"],
|
||||
cwd=info["path"], capture_output=True,
|
||||
)
|
||||
|
||||
# Make it very old (73h — beyond the 72h hard threshold)
|
||||
old_time = time.time() - (73 * 3600)
|
||||
os.utime(info["path"], (old_time, old_time))
|
||||
|
||||
# Simulate the force-prune tier check
|
||||
hard_cutoff = time.time() - (72 * 3600)
|
||||
mtime = Path(info["path"]).stat().st_mtime
|
||||
assert mtime <= hard_cutoff # Should qualify for force removal
|
||||
|
||||
# Actually remove it (simulates _prune_stale_worktrees force path)
|
||||
branch_result = subprocess.run(
|
||||
["git", "branch", "--show-current"],
|
||||
capture_output=True, text=True, timeout=5, cwd=info["path"],
|
||||
)
|
||||
branch = branch_result.stdout.strip()
|
||||
|
||||
subprocess.run(
|
||||
["git", "worktree", "remove", info["path"], "--force"],
|
||||
capture_output=True, text=True, timeout=15, cwd=str(git_repo),
|
||||
)
|
||||
if branch:
|
||||
subprocess.run(
|
||||
["git", "branch", "-D", branch],
|
||||
capture_output=True, text=True, timeout=10, cwd=str(git_repo),
|
||||
)
|
||||
|
||||
assert not Path(info["path"]).exists()
|
||||
|
||||
|
||||
class TestEdgeCases:
|
||||
"""Test edge cases for robustness."""
|
||||
@@ -611,6 +691,133 @@ class TestTerminalCWDIntegration:
|
||||
assert result.stdout.strip() == "true"
|
||||
|
||||
|
||||
class TestOrphanedBranchPruning:
|
||||
"""Test cleanup of orphaned hermes/* and pr-* branches."""
|
||||
|
||||
def test_prunes_orphaned_hermes_branch(self, git_repo):
|
||||
"""hermes/hermes-* branches with no worktree should be deleted."""
|
||||
# Create a branch that looks like a worktree branch but has no worktree
|
||||
subprocess.run(
|
||||
["git", "branch", "hermes/hermes-deadbeef", "HEAD"],
|
||||
cwd=str(git_repo), capture_output=True,
|
||||
)
|
||||
|
||||
# Verify it exists
|
||||
result = subprocess.run(
|
||||
["git", "branch", "--list", "hermes/hermes-deadbeef"],
|
||||
capture_output=True, text=True, cwd=str(git_repo),
|
||||
)
|
||||
assert "hermes/hermes-deadbeef" in result.stdout
|
||||
|
||||
# Simulate _prune_orphaned_branches logic
|
||||
result = subprocess.run(
|
||||
["git", "branch", "--format=%(refname:short)"],
|
||||
capture_output=True, text=True, cwd=str(git_repo),
|
||||
)
|
||||
all_branches = [b.strip() for b in result.stdout.strip().split("\n") if b.strip()]
|
||||
|
||||
wt_result = subprocess.run(
|
||||
["git", "worktree", "list", "--porcelain"],
|
||||
capture_output=True, text=True, cwd=str(git_repo),
|
||||
)
|
||||
active_branches = {"main"}
|
||||
for line in wt_result.stdout.split("\n"):
|
||||
if line.startswith("branch refs/heads/"):
|
||||
active_branches.add(line.split("branch refs/heads/", 1)[-1].strip())
|
||||
|
||||
orphaned = [
|
||||
b for b in all_branches
|
||||
if b not in active_branches
|
||||
and (b.startswith("hermes/hermes-") or b.startswith("pr-"))
|
||||
]
|
||||
assert "hermes/hermes-deadbeef" in orphaned
|
||||
|
||||
# Delete them
|
||||
if orphaned:
|
||||
subprocess.run(
|
||||
["git", "branch", "-D"] + orphaned,
|
||||
capture_output=True, text=True, cwd=str(git_repo),
|
||||
)
|
||||
|
||||
# Verify gone
|
||||
result = subprocess.run(
|
||||
["git", "branch", "--list", "hermes/hermes-deadbeef"],
|
||||
capture_output=True, text=True, cwd=str(git_repo),
|
||||
)
|
||||
assert "hermes/hermes-deadbeef" not in result.stdout
|
||||
|
||||
def test_prunes_orphaned_pr_branch(self, git_repo):
|
||||
"""pr-* branches should be deleted during pruning."""
|
||||
subprocess.run(
|
||||
["git", "branch", "pr-1234", "HEAD"],
|
||||
cwd=str(git_repo), capture_output=True,
|
||||
)
|
||||
subprocess.run(
|
||||
["git", "branch", "pr-5678", "HEAD"],
|
||||
cwd=str(git_repo), capture_output=True,
|
||||
)
|
||||
|
||||
result = subprocess.run(
|
||||
["git", "branch", "--format=%(refname:short)"],
|
||||
capture_output=True, text=True, cwd=str(git_repo),
|
||||
)
|
||||
all_branches = [b.strip() for b in result.stdout.strip().split("\n") if b.strip()]
|
||||
|
||||
active_branches = {"main"}
|
||||
orphaned = [
|
||||
b for b in all_branches
|
||||
if b not in active_branches and b.startswith("pr-")
|
||||
]
|
||||
assert "pr-1234" in orphaned
|
||||
assert "pr-5678" in orphaned
|
||||
|
||||
subprocess.run(
|
||||
["git", "branch", "-D"] + orphaned,
|
||||
capture_output=True, text=True, cwd=str(git_repo),
|
||||
)
|
||||
|
||||
# Verify gone
|
||||
result = subprocess.run(
|
||||
["git", "branch", "--format=%(refname:short)"],
|
||||
capture_output=True, text=True, cwd=str(git_repo),
|
||||
)
|
||||
remaining = result.stdout.strip()
|
||||
assert "pr-1234" not in remaining
|
||||
assert "pr-5678" not in remaining
|
||||
|
||||
def test_preserves_active_worktree_branch(self, git_repo):
|
||||
"""Branches with active worktrees should NOT be pruned."""
|
||||
info = _setup_worktree(str(git_repo))
|
||||
assert info is not None
|
||||
|
||||
result = subprocess.run(
|
||||
["git", "worktree", "list", "--porcelain"],
|
||||
capture_output=True, text=True, cwd=str(git_repo),
|
||||
)
|
||||
active_branches = set()
|
||||
for line in result.stdout.split("\n"):
|
||||
if line.startswith("branch refs/heads/"):
|
||||
active_branches.add(line.split("branch refs/heads/", 1)[-1].strip())
|
||||
|
||||
assert info["branch"] in active_branches # Protected
|
||||
|
||||
def test_preserves_main_branch(self, git_repo):
|
||||
"""main branch should never be pruned."""
|
||||
result = subprocess.run(
|
||||
["git", "branch", "--format=%(refname:short)"],
|
||||
capture_output=True, text=True, cwd=str(git_repo),
|
||||
)
|
||||
all_branches = [b.strip() for b in result.stdout.strip().split("\n") if b.strip()]
|
||||
active_branches = {"main"}
|
||||
|
||||
orphaned = [
|
||||
b for b in all_branches
|
||||
if b not in active_branches
|
||||
and (b.startswith("hermes/hermes-") or b.startswith("pr-"))
|
||||
]
|
||||
assert "main" not in orphaned
|
||||
|
||||
|
||||
class TestSystemPromptInjection:
|
||||
"""Test that the agent gets worktree context in its system prompt."""
|
||||
|
||||
@@ -625,7 +832,7 @@ class TestSystemPromptInjection:
|
||||
f"{info['path']}. Your branch is `{info['branch']}`. "
|
||||
f"Changes here do not affect the main working tree or other agents. "
|
||||
f"Remember to commit and push your changes, and create a PR if appropriate. "
|
||||
f"The original repo is at {info['repo_root']}.]"
|
||||
f"The original repo is at {info['repo_root']}.]\n"
|
||||
)
|
||||
|
||||
assert info["path"] in wt_note
|
||||
|
||||
@@ -339,6 +339,36 @@ class TestMarkJobRun:
|
||||
assert updated["last_status"] == "error"
|
||||
assert updated["last_error"] == "timeout"
|
||||
|
||||
def test_delivery_error_tracked_separately(self, tmp_cron_dir):
|
||||
"""Agent succeeds but delivery fails — both tracked independently."""
|
||||
job = create_job(prompt="Report", schedule="every 1h")
|
||||
mark_job_run(job["id"], success=True, delivery_error="platform 'telegram' not configured")
|
||||
updated = get_job(job["id"])
|
||||
assert updated["last_status"] == "ok"
|
||||
assert updated["last_error"] is None
|
||||
assert updated["last_delivery_error"] == "platform 'telegram' not configured"
|
||||
|
||||
def test_delivery_error_cleared_on_success(self, tmp_cron_dir):
|
||||
"""Successful delivery clears the previous delivery error."""
|
||||
job = create_job(prompt="Report", schedule="every 1h")
|
||||
mark_job_run(job["id"], success=True, delivery_error="network timeout")
|
||||
updated = get_job(job["id"])
|
||||
assert updated["last_delivery_error"] == "network timeout"
|
||||
# Next run delivers successfully
|
||||
mark_job_run(job["id"], success=True, delivery_error=None)
|
||||
updated = get_job(job["id"])
|
||||
assert updated["last_delivery_error"] is None
|
||||
|
||||
def test_both_agent_and_delivery_error(self, tmp_cron_dir):
|
||||
"""Agent fails AND delivery fails — both errors recorded."""
|
||||
job = create_job(prompt="Report", schedule="every 1h")
|
||||
mark_job_run(job["id"], success=False, error="model timeout",
|
||||
delivery_error="platform 'discord' not enabled")
|
||||
updated = get_job(job["id"])
|
||||
assert updated["last_status"] == "error"
|
||||
assert updated["last_error"] == "model timeout"
|
||||
assert updated["last_delivery_error"] == "platform 'discord' not enabled"
|
||||
|
||||
|
||||
class TestAdvanceNextRun:
|
||||
"""Tests for advance_next_run() — crash-safety for recurring jobs."""
|
||||
|
||||
@@ -508,6 +508,90 @@ class TestDeliverResultWrapping:
|
||||
assert send_mock.call_args.kwargs["thread_id"] == "17585"
|
||||
|
||||
|
||||
class TestDeliverResultErrorReturns:
|
||||
"""Verify _deliver_result returns error strings on failure, None on success."""
|
||||
|
||||
def test_returns_none_on_successful_delivery(self):
|
||||
from gateway.config import Platform
|
||||
|
||||
pconfig = MagicMock()
|
||||
pconfig.enabled = True
|
||||
mock_cfg = MagicMock()
|
||||
mock_cfg.platforms = {Platform.TELEGRAM: pconfig}
|
||||
|
||||
with patch("gateway.config.load_gateway_config", return_value=mock_cfg), \
|
||||
patch("tools.send_message_tool._send_to_platform", new=AsyncMock(return_value={"success": True})):
|
||||
job = {
|
||||
"id": "ok-job",
|
||||
"deliver": "origin",
|
||||
"origin": {"platform": "telegram", "chat_id": "123"},
|
||||
}
|
||||
result = _deliver_result(job, "Output.")
|
||||
assert result is None
|
||||
|
||||
def test_returns_none_for_local_delivery(self):
|
||||
"""local-only jobs don't deliver — not a failure."""
|
||||
job = {"id": "local-job", "deliver": "local"}
|
||||
result = _deliver_result(job, "Output.")
|
||||
assert result is None
|
||||
|
||||
def test_returns_error_for_unknown_platform(self):
|
||||
job = {
|
||||
"id": "bad-platform",
|
||||
"deliver": "origin",
|
||||
"origin": {"platform": "fax", "chat_id": "123"},
|
||||
}
|
||||
with patch("gateway.config.load_gateway_config"):
|
||||
result = _deliver_result(job, "Output.")
|
||||
assert result is not None
|
||||
assert "unknown platform" in result
|
||||
|
||||
def test_returns_error_when_platform_disabled(self):
|
||||
from gateway.config import Platform
|
||||
|
||||
pconfig = MagicMock()
|
||||
pconfig.enabled = False
|
||||
mock_cfg = MagicMock()
|
||||
mock_cfg.platforms = {Platform.TELEGRAM: pconfig}
|
||||
|
||||
with patch("gateway.config.load_gateway_config", return_value=mock_cfg):
|
||||
job = {
|
||||
"id": "disabled",
|
||||
"deliver": "origin",
|
||||
"origin": {"platform": "telegram", "chat_id": "123"},
|
||||
}
|
||||
result = _deliver_result(job, "Output.")
|
||||
assert result is not None
|
||||
assert "not configured" in result
|
||||
|
||||
def test_returns_error_on_send_failure(self):
|
||||
from gateway.config import Platform
|
||||
|
||||
pconfig = MagicMock()
|
||||
pconfig.enabled = True
|
||||
mock_cfg = MagicMock()
|
||||
mock_cfg.platforms = {Platform.TELEGRAM: pconfig}
|
||||
|
||||
with patch("gateway.config.load_gateway_config", return_value=mock_cfg), \
|
||||
patch("tools.send_message_tool._send_to_platform", new=AsyncMock(return_value={"error": "rate limited"})):
|
||||
job = {
|
||||
"id": "rate-limited",
|
||||
"deliver": "origin",
|
||||
"origin": {"platform": "telegram", "chat_id": "123"},
|
||||
}
|
||||
result = _deliver_result(job, "Output.")
|
||||
assert result is not None
|
||||
assert "rate limited" in result
|
||||
|
||||
def test_returns_error_for_unresolved_target(self, monkeypatch):
|
||||
"""Non-local delivery with no resolvable target should return an error."""
|
||||
monkeypatch.delenv("TELEGRAM_HOME_CHANNEL", raising=False)
|
||||
job = {"id": "no-target", "deliver": "telegram"}
|
||||
result = _deliver_result(job, "Output.")
|
||||
assert result is not None
|
||||
assert "no delivery target" in result
|
||||
|
||||
|
||||
class TestRunJobSessionPersistence:
|
||||
def test_run_job_passes_session_db_and_cron_platform(self, tmp_path):
|
||||
job = {
|
||||
|
||||
@@ -0,0 +1,432 @@
|
||||
"""Tests for Feishu interactive card approval buttons."""
|
||||
|
||||
import asyncio
|
||||
import json
|
||||
import os
|
||||
import sys
|
||||
from pathlib import Path
|
||||
from types import SimpleNamespace
|
||||
from unittest.mock import AsyncMock, MagicMock, Mock, patch
|
||||
|
||||
import pytest
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# Ensure the repo root is importable
|
||||
# ---------------------------------------------------------------------------
|
||||
_repo = str(Path(__file__).resolve().parents[2])
|
||||
if _repo not in sys.path:
|
||||
sys.path.insert(0, _repo)
|
||||
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# Minimal Feishu mock so FeishuAdapter can be imported without lark-oapi
|
||||
# ---------------------------------------------------------------------------
|
||||
def _ensure_feishu_mocks():
|
||||
"""Provide stubs for lark-oapi / aiohttp.web so the import succeeds."""
|
||||
if "lark_oapi" not in sys.modules:
|
||||
mod = MagicMock()
|
||||
for name in (
|
||||
"lark_oapi", "lark_oapi.api.im.v1",
|
||||
"lark_oapi.event", "lark_oapi.event.callback_type",
|
||||
):
|
||||
sys.modules.setdefault(name, mod)
|
||||
if "aiohttp" not in sys.modules:
|
||||
aio = MagicMock()
|
||||
sys.modules.setdefault("aiohttp", aio)
|
||||
sys.modules.setdefault("aiohttp.web", aio.web)
|
||||
|
||||
|
||||
_ensure_feishu_mocks()
|
||||
|
||||
from gateway.config import PlatformConfig
|
||||
from gateway.platforms.feishu import FeishuAdapter
|
||||
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# Helpers
|
||||
# ---------------------------------------------------------------------------
|
||||
|
||||
def _make_adapter() -> FeishuAdapter:
|
||||
"""Create a FeishuAdapter with mocked internals."""
|
||||
config = PlatformConfig(enabled=True)
|
||||
adapter = FeishuAdapter(config)
|
||||
adapter._client = MagicMock()
|
||||
return adapter
|
||||
|
||||
|
||||
def _make_card_action_data(
|
||||
action_value: dict,
|
||||
chat_id: str = "oc_12345",
|
||||
open_id: str = "ou_user1",
|
||||
token: str = "tok_abc",
|
||||
) -> SimpleNamespace:
|
||||
"""Create a mock Feishu card action callback data object."""
|
||||
return SimpleNamespace(
|
||||
event=SimpleNamespace(
|
||||
token=token,
|
||||
context=SimpleNamespace(open_chat_id=chat_id),
|
||||
operator=SimpleNamespace(open_id=open_id),
|
||||
action=SimpleNamespace(
|
||||
tag="button",
|
||||
value=action_value,
|
||||
),
|
||||
),
|
||||
)
|
||||
|
||||
|
||||
# ===========================================================================
|
||||
# send_exec_approval — interactive card with buttons
|
||||
# ===========================================================================
|
||||
|
||||
class TestFeishuExecApproval:
|
||||
"""Test send_exec_approval sends an interactive card."""
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_sends_interactive_card(self):
|
||||
adapter = _make_adapter()
|
||||
|
||||
mock_response = SimpleNamespace(
|
||||
success=lambda: True,
|
||||
data=SimpleNamespace(message_id="msg_001"),
|
||||
)
|
||||
with patch.object(
|
||||
adapter, "_feishu_send_with_retry", new_callable=AsyncMock,
|
||||
return_value=mock_response,
|
||||
) as mock_send:
|
||||
result = await adapter.send_exec_approval(
|
||||
chat_id="oc_12345",
|
||||
command="rm -rf /important",
|
||||
session_key="agent:main:feishu:group:oc_12345",
|
||||
description="dangerous deletion",
|
||||
)
|
||||
|
||||
assert result.success is True
|
||||
assert result.message_id == "msg_001"
|
||||
|
||||
mock_send.assert_called_once()
|
||||
kwargs = mock_send.call_args[1]
|
||||
assert kwargs["chat_id"] == "oc_12345"
|
||||
assert kwargs["msg_type"] == "interactive"
|
||||
|
||||
# Verify card payload contains the command and buttons
|
||||
card = json.loads(kwargs["payload"])
|
||||
assert card["header"]["template"] == "orange"
|
||||
assert "rm -rf /important" in card["elements"][0]["content"]
|
||||
assert "dangerous deletion" in card["elements"][0]["content"]
|
||||
|
||||
# Check buttons
|
||||
actions = card["elements"][1]["actions"]
|
||||
assert len(actions) == 4
|
||||
action_names = [a["value"]["hermes_action"] for a in actions]
|
||||
assert action_names == [
|
||||
"approve_once", "approve_session", "approve_always", "deny"
|
||||
]
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_stores_approval_state(self):
|
||||
adapter = _make_adapter()
|
||||
|
||||
mock_response = SimpleNamespace(
|
||||
success=lambda: True,
|
||||
data=SimpleNamespace(message_id="msg_002"),
|
||||
)
|
||||
with patch.object(
|
||||
adapter, "_feishu_send_with_retry", new_callable=AsyncMock,
|
||||
return_value=mock_response,
|
||||
):
|
||||
await adapter.send_exec_approval(
|
||||
chat_id="oc_12345",
|
||||
command="echo test",
|
||||
session_key="my-session-key",
|
||||
)
|
||||
|
||||
assert len(adapter._approval_state) == 1
|
||||
approval_id = list(adapter._approval_state.keys())[0]
|
||||
state = adapter._approval_state[approval_id]
|
||||
assert state["session_key"] == "my-session-key"
|
||||
assert state["message_id"] == "msg_002"
|
||||
assert state["chat_id"] == "oc_12345"
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_not_connected(self):
|
||||
adapter = _make_adapter()
|
||||
adapter._client = None
|
||||
result = await adapter.send_exec_approval(
|
||||
chat_id="oc_12345", command="ls", session_key="s"
|
||||
)
|
||||
assert result.success is False
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_truncates_long_command(self):
|
||||
adapter = _make_adapter()
|
||||
|
||||
mock_response = SimpleNamespace(
|
||||
success=lambda: True,
|
||||
data=SimpleNamespace(message_id="msg_003"),
|
||||
)
|
||||
with patch.object(
|
||||
adapter, "_feishu_send_with_retry", new_callable=AsyncMock,
|
||||
return_value=mock_response,
|
||||
) as mock_send:
|
||||
long_cmd = "x" * 5000
|
||||
await adapter.send_exec_approval(
|
||||
chat_id="oc_12345", command=long_cmd, session_key="s"
|
||||
)
|
||||
|
||||
card = json.loads(mock_send.call_args[1]["payload"])
|
||||
content = card["elements"][0]["content"]
|
||||
assert "..." in content
|
||||
assert len(content) < 5000
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_multiple_approvals_get_unique_ids(self):
|
||||
adapter = _make_adapter()
|
||||
|
||||
mock_response = SimpleNamespace(
|
||||
success=lambda: True,
|
||||
data=SimpleNamespace(message_id="msg_x"),
|
||||
)
|
||||
with patch.object(
|
||||
adapter, "_feishu_send_with_retry", new_callable=AsyncMock,
|
||||
return_value=mock_response,
|
||||
):
|
||||
await adapter.send_exec_approval(
|
||||
chat_id="oc_1", command="cmd1", session_key="s1"
|
||||
)
|
||||
await adapter.send_exec_approval(
|
||||
chat_id="oc_2", command="cmd2", session_key="s2"
|
||||
)
|
||||
|
||||
assert len(adapter._approval_state) == 2
|
||||
ids = list(adapter._approval_state.keys())
|
||||
assert ids[0] != ids[1]
|
||||
|
||||
|
||||
# ===========================================================================
|
||||
# _handle_card_action_event — approval button clicks
|
||||
# ===========================================================================
|
||||
|
||||
class TestFeishuApprovalCallback:
|
||||
"""Test the approval intercept in _handle_card_action_event."""
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_resolves_approval_on_click(self):
|
||||
adapter = _make_adapter()
|
||||
adapter._approval_state[1] = {
|
||||
"session_key": "agent:main:feishu:group:oc_12345",
|
||||
"message_id": "msg_001",
|
||||
"chat_id": "oc_12345",
|
||||
}
|
||||
|
||||
data = _make_card_action_data(
|
||||
action_value={"hermes_action": "approve_once", "approval_id": 1},
|
||||
)
|
||||
|
||||
with (
|
||||
patch.object(
|
||||
adapter, "_resolve_sender_profile", new_callable=AsyncMock,
|
||||
return_value={"user_id": "ou_user1", "user_name": "Norbert", "user_id_alt": None},
|
||||
),
|
||||
patch.object(adapter, "_update_approval_card", new_callable=AsyncMock) as mock_update,
|
||||
patch("tools.approval.resolve_gateway_approval", return_value=1) as mock_resolve,
|
||||
):
|
||||
await adapter._handle_card_action_event(data)
|
||||
|
||||
mock_resolve.assert_called_once_with("agent:main:feishu:group:oc_12345", "once")
|
||||
mock_update.assert_called_once_with("msg_001", "Approved once", "Norbert", "once")
|
||||
|
||||
# State should be cleaned up
|
||||
assert 1 not in adapter._approval_state
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_deny_button(self):
|
||||
adapter = _make_adapter()
|
||||
adapter._approval_state[2] = {
|
||||
"session_key": "some-session",
|
||||
"message_id": "msg_002",
|
||||
"chat_id": "oc_12345",
|
||||
}
|
||||
|
||||
data = _make_card_action_data(
|
||||
action_value={"hermes_action": "deny", "approval_id": 2},
|
||||
token="tok_deny",
|
||||
)
|
||||
|
||||
with (
|
||||
patch.object(
|
||||
adapter, "_resolve_sender_profile", new_callable=AsyncMock,
|
||||
return_value={"user_id": "ou_alice", "user_name": "Alice", "user_id_alt": None},
|
||||
),
|
||||
patch.object(adapter, "_update_approval_card", new_callable=AsyncMock) as mock_update,
|
||||
patch("tools.approval.resolve_gateway_approval", return_value=1) as mock_resolve,
|
||||
):
|
||||
await adapter._handle_card_action_event(data)
|
||||
|
||||
mock_resolve.assert_called_once_with("some-session", "deny")
|
||||
mock_update.assert_called_once_with("msg_002", "Denied", "Alice", "deny")
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_session_approval(self):
|
||||
adapter = _make_adapter()
|
||||
adapter._approval_state[3] = {
|
||||
"session_key": "sess-3",
|
||||
"message_id": "msg_003",
|
||||
"chat_id": "oc_99",
|
||||
}
|
||||
|
||||
data = _make_card_action_data(
|
||||
action_value={"hermes_action": "approve_session", "approval_id": 3},
|
||||
token="tok_ses",
|
||||
)
|
||||
|
||||
with (
|
||||
patch.object(
|
||||
adapter, "_resolve_sender_profile", new_callable=AsyncMock,
|
||||
return_value={"user_id": "ou_u", "user_name": "Bob", "user_id_alt": None},
|
||||
),
|
||||
patch.object(adapter, "_update_approval_card", new_callable=AsyncMock) as mock_update,
|
||||
patch("tools.approval.resolve_gateway_approval", return_value=1) as mock_resolve,
|
||||
):
|
||||
await adapter._handle_card_action_event(data)
|
||||
|
||||
mock_resolve.assert_called_once_with("sess-3", "session")
|
||||
mock_update.assert_called_once_with("msg_003", "Approved for session", "Bob", "session")
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_always_approval(self):
|
||||
adapter = _make_adapter()
|
||||
adapter._approval_state[4] = {
|
||||
"session_key": "sess-4",
|
||||
"message_id": "msg_004",
|
||||
"chat_id": "oc_55",
|
||||
}
|
||||
|
||||
data = _make_card_action_data(
|
||||
action_value={"hermes_action": "approve_always", "approval_id": 4},
|
||||
token="tok_alw",
|
||||
)
|
||||
|
||||
with (
|
||||
patch.object(
|
||||
adapter, "_resolve_sender_profile", new_callable=AsyncMock,
|
||||
return_value={"user_id": "ou_u", "user_name": "Carol", "user_id_alt": None},
|
||||
),
|
||||
patch.object(adapter, "_update_approval_card", new_callable=AsyncMock),
|
||||
patch("tools.approval.resolve_gateway_approval", return_value=1) as mock_resolve,
|
||||
):
|
||||
await adapter._handle_card_action_event(data)
|
||||
|
||||
mock_resolve.assert_called_once_with("sess-4", "always")
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_already_resolved_drops_silently(self):
|
||||
adapter = _make_adapter()
|
||||
# No state for approval_id 99 — already resolved
|
||||
|
||||
data = _make_card_action_data(
|
||||
action_value={"hermes_action": "approve_once", "approval_id": 99},
|
||||
token="tok_gone",
|
||||
)
|
||||
|
||||
with patch("tools.approval.resolve_gateway_approval") as mock_resolve:
|
||||
await adapter._handle_card_action_event(data)
|
||||
|
||||
# Should NOT resolve — already handled
|
||||
mock_resolve.assert_not_called()
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_non_approval_actions_route_normally(self):
|
||||
"""Non-approval card actions should still become synthetic commands."""
|
||||
adapter = _make_adapter()
|
||||
|
||||
data = _make_card_action_data(
|
||||
action_value={"custom_action": "something_else"},
|
||||
token="tok_normal",
|
||||
)
|
||||
|
||||
with (
|
||||
patch.object(
|
||||
adapter, "_resolve_sender_profile", new_callable=AsyncMock,
|
||||
return_value={"user_id": "ou_u", "user_name": "Dave", "user_id_alt": None},
|
||||
),
|
||||
patch.object(adapter, "get_chat_info", new_callable=AsyncMock, return_value={"name": "Test Chat"}),
|
||||
patch.object(adapter, "_handle_message_with_guards", new_callable=AsyncMock) as mock_handle,
|
||||
patch("tools.approval.resolve_gateway_approval") as mock_resolve,
|
||||
):
|
||||
await adapter._handle_card_action_event(data)
|
||||
|
||||
# Should NOT resolve any approval
|
||||
mock_resolve.assert_not_called()
|
||||
# Should have routed as synthetic command
|
||||
mock_handle.assert_called_once()
|
||||
event = mock_handle.call_args[0][0]
|
||||
assert "/card button" in event.text
|
||||
|
||||
|
||||
# ===========================================================================
|
||||
# _update_approval_card — card replacement after resolution
|
||||
# ===========================================================================
|
||||
|
||||
class TestFeishuUpdateApprovalCard:
|
||||
"""Test the card update after approval resolution."""
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_updates_card_on_approve(self):
|
||||
adapter = _make_adapter()
|
||||
|
||||
mock_update = AsyncMock()
|
||||
adapter._client.im.v1.message.update = MagicMock()
|
||||
|
||||
with patch("asyncio.to_thread", new_callable=AsyncMock) as mock_thread:
|
||||
await adapter._update_approval_card(
|
||||
"msg_001", "Approved once", "Norbert", "once"
|
||||
)
|
||||
|
||||
mock_thread.assert_called_once()
|
||||
# Verify the update request was built
|
||||
call_args = mock_thread.call_args
|
||||
assert call_args[0][0] == adapter._client.im.v1.message.update
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_updates_card_on_deny(self):
|
||||
adapter = _make_adapter()
|
||||
|
||||
with patch("asyncio.to_thread", new_callable=AsyncMock) as mock_thread:
|
||||
await adapter._update_approval_card(
|
||||
"msg_002", "Denied", "Alice", "deny"
|
||||
)
|
||||
|
||||
mock_thread.assert_called_once()
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_skips_update_when_not_connected(self):
|
||||
adapter = _make_adapter()
|
||||
adapter._client = None
|
||||
|
||||
with patch("asyncio.to_thread", new_callable=AsyncMock) as mock_thread:
|
||||
await adapter._update_approval_card(
|
||||
"msg_001", "Approved", "Bob", "once"
|
||||
)
|
||||
|
||||
mock_thread.assert_not_called()
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_skips_update_when_no_message_id(self):
|
||||
adapter = _make_adapter()
|
||||
|
||||
with patch("asyncio.to_thread", new_callable=AsyncMock) as mock_thread:
|
||||
await adapter._update_approval_card(
|
||||
"", "Approved", "Bob", "once"
|
||||
)
|
||||
|
||||
mock_thread.assert_not_called()
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_swallows_update_errors(self):
|
||||
adapter = _make_adapter()
|
||||
|
||||
with patch("asyncio.to_thread", new_callable=AsyncMock, side_effect=Exception("API error")):
|
||||
# Should not raise
|
||||
await adapter._update_approval_card(
|
||||
"msg_001", "Approved", "Bob", "once"
|
||||
)
|
||||
@@ -87,7 +87,6 @@ class TestReasoningCommand:
|
||||
)
|
||||
|
||||
monkeypatch.setattr(gateway_run, "_hermes_home", hermes_home)
|
||||
monkeypatch.delenv("HERMES_REASONING_EFFORT", raising=False)
|
||||
|
||||
runner = _make_runner()
|
||||
runner._reasoning_config = {"enabled": True, "effort": "xhigh"}
|
||||
@@ -108,7 +107,6 @@ class TestReasoningCommand:
|
||||
config_path.write_text("agent:\n reasoning_effort: medium\n", encoding="utf-8")
|
||||
|
||||
monkeypatch.setattr(gateway_run, "_hermes_home", hermes_home)
|
||||
monkeypatch.delenv("HERMES_REASONING_EFFORT", raising=False)
|
||||
|
||||
runner = _make_runner()
|
||||
runner._reasoning_config = {"enabled": True, "effort": "medium"}
|
||||
@@ -138,7 +136,6 @@ class TestReasoningCommand:
|
||||
"api_key": "test-key",
|
||||
},
|
||||
)
|
||||
monkeypatch.delenv("HERMES_REASONING_EFFORT", raising=False)
|
||||
fake_run_agent = types.ModuleType("run_agent")
|
||||
fake_run_agent.AIAgent = _CapturingAgent
|
||||
monkeypatch.setitem(sys.modules, "run_agent", fake_run_agent)
|
||||
@@ -170,55 +167,6 @@ class TestReasoningCommand:
|
||||
assert _CapturingAgent.last_init is not None
|
||||
assert _CapturingAgent.last_init["reasoning_config"] == {"enabled": True, "effort": "low"}
|
||||
|
||||
def test_run_agent_prefers_config_over_stale_reasoning_env(self, tmp_path, monkeypatch):
|
||||
hermes_home = tmp_path / "hermes"
|
||||
hermes_home.mkdir()
|
||||
(hermes_home / "config.yaml").write_text("agent:\n reasoning_effort: none\n", encoding="utf-8")
|
||||
|
||||
monkeypatch.setattr(gateway_run, "_hermes_home", hermes_home)
|
||||
monkeypatch.setattr(gateway_run, "_env_path", hermes_home / ".env")
|
||||
monkeypatch.setattr(gateway_run, "load_dotenv", lambda *args, **kwargs: None)
|
||||
monkeypatch.setattr(
|
||||
gateway_run,
|
||||
"_resolve_runtime_agent_kwargs",
|
||||
lambda: {
|
||||
"provider": "openrouter",
|
||||
"api_mode": "chat_completions",
|
||||
"base_url": "https://openrouter.ai/api/v1",
|
||||
"api_key": "test-key",
|
||||
},
|
||||
)
|
||||
monkeypatch.setenv("HERMES_REASONING_EFFORT", "low")
|
||||
fake_run_agent = types.ModuleType("run_agent")
|
||||
fake_run_agent.AIAgent = _CapturingAgent
|
||||
monkeypatch.setitem(sys.modules, "run_agent", fake_run_agent)
|
||||
|
||||
_CapturingAgent.last_init = None
|
||||
runner = _make_runner()
|
||||
|
||||
source = SessionSource(
|
||||
platform=Platform.LOCAL,
|
||||
chat_id="cli",
|
||||
chat_name="CLI",
|
||||
chat_type="dm",
|
||||
user_id="user-1",
|
||||
)
|
||||
|
||||
result = asyncio.run(
|
||||
runner._run_agent(
|
||||
message="ping",
|
||||
context_prompt="",
|
||||
history=[],
|
||||
source=source,
|
||||
session_id="session-1",
|
||||
session_key="agent:main:local:dm",
|
||||
)
|
||||
)
|
||||
|
||||
assert result["final_response"] == "ok"
|
||||
assert _CapturingAgent.last_init is not None
|
||||
assert _CapturingAgent.last_init["reasoning_config"] == {"enabled": False}
|
||||
|
||||
def test_run_agent_includes_enabled_mcp_servers_in_gateway_toolsets(self, tmp_path, monkeypatch):
|
||||
hermes_home = tmp_path / "hermes"
|
||||
hermes_home.mkdir()
|
||||
|
||||
@@ -0,0 +1,158 @@
|
||||
"""Tests that on_session_finalize and on_session_reset plugin hooks fire in the gateway."""
|
||||
from datetime import datetime
|
||||
from types import SimpleNamespace
|
||||
from unittest.mock import AsyncMock, MagicMock, patch
|
||||
|
||||
import pytest
|
||||
|
||||
from gateway.config import GatewayConfig, Platform, PlatformConfig
|
||||
from gateway.platforms.base import MessageEvent
|
||||
from gateway.session import SessionEntry, SessionSource, build_session_key
|
||||
|
||||
|
||||
def _make_source() -> SessionSource:
|
||||
return SessionSource(
|
||||
platform=Platform.TELEGRAM,
|
||||
user_id="u1",
|
||||
chat_id="c1",
|
||||
user_name="tester",
|
||||
chat_type="dm",
|
||||
)
|
||||
|
||||
|
||||
def _make_event(text: str) -> MessageEvent:
|
||||
return MessageEvent(text=text, source=_make_source(), message_id="m1")
|
||||
|
||||
|
||||
def _make_runner():
|
||||
from gateway.run import GatewayRunner
|
||||
|
||||
runner = object.__new__(GatewayRunner)
|
||||
runner.config = GatewayConfig(
|
||||
platforms={Platform.TELEGRAM: PlatformConfig(enabled=True, token="***")}
|
||||
)
|
||||
adapter = MagicMock()
|
||||
adapter.send = AsyncMock()
|
||||
runner.adapters = {Platform.TELEGRAM: adapter}
|
||||
runner._voice_mode = {}
|
||||
runner.hooks = SimpleNamespace(emit=AsyncMock(), loaded_hooks=False)
|
||||
runner._session_model_overrides = {}
|
||||
runner._pending_model_notes = {}
|
||||
runner._background_tasks = set()
|
||||
|
||||
session_key = build_session_key(_make_source())
|
||||
session_entry = SessionEntry(
|
||||
session_key=session_key,
|
||||
session_id="sess-old",
|
||||
created_at=datetime.now(),
|
||||
updated_at=datetime.now(),
|
||||
platform=Platform.TELEGRAM,
|
||||
chat_type="dm",
|
||||
)
|
||||
new_session_entry = SessionEntry(
|
||||
session_key=session_key,
|
||||
session_id="sess-new",
|
||||
created_at=datetime.now(),
|
||||
updated_at=datetime.now(),
|
||||
platform=Platform.TELEGRAM,
|
||||
chat_type="dm",
|
||||
)
|
||||
runner.session_store = MagicMock()
|
||||
runner.session_store.get_or_create_session.return_value = new_session_entry
|
||||
runner.session_store.reset_session.return_value = new_session_entry
|
||||
runner.session_store._entries = {session_key: session_entry}
|
||||
runner.session_store._generate_session_key.return_value = session_key
|
||||
runner._running_agents = {}
|
||||
runner._pending_messages = {}
|
||||
runner._pending_approvals = {}
|
||||
runner._session_db = None
|
||||
runner._agent_cache_lock = None
|
||||
runner._is_user_authorized = lambda _source: True
|
||||
runner._format_session_info = lambda: ""
|
||||
|
||||
return runner
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
@patch("hermes_cli.plugins.invoke_hook")
|
||||
async def test_reset_fires_finalize_hook(mock_invoke_hook):
|
||||
"""/new must fire on_session_finalize with the OLD session id."""
|
||||
runner = _make_runner()
|
||||
|
||||
await runner._handle_reset_command(_make_event("/new"))
|
||||
|
||||
mock_invoke_hook.assert_any_call(
|
||||
"on_session_finalize", session_id="sess-old", platform="telegram"
|
||||
)
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
@patch("hermes_cli.plugins.invoke_hook")
|
||||
async def test_reset_fires_reset_hook(mock_invoke_hook):
|
||||
"""/new must fire on_session_reset with the NEW session id."""
|
||||
runner = _make_runner()
|
||||
|
||||
await runner._handle_reset_command(_make_event("/new"))
|
||||
|
||||
mock_invoke_hook.assert_any_call(
|
||||
"on_session_reset", session_id="sess-new", platform="telegram"
|
||||
)
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
@patch("hermes_cli.plugins.invoke_hook")
|
||||
async def test_finalize_before_reset(mock_invoke_hook):
|
||||
"""on_session_finalize must fire before on_session_reset."""
|
||||
runner = _make_runner()
|
||||
|
||||
await runner._handle_reset_command(_make_event("/new"))
|
||||
|
||||
calls = [c for c in mock_invoke_hook.call_args_list
|
||||
if c[0][0] in ("on_session_finalize", "on_session_reset")]
|
||||
hook_names = [c[0][0] for c in calls]
|
||||
assert hook_names == ["on_session_finalize", "on_session_reset"]
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
@patch("hermes_cli.plugins.invoke_hook")
|
||||
async def test_shutdown_fires_finalize_for_active_agents(mock_invoke_hook):
|
||||
"""Gateway stop() must fire on_session_finalize for each active agent."""
|
||||
from gateway.run import GatewayRunner
|
||||
|
||||
runner = object.__new__(GatewayRunner)
|
||||
runner._running = True
|
||||
runner._background_tasks = set()
|
||||
runner._pending_messages = {}
|
||||
runner._pending_approvals = {}
|
||||
runner._shutdown_event = MagicMock()
|
||||
runner.adapters = {}
|
||||
runner._exit_reason = "test"
|
||||
|
||||
agent1 = MagicMock()
|
||||
agent1.session_id = "sess-a"
|
||||
agent2 = MagicMock()
|
||||
agent2.session_id = "sess-b"
|
||||
runner._running_agents = {"key-a": agent1, "key-b": agent2}
|
||||
|
||||
with patch("gateway.status.remove_pid_file"), \
|
||||
patch("gateway.status.write_runtime_status"):
|
||||
await runner.stop()
|
||||
|
||||
finalize_calls = [
|
||||
c for c in mock_invoke_hook.call_args_list
|
||||
if c[0][0] == "on_session_finalize"
|
||||
]
|
||||
session_ids = {c[1]["session_id"] for c in finalize_calls}
|
||||
assert session_ids == {"sess-a", "sess-b"}
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
@patch("hermes_cli.plugins.invoke_hook", side_effect=Exception("boom"))
|
||||
async def test_hook_error_does_not_break_reset(mock_invoke_hook):
|
||||
"""Plugin hook errors must not prevent /new from completing."""
|
||||
runner = _make_runner()
|
||||
|
||||
result = await runner._handle_reset_command(_make_event("/new"))
|
||||
|
||||
# Should still return a success message despite hook errors
|
||||
assert "Session reset" in result or "New session" in result
|
||||
@@ -324,3 +324,91 @@ class TestSegmentBreakOnToolBoundary:
|
||||
await consumer.run()
|
||||
|
||||
assert consumer.already_sent
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_edit_failure_sends_only_unsent_tail_at_finish(self):
|
||||
"""If an edit fails mid-stream, send only the missing tail once at finish."""
|
||||
adapter = MagicMock()
|
||||
send_results = [
|
||||
SimpleNamespace(success=True, message_id="msg_1"),
|
||||
SimpleNamespace(success=True, message_id="msg_2"),
|
||||
]
|
||||
adapter.send = AsyncMock(side_effect=send_results)
|
||||
adapter.edit_message = AsyncMock(return_value=SimpleNamespace(success=False, error="flood_control:6"))
|
||||
adapter.MAX_MESSAGE_LENGTH = 4096
|
||||
|
||||
config = StreamConsumerConfig(edit_interval=0.01, buffer_threshold=5, cursor=" ▉")
|
||||
consumer = GatewayStreamConsumer(adapter, "chat_123", config)
|
||||
|
||||
consumer.on_delta("Hello")
|
||||
task = asyncio.create_task(consumer.run())
|
||||
await asyncio.sleep(0.08)
|
||||
consumer.on_delta(" world")
|
||||
await asyncio.sleep(0.08)
|
||||
consumer.finish()
|
||||
await task
|
||||
|
||||
assert adapter.send.call_count == 2
|
||||
first_text = adapter.send.call_args_list[0][1]["content"]
|
||||
second_text = adapter.send.call_args_list[1][1]["content"]
|
||||
assert "Hello" in first_text
|
||||
assert second_text.strip() == "world"
|
||||
assert consumer.already_sent
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_segment_break_clears_failed_edit_fallback_state(self):
|
||||
"""A tool boundary after edit failure must not duplicate the next segment."""
|
||||
adapter = MagicMock()
|
||||
send_results = [
|
||||
SimpleNamespace(success=True, message_id="msg_1"),
|
||||
SimpleNamespace(success=True, message_id="msg_2"),
|
||||
]
|
||||
adapter.send = AsyncMock(side_effect=send_results)
|
||||
adapter.edit_message = AsyncMock(return_value=SimpleNamespace(success=False, error="flood_control:6"))
|
||||
adapter.MAX_MESSAGE_LENGTH = 4096
|
||||
|
||||
config = StreamConsumerConfig(edit_interval=0.01, buffer_threshold=5, cursor=" ▉")
|
||||
consumer = GatewayStreamConsumer(adapter, "chat_123", config)
|
||||
|
||||
consumer.on_delta("Hello")
|
||||
task = asyncio.create_task(consumer.run())
|
||||
await asyncio.sleep(0.08)
|
||||
consumer.on_delta(" world")
|
||||
await asyncio.sleep(0.08)
|
||||
consumer.on_delta(None)
|
||||
consumer.on_delta("Next segment")
|
||||
consumer.finish()
|
||||
await task
|
||||
|
||||
sent_texts = [call[1]["content"] for call in adapter.send.call_args_list]
|
||||
assert sent_texts == ["Hello ▉", "Next segment"]
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_fallback_final_splits_long_continuation_without_dropping_text(self):
|
||||
"""Long continuation tails should be chunked when fallback final-send runs."""
|
||||
adapter = MagicMock()
|
||||
adapter.send = AsyncMock(side_effect=[
|
||||
SimpleNamespace(success=True, message_id="msg_1"),
|
||||
SimpleNamespace(success=True, message_id="msg_2"),
|
||||
SimpleNamespace(success=True, message_id="msg_3"),
|
||||
])
|
||||
adapter.edit_message = AsyncMock(return_value=SimpleNamespace(success=False, error="flood_control:6"))
|
||||
adapter.MAX_MESSAGE_LENGTH = 610
|
||||
|
||||
config = StreamConsumerConfig(edit_interval=0.01, buffer_threshold=5, cursor=" ▉")
|
||||
consumer = GatewayStreamConsumer(adapter, "chat_123", config)
|
||||
|
||||
prefix = "abc"
|
||||
tail = "x" * 620
|
||||
consumer.on_delta(prefix)
|
||||
task = asyncio.create_task(consumer.run())
|
||||
await asyncio.sleep(0.08)
|
||||
consumer.on_delta(tail)
|
||||
await asyncio.sleep(0.08)
|
||||
consumer.finish()
|
||||
await task
|
||||
|
||||
sent_texts = [call[1]["content"] for call in adapter.send.call_args_list]
|
||||
assert len(sent_texts) == 3
|
||||
assert sent_texts[0].startswith(prefix)
|
||||
assert sum(len(t) for t in sent_texts[1:]) == len(tail)
|
||||
|
||||
@@ -808,6 +808,55 @@ def test_minimax_explicit_api_mode_respected(monkeypatch):
|
||||
assert resolved["api_mode"] == "chat_completions"
|
||||
|
||||
|
||||
def test_minimax_config_base_url_overrides_hardcoded_default(monkeypatch):
|
||||
"""model.base_url in config.yaml should override the hardcoded default (#6039)."""
|
||||
monkeypatch.setattr(rp, "resolve_provider", lambda *a, **k: "minimax")
|
||||
monkeypatch.setattr(rp, "_get_model_config", lambda: {
|
||||
"provider": "minimax",
|
||||
"base_url": "https://api.minimaxi.com/anthropic",
|
||||
})
|
||||
monkeypatch.setenv("MINIMAX_API_KEY", "test-minimax-key")
|
||||
monkeypatch.delenv("MINIMAX_BASE_URL", raising=False)
|
||||
|
||||
resolved = rp.resolve_runtime_provider(requested="minimax")
|
||||
|
||||
assert resolved["provider"] == "minimax"
|
||||
assert resolved["base_url"] == "https://api.minimaxi.com/anthropic"
|
||||
assert resolved["api_mode"] == "anthropic_messages"
|
||||
|
||||
|
||||
def test_minimax_env_base_url_still_wins_over_config(monkeypatch):
|
||||
"""MINIMAX_BASE_URL env var should take priority over config.yaml model.base_url."""
|
||||
monkeypatch.setattr(rp, "resolve_provider", lambda *a, **k: "minimax")
|
||||
monkeypatch.setattr(rp, "_get_model_config", lambda: {
|
||||
"provider": "minimax",
|
||||
"base_url": "https://api.minimaxi.com/anthropic",
|
||||
})
|
||||
monkeypatch.setenv("MINIMAX_API_KEY", "test-minimax-key")
|
||||
monkeypatch.setenv("MINIMAX_BASE_URL", "https://custom.example.com/v1")
|
||||
|
||||
resolved = rp.resolve_runtime_provider(requested="minimax")
|
||||
|
||||
# Env var wins because resolve_api_key_provider_credentials prefers it
|
||||
assert resolved["base_url"] == "https://custom.example.com/v1"
|
||||
|
||||
|
||||
def test_minimax_config_base_url_ignored_for_different_provider(monkeypatch):
|
||||
"""model.base_url should NOT be used when model.provider doesn't match."""
|
||||
monkeypatch.setattr(rp, "resolve_provider", lambda *a, **k: "minimax")
|
||||
monkeypatch.setattr(rp, "_get_model_config", lambda: {
|
||||
"provider": "openrouter",
|
||||
"base_url": "https://some-other-endpoint.com/v1",
|
||||
})
|
||||
monkeypatch.setenv("MINIMAX_API_KEY", "test-minimax-key")
|
||||
monkeypatch.delenv("MINIMAX_BASE_URL", raising=False)
|
||||
|
||||
resolved = rp.resolve_runtime_provider(requested="minimax")
|
||||
|
||||
# Should use the default, NOT the config base_url from a different provider
|
||||
assert resolved["base_url"] == "https://api.minimax.io/anthropic"
|
||||
|
||||
|
||||
def test_alibaba_default_coding_intl_endpoint_uses_chat_completions(monkeypatch):
|
||||
"""Alibaba default coding-intl /v1 URL should use chat_completions mode."""
|
||||
monkeypatch.setattr(rp, "resolve_provider", lambda *a, **k: "alibaba")
|
||||
|
||||
@@ -34,8 +34,8 @@ class TestSetupProviderModelSelection:
|
||||
@pytest.mark.parametrize("provider_id,expected_defaults", [
|
||||
("zai", ["glm-5", "glm-4.7", "glm-4.5", "glm-4.5-flash"]),
|
||||
("kimi-coding", ["kimi-k2.5", "kimi-k2-thinking", "kimi-k2-turbo-preview"]),
|
||||
("minimax", ["MiniMax-M2.7", "MiniMax-M2.7-highspeed", "MiniMax-M2.5", "MiniMax-M2.5-highspeed", "MiniMax-M2.1"]),
|
||||
("minimax-cn", ["MiniMax-M2.7", "MiniMax-M2.7-highspeed", "MiniMax-M2.5", "MiniMax-M2.5-highspeed", "MiniMax-M2.1"]),
|
||||
("minimax", ["MiniMax-M1", "MiniMax-M1-40k", "MiniMax-M1-80k", "MiniMax-M1-128k", "MiniMax-M1-256k", "MiniMax-M2.5", "MiniMax-M2.7"]),
|
||||
("minimax-cn", ["MiniMax-M1", "MiniMax-M1-40k", "MiniMax-M1-80k", "MiniMax-M1-128k", "MiniMax-M1-256k", "MiniMax-M2.5", "MiniMax-M2.7"]),
|
||||
("opencode-zen", ["gpt-5.4", "gpt-5.3-codex", "claude-sonnet-4-6", "gemini-3-flash"]),
|
||||
("opencode-go", ["glm-5", "kimi-k2.5", "minimax-m2.5", "minimax-m2.7"]),
|
||||
])
|
||||
|
||||
@@ -1,162 +0,0 @@
|
||||
"""Tests for _save_oversized_tool_result() — the large tool response handler.
|
||||
|
||||
When a tool returns more than _LARGE_RESULT_CHARS characters, the full content
|
||||
is saved to a file and the model receives a preview + file path instead.
|
||||
"""
|
||||
|
||||
import os
|
||||
import re
|
||||
|
||||
import pytest
|
||||
|
||||
from run_agent import (
|
||||
_save_oversized_tool_result,
|
||||
_LARGE_RESULT_CHARS,
|
||||
_LARGE_RESULT_PREVIEW_CHARS,
|
||||
)
|
||||
|
||||
|
||||
class TestSaveOversizedToolResult:
|
||||
"""Unit tests for the large tool result handler."""
|
||||
|
||||
def test_small_result_returned_unchanged(self):
|
||||
"""Results under the threshold pass through untouched."""
|
||||
small = "x" * 1000
|
||||
assert _save_oversized_tool_result("terminal", small) is small
|
||||
|
||||
def test_exactly_at_threshold_returned_unchanged(self):
|
||||
"""Results exactly at the threshold pass through."""
|
||||
exact = "y" * _LARGE_RESULT_CHARS
|
||||
assert _save_oversized_tool_result("terminal", exact) is exact
|
||||
|
||||
def test_oversized_result_saved_to_file(self, tmp_path, monkeypatch):
|
||||
"""Results over the threshold are written to a file."""
|
||||
monkeypatch.setenv("HERMES_HOME", str(tmp_path / ".hermes"))
|
||||
os.makedirs(tmp_path / ".hermes", exist_ok=True)
|
||||
|
||||
big = "A" * (_LARGE_RESULT_CHARS + 500)
|
||||
result = _save_oversized_tool_result("terminal", big)
|
||||
|
||||
# Should contain the preview
|
||||
assert result.startswith("A" * _LARGE_RESULT_PREVIEW_CHARS)
|
||||
# Should mention the file path
|
||||
assert "Full output saved to:" in result
|
||||
# Should mention original size
|
||||
assert f"{len(big):,}" in result
|
||||
|
||||
# Extract the file path and verify the file exists with full content
|
||||
match = re.search(r"Full output saved to: (.+?)\n", result)
|
||||
assert match, f"No file path found in result: {result[:300]}"
|
||||
filepath = match.group(1)
|
||||
assert os.path.isfile(filepath)
|
||||
with open(filepath, "r", encoding="utf-8") as f:
|
||||
saved = f.read()
|
||||
assert saved == big
|
||||
assert len(saved) == _LARGE_RESULT_CHARS + 500
|
||||
|
||||
def test_file_placed_in_cache_tool_responses(self, tmp_path, monkeypatch):
|
||||
"""Saved file lives under HERMES_HOME/cache/tool_responses/."""
|
||||
hermes_home = str(tmp_path / ".hermes")
|
||||
monkeypatch.setenv("HERMES_HOME", hermes_home)
|
||||
os.makedirs(hermes_home, exist_ok=True)
|
||||
|
||||
big = "B" * (_LARGE_RESULT_CHARS + 1)
|
||||
result = _save_oversized_tool_result("web_search", big)
|
||||
|
||||
match = re.search(r"Full output saved to: (.+?)\n", result)
|
||||
filepath = match.group(1)
|
||||
expected_dir = os.path.join(hermes_home, "cache", "tool_responses")
|
||||
assert filepath.startswith(expected_dir)
|
||||
|
||||
def test_filename_contains_tool_name(self, tmp_path, monkeypatch):
|
||||
"""The saved filename includes a sanitized version of the tool name."""
|
||||
monkeypatch.setenv("HERMES_HOME", str(tmp_path / ".hermes"))
|
||||
os.makedirs(tmp_path / ".hermes", exist_ok=True)
|
||||
|
||||
big = "C" * (_LARGE_RESULT_CHARS + 1)
|
||||
result = _save_oversized_tool_result("browser_navigate", big)
|
||||
|
||||
match = re.search(r"Full output saved to: (.+?)\n", result)
|
||||
filename = os.path.basename(match.group(1))
|
||||
assert filename.startswith("browser_navigate_")
|
||||
assert filename.endswith(".txt")
|
||||
|
||||
def test_tool_name_sanitized(self, tmp_path, monkeypatch):
|
||||
"""Special characters in tool names are replaced in the filename."""
|
||||
monkeypatch.setenv("HERMES_HOME", str(tmp_path / ".hermes"))
|
||||
os.makedirs(tmp_path / ".hermes", exist_ok=True)
|
||||
|
||||
big = "D" * (_LARGE_RESULT_CHARS + 1)
|
||||
result = _save_oversized_tool_result("mcp:some/weird tool", big)
|
||||
|
||||
match = re.search(r"Full output saved to: (.+?)\n", result)
|
||||
filename = os.path.basename(match.group(1))
|
||||
# No slashes or colons in filename
|
||||
assert "/" not in filename
|
||||
assert ":" not in filename
|
||||
|
||||
def test_fallback_on_write_failure(self, tmp_path, monkeypatch):
|
||||
"""When file write fails, falls back to destructive truncation."""
|
||||
# Point HERMES_HOME to a path that will fail (file, not directory)
|
||||
bad_path = str(tmp_path / "not_a_dir.txt")
|
||||
with open(bad_path, "w") as f:
|
||||
f.write("I'm a file, not a directory")
|
||||
monkeypatch.setenv("HERMES_HOME", bad_path)
|
||||
|
||||
big = "E" * (_LARGE_RESULT_CHARS + 50_000)
|
||||
result = _save_oversized_tool_result("terminal", big)
|
||||
|
||||
# Should still contain data (fallback truncation)
|
||||
assert len(result) > 0
|
||||
assert result.startswith("E" * 1000)
|
||||
# Should mention the failure
|
||||
assert "File save failed" in result
|
||||
# Should be truncated to approximately _LARGE_RESULT_CHARS + error msg
|
||||
assert len(result) < len(big)
|
||||
|
||||
def test_preview_length_capped(self, tmp_path, monkeypatch):
|
||||
"""The inline preview is capped at _LARGE_RESULT_PREVIEW_CHARS."""
|
||||
monkeypatch.setenv("HERMES_HOME", str(tmp_path / ".hermes"))
|
||||
os.makedirs(tmp_path / ".hermes", exist_ok=True)
|
||||
|
||||
# Use distinct chars so we can measure the preview
|
||||
big = "Z" * (_LARGE_RESULT_CHARS + 5000)
|
||||
result = _save_oversized_tool_result("terminal", big)
|
||||
|
||||
# The preview section is the content before the "[Large tool response:" marker
|
||||
marker_pos = result.index("[Large tool response:")
|
||||
preview_section = result[:marker_pos].rstrip()
|
||||
assert len(preview_section) == _LARGE_RESULT_PREVIEW_CHARS
|
||||
|
||||
def test_guidance_message_mentions_tools(self, tmp_path, monkeypatch):
|
||||
"""The replacement message tells the model how to access the file."""
|
||||
monkeypatch.setenv("HERMES_HOME", str(tmp_path / ".hermes"))
|
||||
os.makedirs(tmp_path / ".hermes", exist_ok=True)
|
||||
|
||||
big = "F" * (_LARGE_RESULT_CHARS + 1)
|
||||
result = _save_oversized_tool_result("terminal", big)
|
||||
|
||||
assert "read_file" in result
|
||||
assert "search_files" in result
|
||||
|
||||
def test_empty_result_passes_through(self):
|
||||
"""Empty strings are not oversized."""
|
||||
assert _save_oversized_tool_result("terminal", "") == ""
|
||||
|
||||
def test_unicode_content_preserved(self, tmp_path, monkeypatch):
|
||||
"""Unicode content is fully preserved in the saved file."""
|
||||
monkeypatch.setenv("HERMES_HOME", str(tmp_path / ".hermes"))
|
||||
os.makedirs(tmp_path / ".hermes", exist_ok=True)
|
||||
|
||||
# Mix of ASCII and multi-byte unicode to exceed threshold
|
||||
unit = "Hello 世界! 🎉 " * 100 # ~1400 chars per repeat
|
||||
big = unit * ((_LARGE_RESULT_CHARS // len(unit)) + 1)
|
||||
assert len(big) > _LARGE_RESULT_CHARS
|
||||
|
||||
result = _save_oversized_tool_result("terminal", big)
|
||||
match = re.search(r"Full output saved to: (.+?)\n", result)
|
||||
filepath = match.group(1)
|
||||
|
||||
with open(filepath, "r", encoding="utf-8") as f:
|
||||
saved = f.read()
|
||||
assert saved == big
|
||||
@@ -1011,10 +1011,9 @@ class TestExecuteToolCalls:
|
||||
big_result = "x" * 150_000
|
||||
with patch("run_agent.handle_function_call", return_value=big_result):
|
||||
agent._execute_tool_calls(mock_msg, messages, "task-1")
|
||||
# Content should be replaced with preview + file path
|
||||
# Content should be replaced with persisted-output or truncation
|
||||
assert len(messages[0]["content"]) < 150_000
|
||||
assert "Large tool response" in messages[0]["content"]
|
||||
assert "Full output saved to:" in messages[0]["content"]
|
||||
assert ("Truncated" in messages[0]["content"] or "<persisted-output>" in messages[0]["content"])
|
||||
|
||||
|
||||
class TestConcurrentToolExecution:
|
||||
@@ -1249,8 +1248,7 @@ class TestConcurrentToolExecution:
|
||||
assert len(messages) == 2
|
||||
for m in messages:
|
||||
assert len(m["content"]) < 150_000
|
||||
assert "Large tool response" in m["content"]
|
||||
assert "Full output saved to:" in m["content"]
|
||||
assert ("Truncated" in m["content"] or "<persisted-output>" in m["content"])
|
||||
|
||||
def test_invoke_tool_dispatches_to_handle_function_call(self, agent):
|
||||
"""_invoke_tool should route regular tools through handle_function_call."""
|
||||
|
||||
@@ -0,0 +1,135 @@
|
||||
"""Tests for Ollama num_ctx context length detection and injection.
|
||||
|
||||
Covers:
|
||||
agent/model_metadata.py — query_ollama_num_ctx()
|
||||
run_agent.py — _ollama_num_ctx detection + extra_body injection
|
||||
"""
|
||||
|
||||
from unittest.mock import patch, MagicMock
|
||||
|
||||
import pytest
|
||||
|
||||
from agent.model_metadata import query_ollama_num_ctx
|
||||
|
||||
|
||||
# ═══════════════════════════════════════════════════════════════════════
|
||||
# Level 1: query_ollama_num_ctx — Ollama API interaction
|
||||
# ═══════════════════════════════════════════════════════════════════════
|
||||
|
||||
|
||||
def _mock_httpx_client(show_response_data, status_code=200):
|
||||
"""Create a mock httpx.Client context manager that returns given /api/show data."""
|
||||
mock_resp = MagicMock(status_code=status_code)
|
||||
mock_resp.json.return_value = show_response_data
|
||||
mock_client = MagicMock()
|
||||
mock_client.post.return_value = mock_resp
|
||||
mock_ctx = MagicMock()
|
||||
mock_ctx.__enter__ = MagicMock(return_value=mock_client)
|
||||
mock_ctx.__exit__ = MagicMock(return_value=False)
|
||||
return mock_ctx, mock_client
|
||||
|
||||
|
||||
class TestQueryOllamaNumCtx:
|
||||
"""Test the Ollama /api/show context length query."""
|
||||
|
||||
def test_returns_context_from_model_info(self):
|
||||
"""Should extract context_length from GGUF model_info metadata."""
|
||||
show_data = {
|
||||
"model_info": {"llama.context_length": 131072},
|
||||
"parameters": "",
|
||||
}
|
||||
mock_ctx, _ = _mock_httpx_client(show_data)
|
||||
|
||||
with patch("agent.model_metadata.detect_local_server_type", return_value="ollama"):
|
||||
# httpx is imported inside the function — patch the module import
|
||||
import httpx
|
||||
with patch.object(httpx, "Client", return_value=mock_ctx):
|
||||
result = query_ollama_num_ctx("llama3.1:8b", "http://localhost:11434/v1")
|
||||
|
||||
assert result == 131072
|
||||
|
||||
def test_prefers_explicit_num_ctx_from_modelfile(self):
|
||||
"""If the Modelfile sets num_ctx explicitly, that should take priority."""
|
||||
show_data = {
|
||||
"model_info": {"llama.context_length": 131072},
|
||||
"parameters": "num_ctx 32768\ntemperature 0.7",
|
||||
}
|
||||
mock_ctx, _ = _mock_httpx_client(show_data)
|
||||
|
||||
with patch("agent.model_metadata.detect_local_server_type", return_value="ollama"):
|
||||
import httpx
|
||||
with patch.object(httpx, "Client", return_value=mock_ctx):
|
||||
result = query_ollama_num_ctx("custom-model", "http://localhost:11434")
|
||||
|
||||
assert result == 32768
|
||||
|
||||
def test_returns_none_for_non_ollama_server(self):
|
||||
"""Should return None if the server is not Ollama."""
|
||||
with patch("agent.model_metadata.detect_local_server_type", return_value="lm-studio"):
|
||||
result = query_ollama_num_ctx("model", "http://localhost:1234")
|
||||
assert result is None
|
||||
|
||||
def test_returns_none_on_connection_error(self):
|
||||
"""Should return None if the server is unreachable."""
|
||||
with patch("agent.model_metadata.detect_local_server_type", side_effect=Exception("timeout")):
|
||||
result = query_ollama_num_ctx("model", "http://localhost:11434")
|
||||
assert result is None
|
||||
|
||||
def test_returns_none_on_404(self):
|
||||
"""Should return None if the model is not found."""
|
||||
mock_ctx, _ = _mock_httpx_client({}, status_code=404)
|
||||
|
||||
with patch("agent.model_metadata.detect_local_server_type", return_value="ollama"):
|
||||
import httpx
|
||||
with patch.object(httpx, "Client", return_value=mock_ctx):
|
||||
result = query_ollama_num_ctx("nonexistent", "http://localhost:11434")
|
||||
|
||||
assert result is None
|
||||
|
||||
def test_strips_provider_prefix(self):
|
||||
"""Should strip 'local:' prefix from model name before querying."""
|
||||
show_data = {
|
||||
"model_info": {"qwen2.context_length": 32768},
|
||||
"parameters": "",
|
||||
}
|
||||
mock_ctx, mock_client = _mock_httpx_client(show_data)
|
||||
|
||||
with patch("agent.model_metadata.detect_local_server_type", return_value="ollama"):
|
||||
import httpx
|
||||
with patch.object(httpx, "Client", return_value=mock_ctx):
|
||||
result = query_ollama_num_ctx("local:qwen2.5:7b", "http://localhost:11434/v1")
|
||||
|
||||
# Verify the post was called with stripped name (no "local:" prefix)
|
||||
call_args = mock_client.post.call_args
|
||||
assert call_args[1]["json"]["name"] == "qwen2.5:7b" or call_args[0][1] is not None
|
||||
assert result == 32768
|
||||
|
||||
def test_handles_qwen2_architecture_key(self):
|
||||
"""Different model architectures use different key prefixes in model_info."""
|
||||
show_data = {
|
||||
"model_info": {"qwen2.context_length": 65536},
|
||||
"parameters": "",
|
||||
}
|
||||
mock_ctx, _ = _mock_httpx_client(show_data)
|
||||
|
||||
with patch("agent.model_metadata.detect_local_server_type", return_value="ollama"):
|
||||
import httpx
|
||||
with patch.object(httpx, "Client", return_value=mock_ctx):
|
||||
result = query_ollama_num_ctx("qwen2.5:32b", "http://localhost:11434")
|
||||
|
||||
assert result == 65536
|
||||
|
||||
def test_returns_none_when_model_info_empty(self):
|
||||
"""Should return None if model_info has no context_length key."""
|
||||
show_data = {
|
||||
"model_info": {"llama.embedding_length": 4096},
|
||||
"parameters": "",
|
||||
}
|
||||
mock_ctx, _ = _mock_httpx_client(show_data)
|
||||
|
||||
with patch("agent.model_metadata.detect_local_server_type", return_value="ollama"):
|
||||
import httpx
|
||||
with patch.object(httpx, "Client", return_value=mock_ctx):
|
||||
result = query_ollama_num_ctx("model", "http://localhost:11434")
|
||||
|
||||
assert result is None
|
||||
@@ -0,0 +1,117 @@
|
||||
"""Tests for agent.retry_utils jittered backoff."""
|
||||
|
||||
import threading
|
||||
|
||||
import agent.retry_utils as retry_utils
|
||||
from agent.retry_utils import jittered_backoff
|
||||
|
||||
|
||||
def test_backoff_is_exponential():
|
||||
"""Base delay should double each attempt (before jitter)."""
|
||||
for attempt in (1, 2, 3, 4):
|
||||
delays = [jittered_backoff(attempt, base_delay=5.0, max_delay=120.0, jitter_ratio=0.0) for _ in range(100)]
|
||||
expected = min(5.0 * (2 ** (attempt - 1)), 120.0)
|
||||
mean = sum(delays) / len(delays)
|
||||
assert abs(mean - expected) < 0.01, f"attempt {attempt}: expected {expected}, got {mean}"
|
||||
|
||||
|
||||
def test_backoff_respects_max_delay():
|
||||
"""Even with high attempt numbers, delay should not exceed max_delay."""
|
||||
for attempt in (10, 20, 100):
|
||||
delay = jittered_backoff(attempt, base_delay=5.0, max_delay=60.0, jitter_ratio=0.0)
|
||||
assert delay <= 60.0, f"attempt {attempt}: delay {delay} exceeds max 60s"
|
||||
|
||||
|
||||
def test_backoff_adds_jitter():
|
||||
"""With jitter enabled, delays should vary across calls."""
|
||||
delays = [jittered_backoff(1, base_delay=10.0, max_delay=120.0, jitter_ratio=0.5) for _ in range(50)]
|
||||
assert min(delays) != max(delays), "jitter should produce varying delays"
|
||||
assert all(d >= 10.0 for d in delays), "jittered delay should be >= base delay"
|
||||
assert all(d <= 15.0 for d in delays), "jittered delay should be bounded"
|
||||
|
||||
|
||||
def test_backoff_attempt_1_is_base():
|
||||
"""First attempt delay should equal base_delay (with no jitter)."""
|
||||
delay = jittered_backoff(1, base_delay=3.0, max_delay=120.0, jitter_ratio=0.0)
|
||||
assert delay == 3.0
|
||||
|
||||
|
||||
def test_backoff_with_zero_base_delay_returns_max():
|
||||
"""base_delay=0 should return max_delay (guard against busy-wait)."""
|
||||
delay = jittered_backoff(1, base_delay=0.0, max_delay=60.0, jitter_ratio=0.0)
|
||||
assert delay == 60.0
|
||||
|
||||
|
||||
def test_backoff_with_extreme_attempt_returns_max():
|
||||
"""Very large attempt numbers should not overflow and should return max_delay."""
|
||||
delay = jittered_backoff(999, base_delay=5.0, max_delay=120.0, jitter_ratio=0.0)
|
||||
assert delay == 120.0
|
||||
|
||||
|
||||
def test_backoff_negative_attempt_treated_as_one():
|
||||
"""Negative attempt should not crash and behaves like attempt=1."""
|
||||
delay = jittered_backoff(-5, base_delay=10.0, max_delay=120.0, jitter_ratio=0.0)
|
||||
assert delay == 10.0
|
||||
|
||||
|
||||
def test_backoff_thread_safety():
|
||||
"""Concurrent calls should generally produce different delays."""
|
||||
results = []
|
||||
barrier = threading.Barrier(8)
|
||||
|
||||
def _call_backoff():
|
||||
barrier.wait()
|
||||
results.append(jittered_backoff(1, base_delay=10.0, max_delay=120.0, jitter_ratio=0.5))
|
||||
|
||||
threads = [threading.Thread(target=_call_backoff) for _ in range(8)]
|
||||
for t in threads:
|
||||
t.start()
|
||||
for t in threads:
|
||||
t.join(timeout=5)
|
||||
|
||||
assert len(results) == 8
|
||||
unique = len(set(results))
|
||||
assert unique >= 6, f"Expected mostly unique delays, got {unique}/8 unique"
|
||||
|
||||
|
||||
def test_backoff_uses_locked_tick_for_seed(monkeypatch):
|
||||
"""Seed derivation should use per-call tick captured under lock."""
|
||||
import time
|
||||
|
||||
monkeypatch.setattr(retry_utils, "_jitter_counter", 0)
|
||||
|
||||
recorded_seeds = []
|
||||
|
||||
class _RecordingRandom:
|
||||
def __init__(self, seed):
|
||||
recorded_seeds.append(seed)
|
||||
|
||||
def uniform(self, a, b):
|
||||
return 0.0
|
||||
|
||||
monkeypatch.setattr(retry_utils.random, "Random", _RecordingRandom)
|
||||
|
||||
fixed_time_ns = 123456789
|
||||
|
||||
def _time_ns_wait_for_two_ticks():
|
||||
deadline = time.time() + 2.0
|
||||
while retry_utils._jitter_counter < 2 and time.time() < deadline:
|
||||
time.sleep(0.001)
|
||||
return fixed_time_ns
|
||||
|
||||
monkeypatch.setattr(retry_utils.time, "time_ns", _time_ns_wait_for_two_ticks)
|
||||
|
||||
barrier = threading.Barrier(2)
|
||||
|
||||
def _call():
|
||||
barrier.wait()
|
||||
jittered_backoff(1, base_delay=10.0, max_delay=120.0, jitter_ratio=0.5)
|
||||
|
||||
threads = [threading.Thread(target=_call) for _ in range(2)]
|
||||
for t in threads:
|
||||
t.start()
|
||||
for t in threads:
|
||||
t.join(timeout=5)
|
||||
|
||||
assert len(recorded_seeds) == 2
|
||||
assert len(set(recorded_seeds)) == 2, f"Expected unique seeds, got {recorded_seeds}"
|
||||
@@ -152,6 +152,109 @@ class TestFindAgentBrowser:
|
||||
class TestRunBrowserCommandPathConstruction:
|
||||
"""Verify _run_browser_command() includes Homebrew node dirs in subprocess PATH."""
|
||||
|
||||
def test_subprocess_preserves_executable_path_with_spaces(self, tmp_path):
|
||||
"""A local agent-browser path containing spaces must stay one argv entry."""
|
||||
captured_cmd = None
|
||||
|
||||
mock_proc = MagicMock()
|
||||
mock_proc.returncode = 0
|
||||
mock_proc.wait.return_value = 0
|
||||
|
||||
def capture_popen(cmd, **kwargs):
|
||||
nonlocal captured_cmd
|
||||
captured_cmd = cmd
|
||||
return mock_proc
|
||||
|
||||
fake_session = {
|
||||
"session_name": "test-session",
|
||||
"session_id": "test-id",
|
||||
"cdp_url": None,
|
||||
}
|
||||
fake_json = json.dumps({"success": True})
|
||||
browser_path = "/Users/test/Library/Application Support/hermes/node_modules/.bin/agent-browser"
|
||||
hermes_home = str(tmp_path / "hermes-home")
|
||||
|
||||
with patch("tools.browser_tool._find_agent_browser", return_value=browser_path), \
|
||||
patch("tools.browser_tool._get_session_info", return_value=fake_session), \
|
||||
patch("tools.browser_tool._socket_safe_tmpdir", return_value=str(tmp_path)), \
|
||||
patch("tools.browser_tool._discover_homebrew_node_dirs", return_value=[]), \
|
||||
patch("hermes_constants.Path.home", return_value=tmp_path), \
|
||||
patch("subprocess.Popen", side_effect=capture_popen), \
|
||||
patch("os.open", return_value=99), \
|
||||
patch("os.close"), \
|
||||
patch("tools.interrupt.is_interrupted", return_value=False), \
|
||||
patch.dict(
|
||||
os.environ,
|
||||
{
|
||||
"PATH": "/usr/bin:/bin",
|
||||
"HOME": "/home/test",
|
||||
"HERMES_HOME": hermes_home,
|
||||
},
|
||||
clear=True,
|
||||
):
|
||||
with patch("builtins.open", mock_open(read_data=fake_json)):
|
||||
_run_browser_command("test-task", "navigate", ["https://example.com"])
|
||||
|
||||
assert captured_cmd is not None
|
||||
assert captured_cmd[0] == browser_path
|
||||
assert captured_cmd[1:5] == [
|
||||
"--session",
|
||||
"test-session",
|
||||
"--json",
|
||||
"navigate",
|
||||
]
|
||||
|
||||
def test_subprocess_splits_npx_fallback_into_command_and_package(self, tmp_path):
|
||||
"""The synthetic npx fallback should still expand into separate argv items."""
|
||||
captured_cmd = None
|
||||
|
||||
mock_proc = MagicMock()
|
||||
mock_proc.returncode = 0
|
||||
mock_proc.wait.return_value = 0
|
||||
|
||||
def capture_popen(cmd, **kwargs):
|
||||
nonlocal captured_cmd
|
||||
captured_cmd = cmd
|
||||
return mock_proc
|
||||
|
||||
fake_session = {
|
||||
"session_name": "test-session",
|
||||
"session_id": "test-id",
|
||||
"cdp_url": None,
|
||||
}
|
||||
fake_json = json.dumps({"success": True})
|
||||
hermes_home = str(tmp_path / "hermes-home")
|
||||
|
||||
with patch("tools.browser_tool._find_agent_browser", return_value="npx agent-browser"), \
|
||||
patch("tools.browser_tool._get_session_info", return_value=fake_session), \
|
||||
patch("tools.browser_tool._socket_safe_tmpdir", return_value=str(tmp_path)), \
|
||||
patch("tools.browser_tool._discover_homebrew_node_dirs", return_value=[]), \
|
||||
patch("hermes_constants.Path.home", return_value=tmp_path), \
|
||||
patch("subprocess.Popen", side_effect=capture_popen), \
|
||||
patch("os.open", return_value=99), \
|
||||
patch("os.close"), \
|
||||
patch("tools.interrupt.is_interrupted", return_value=False), \
|
||||
patch.dict(
|
||||
os.environ,
|
||||
{
|
||||
"PATH": "/usr/bin:/bin",
|
||||
"HOME": "/home/test",
|
||||
"HERMES_HOME": hermes_home,
|
||||
},
|
||||
clear=True,
|
||||
):
|
||||
with patch("builtins.open", mock_open(read_data=fake_json)):
|
||||
_run_browser_command("test-task", "navigate", ["https://example.com"])
|
||||
|
||||
assert captured_cmd is not None
|
||||
assert captured_cmd[:2] == ["npx", "agent-browser"]
|
||||
assert captured_cmd[2:6] == [
|
||||
"--session",
|
||||
"test-session",
|
||||
"--json",
|
||||
"navigate",
|
||||
]
|
||||
|
||||
def test_subprocess_path_includes_homebrew_node_dirs(self, tmp_path):
|
||||
"""When _discover_homebrew_node_dirs returns dirs, they should appear
|
||||
in the subprocess env PATH passed to Popen."""
|
||||
|
||||
@@ -197,6 +197,26 @@ class TestCheckpointNotify:
|
||||
s = registry.get("proc_live")
|
||||
assert s.notify_on_complete is True
|
||||
|
||||
def test_recover_requeues_notify_watchers(self, registry, tmp_path):
|
||||
checkpoint = tmp_path / "procs.json"
|
||||
checkpoint.write_text(json.dumps([{
|
||||
"session_id": "proc_live",
|
||||
"command": "sleep 999",
|
||||
"pid": os.getpid(),
|
||||
"task_id": "t1",
|
||||
"session_key": "sk1",
|
||||
"watcher_platform": "telegram",
|
||||
"watcher_chat_id": "123",
|
||||
"watcher_thread_id": "42",
|
||||
"watcher_interval": 5,
|
||||
"notify_on_complete": True,
|
||||
}]))
|
||||
with patch("tools.process_registry.CHECKPOINT_PATH", checkpoint):
|
||||
recovered = registry.recover_from_checkpoint()
|
||||
assert recovered == 1
|
||||
assert len(registry.pending_watchers) == 1
|
||||
assert registry.pending_watchers[0]["notify_on_complete"] is True
|
||||
|
||||
def test_recover_defaults_false(self, registry, tmp_path):
|
||||
"""Old checkpoint entries without the field default to False."""
|
||||
checkpoint = tmp_path / "procs.json"
|
||||
|
||||
@@ -2,6 +2,9 @@
|
||||
|
||||
import json
|
||||
import os
|
||||
import signal
|
||||
import subprocess
|
||||
import sys
|
||||
import time
|
||||
import pytest
|
||||
from pathlib import Path
|
||||
@@ -45,6 +48,23 @@ def _make_session(
|
||||
return s
|
||||
|
||||
|
||||
def _spawn_python_sleep(seconds: float) -> subprocess.Popen:
|
||||
"""Spawn a portable short-lived Python sleep process."""
|
||||
return subprocess.Popen(
|
||||
[sys.executable, "-c", f"import time; time.sleep({seconds})"],
|
||||
)
|
||||
|
||||
|
||||
def _wait_until(predicate, timeout: float = 5.0, interval: float = 0.05) -> bool:
|
||||
"""Poll a predicate until it returns truthy or the timeout elapses."""
|
||||
deadline = time.monotonic() + timeout
|
||||
while time.monotonic() < deadline:
|
||||
if predicate():
|
||||
return True
|
||||
time.sleep(interval)
|
||||
return False
|
||||
|
||||
|
||||
# =========================================================================
|
||||
# Get / Poll
|
||||
# =========================================================================
|
||||
@@ -349,6 +369,88 @@ class TestCheckpoint:
|
||||
assert recovered == 1
|
||||
assert len(registry.pending_watchers) == 0
|
||||
|
||||
def test_recovery_keeps_live_checkpoint_entries(self, registry, tmp_path):
|
||||
checkpoint = tmp_path / "procs.json"
|
||||
checkpoint.write_text(json.dumps([{
|
||||
"session_id": "proc_live",
|
||||
"command": "sleep 999",
|
||||
"pid": os.getpid(),
|
||||
"task_id": "t1",
|
||||
"session_key": "sk1",
|
||||
}]))
|
||||
|
||||
with patch("tools.process_registry.CHECKPOINT_PATH", checkpoint):
|
||||
recovered = registry.recover_from_checkpoint()
|
||||
assert recovered == 1
|
||||
assert registry.get("proc_live") is not None
|
||||
|
||||
data = json.loads(checkpoint.read_text())
|
||||
assert len(data) == 1
|
||||
assert data[0]["session_id"] == "proc_live"
|
||||
assert data[0]["pid"] == os.getpid()
|
||||
assert data != []
|
||||
|
||||
def test_recovery_skips_explicit_sandbox_backed_entries(self, registry, tmp_path):
|
||||
checkpoint = tmp_path / "procs.json"
|
||||
original = [{
|
||||
"session_id": "proc_remote",
|
||||
"command": "sleep 999",
|
||||
"pid": os.getpid(),
|
||||
"task_id": "t1",
|
||||
"pid_scope": "sandbox",
|
||||
}]
|
||||
checkpoint.write_text(json.dumps(original))
|
||||
|
||||
with patch("tools.process_registry.CHECKPOINT_PATH", checkpoint):
|
||||
recovered = registry.recover_from_checkpoint()
|
||||
assert recovered == 0
|
||||
assert registry.get("proc_remote") is None
|
||||
|
||||
data = json.loads(checkpoint.read_text())
|
||||
assert data == []
|
||||
|
||||
def test_detached_recovered_process_eventually_exits(self, registry, tmp_path):
|
||||
proc = _spawn_python_sleep(0.4)
|
||||
checkpoint = tmp_path / "procs.json"
|
||||
checkpoint.write_text(json.dumps([{
|
||||
"session_id": "proc_live",
|
||||
"command": "python -c 'import time; time.sleep(0.4)'",
|
||||
"pid": proc.pid,
|
||||
"task_id": "t1",
|
||||
"session_key": "sk1",
|
||||
}]))
|
||||
|
||||
try:
|
||||
with patch("tools.process_registry.CHECKPOINT_PATH", checkpoint):
|
||||
recovered = registry.recover_from_checkpoint()
|
||||
assert recovered == 1
|
||||
|
||||
session = registry.get("proc_live")
|
||||
assert session is not None
|
||||
assert session.detached is True
|
||||
|
||||
proc.wait(timeout=5)
|
||||
|
||||
assert _wait_until(
|
||||
lambda: registry.get("proc_live") is not None
|
||||
and registry.get("proc_live").exited,
|
||||
timeout=5,
|
||||
)
|
||||
|
||||
poll_result = registry.poll("proc_live")
|
||||
assert poll_result["status"] == "exited"
|
||||
|
||||
wait_result = registry.wait("proc_live", timeout=1)
|
||||
assert wait_result["status"] == "exited"
|
||||
finally:
|
||||
if proc.poll() is None:
|
||||
proc.terminate()
|
||||
try:
|
||||
proc.wait(timeout=5)
|
||||
except Exception:
|
||||
proc.kill()
|
||||
proc.wait(timeout=5)
|
||||
|
||||
|
||||
# =========================================================================
|
||||
# Kill process
|
||||
@@ -365,6 +467,27 @@ class TestKillProcess:
|
||||
result = registry.kill_process(s.id)
|
||||
assert result["status"] == "already_exited"
|
||||
|
||||
def test_kill_detached_session_uses_host_pid(self, registry):
|
||||
s = _make_session(sid="proc_detached", command="sleep 999")
|
||||
s.pid = 424242
|
||||
s.detached = True
|
||||
registry._running[s.id] = s
|
||||
|
||||
calls = []
|
||||
|
||||
def fake_kill(pid, sig):
|
||||
calls.append((pid, sig))
|
||||
|
||||
try:
|
||||
with patch("tools.process_registry.os.kill", side_effect=fake_kill):
|
||||
result = registry.kill_process(s.id)
|
||||
|
||||
assert result["status"] == "killed"
|
||||
assert (424242, 0) in calls
|
||||
assert (424242, signal.SIGTERM) in calls
|
||||
finally:
|
||||
registry._running.pop(s.id, None)
|
||||
|
||||
|
||||
# =========================================================================
|
||||
# Tool handler
|
||||
|
||||
@@ -0,0 +1,472 @@
|
||||
"""Tests for tools/tool_result_storage.py -- 3-layer tool result persistence."""
|
||||
|
||||
import pytest
|
||||
from unittest.mock import MagicMock, patch
|
||||
|
||||
from tools.budget_config import (
|
||||
DEFAULT_RESULT_SIZE_CHARS,
|
||||
DEFAULT_TURN_BUDGET_CHARS,
|
||||
DEFAULT_PREVIEW_SIZE_CHARS,
|
||||
BudgetConfig,
|
||||
)
|
||||
from tools.tool_result_storage import (
|
||||
HEREDOC_MARKER,
|
||||
PERSISTED_OUTPUT_TAG,
|
||||
PERSISTED_OUTPUT_CLOSING_TAG,
|
||||
STORAGE_DIR,
|
||||
_build_persisted_message,
|
||||
_heredoc_marker,
|
||||
_write_to_sandbox,
|
||||
enforce_turn_budget,
|
||||
generate_preview,
|
||||
maybe_persist_tool_result,
|
||||
)
|
||||
|
||||
|
||||
# ── generate_preview ──────────────────────────────────────────────────
|
||||
|
||||
class TestGeneratePreview:
|
||||
def test_short_content_unchanged(self):
|
||||
text = "short result"
|
||||
preview, has_more = generate_preview(text)
|
||||
assert preview == text
|
||||
assert has_more is False
|
||||
|
||||
def test_long_content_truncated(self):
|
||||
text = "x" * 5000
|
||||
preview, has_more = generate_preview(text, max_chars=2000)
|
||||
assert len(preview) <= 2000
|
||||
assert has_more is True
|
||||
|
||||
def test_truncates_at_newline_boundary(self):
|
||||
# 1500 chars + newline + 600 chars (past halfway)
|
||||
text = "a" * 1500 + "\n" + "b" * 600
|
||||
preview, has_more = generate_preview(text, max_chars=2000)
|
||||
assert preview == "a" * 1500 + "\n"
|
||||
assert has_more is True
|
||||
|
||||
def test_ignores_early_newline(self):
|
||||
# Newline at position 100, well before halfway of 2000
|
||||
text = "a" * 100 + "\n" + "b" * 3000
|
||||
preview, has_more = generate_preview(text, max_chars=2000)
|
||||
assert len(preview) == 2000
|
||||
assert has_more is True
|
||||
|
||||
def test_empty_content(self):
|
||||
preview, has_more = generate_preview("")
|
||||
assert preview == ""
|
||||
assert has_more is False
|
||||
|
||||
def test_exact_boundary(self):
|
||||
text = "x" * DEFAULT_PREVIEW_SIZE_CHARS
|
||||
preview, has_more = generate_preview(text)
|
||||
assert preview == text
|
||||
assert has_more is False
|
||||
|
||||
|
||||
# ── _heredoc_marker ───────────────────────────────────────────────────
|
||||
|
||||
class TestHeredocMarker:
|
||||
def test_default_marker_when_no_collision(self):
|
||||
assert _heredoc_marker("normal content") == HEREDOC_MARKER
|
||||
|
||||
def test_uuid_marker_on_collision(self):
|
||||
content = f"some text with {HEREDOC_MARKER} embedded"
|
||||
marker = _heredoc_marker(content)
|
||||
assert marker != HEREDOC_MARKER
|
||||
assert marker.startswith("HERMES_PERSIST_")
|
||||
assert marker not in content
|
||||
|
||||
|
||||
# ── _write_to_sandbox ─────────────────────────────────────────────────
|
||||
|
||||
class TestWriteToSandbox:
|
||||
def test_success(self):
|
||||
env = MagicMock()
|
||||
env.execute.return_value = {"output": "", "returncode": 0}
|
||||
result = _write_to_sandbox("hello world", "/tmp/hermes-results/abc.txt", env)
|
||||
assert result is True
|
||||
env.execute.assert_called_once()
|
||||
cmd = env.execute.call_args[0][0]
|
||||
assert "mkdir -p" in cmd
|
||||
assert "hello world" in cmd
|
||||
assert HEREDOC_MARKER in cmd
|
||||
|
||||
def test_failure_returns_false(self):
|
||||
env = MagicMock()
|
||||
env.execute.return_value = {"output": "error", "returncode": 1}
|
||||
result = _write_to_sandbox("content", "/tmp/hermes-results/abc.txt", env)
|
||||
assert result is False
|
||||
|
||||
def test_heredoc_collision_uses_uuid_marker(self):
|
||||
env = MagicMock()
|
||||
env.execute.return_value = {"output": "", "returncode": 0}
|
||||
content = f"text with {HEREDOC_MARKER} inside"
|
||||
_write_to_sandbox(content, "/tmp/hermes-results/abc.txt", env)
|
||||
cmd = env.execute.call_args[0][0]
|
||||
# The default marker should NOT be used as the delimiter
|
||||
lines = cmd.split("\n")
|
||||
# The first and last lines contain the actual delimiter
|
||||
assert HEREDOC_MARKER not in lines[0].split("<<")[1]
|
||||
|
||||
def test_timeout_passed(self):
|
||||
env = MagicMock()
|
||||
env.execute.return_value = {"output": "", "returncode": 0}
|
||||
_write_to_sandbox("content", "/tmp/hermes-results/abc.txt", env)
|
||||
assert env.execute.call_args[1]["timeout"] == 30
|
||||
|
||||
|
||||
# ── _build_persisted_message ──────────────────────────────────────────
|
||||
|
||||
class TestBuildPersistedMessage:
|
||||
def test_structure(self):
|
||||
msg = _build_persisted_message(
|
||||
preview="first 100 chars...",
|
||||
has_more=True,
|
||||
original_size=50_000,
|
||||
file_path="/tmp/hermes-results/test123.txt",
|
||||
)
|
||||
assert msg.startswith(PERSISTED_OUTPUT_TAG)
|
||||
assert msg.endswith(PERSISTED_OUTPUT_CLOSING_TAG)
|
||||
assert "50,000 characters" in msg
|
||||
assert "/tmp/hermes-results/test123.txt" in msg
|
||||
assert "read_file" in msg
|
||||
assert "first 100 chars..." in msg
|
||||
assert "..." in msg # has_more indicator
|
||||
|
||||
def test_no_ellipsis_when_complete(self):
|
||||
msg = _build_persisted_message(
|
||||
preview="complete content",
|
||||
has_more=False,
|
||||
original_size=16,
|
||||
file_path="/tmp/hermes-results/x.txt",
|
||||
)
|
||||
# Should not have the trailing "..." indicator before closing tag
|
||||
lines = msg.strip().split("\n")
|
||||
assert lines[-2] != "..."
|
||||
|
||||
def test_large_size_shows_mb(self):
|
||||
msg = _build_persisted_message(
|
||||
preview="x",
|
||||
has_more=True,
|
||||
original_size=2_000_000,
|
||||
file_path="/tmp/hermes-results/big.txt",
|
||||
)
|
||||
assert "MB" in msg
|
||||
|
||||
|
||||
# ── maybe_persist_tool_result ─────────────────────────────────────────
|
||||
|
||||
class TestMaybePersistToolResult:
|
||||
def test_below_threshold_returns_unchanged(self):
|
||||
content = "small result"
|
||||
result = maybe_persist_tool_result(
|
||||
content=content,
|
||||
tool_name="terminal",
|
||||
tool_use_id="tc_123",
|
||||
env=None,
|
||||
threshold=50_000,
|
||||
)
|
||||
assert result == content
|
||||
|
||||
def test_above_threshold_with_env_persists(self):
|
||||
env = MagicMock()
|
||||
env.execute.return_value = {"output": "", "returncode": 0}
|
||||
content = "x" * 60_000
|
||||
result = maybe_persist_tool_result(
|
||||
content=content,
|
||||
tool_name="terminal",
|
||||
tool_use_id="tc_456",
|
||||
env=env,
|
||||
threshold=30_000,
|
||||
)
|
||||
assert PERSISTED_OUTPUT_TAG in result
|
||||
assert "tc_456.txt" in result
|
||||
assert len(result) < len(content)
|
||||
env.execute.assert_called_once()
|
||||
|
||||
def test_persists_full_content_as_is(self):
|
||||
"""Content is persisted verbatim — no JSON extraction."""
|
||||
import json
|
||||
env = MagicMock()
|
||||
env.execute.return_value = {"output": "", "returncode": 0}
|
||||
raw = "line1\nline2\n" * 5_000
|
||||
content = json.dumps({"output": raw, "exit_code": 0, "error": None})
|
||||
result = maybe_persist_tool_result(
|
||||
content=content,
|
||||
tool_name="terminal",
|
||||
tool_use_id="tc_json",
|
||||
env=env,
|
||||
threshold=30_000,
|
||||
)
|
||||
assert PERSISTED_OUTPUT_TAG in result
|
||||
# The heredoc written to sandbox should contain the full JSON blob
|
||||
cmd = env.execute.call_args[0][0]
|
||||
assert '"exit_code"' in cmd
|
||||
|
||||
def test_above_threshold_no_env_truncates_inline(self):
|
||||
content = "x" * 60_000
|
||||
result = maybe_persist_tool_result(
|
||||
content=content,
|
||||
tool_name="terminal",
|
||||
tool_use_id="tc_789",
|
||||
env=None,
|
||||
threshold=30_000,
|
||||
)
|
||||
assert PERSISTED_OUTPUT_TAG not in result
|
||||
assert "Truncated" in result
|
||||
assert len(result) < len(content)
|
||||
|
||||
def test_env_write_failure_falls_back_to_truncation(self):
|
||||
env = MagicMock()
|
||||
env.execute.return_value = {"output": "disk full", "returncode": 1}
|
||||
content = "x" * 60_000
|
||||
result = maybe_persist_tool_result(
|
||||
content=content,
|
||||
tool_name="terminal",
|
||||
tool_use_id="tc_fail",
|
||||
env=env,
|
||||
threshold=30_000,
|
||||
)
|
||||
assert PERSISTED_OUTPUT_TAG not in result
|
||||
assert "Truncated" in result
|
||||
|
||||
def test_env_execute_exception_falls_back(self):
|
||||
env = MagicMock()
|
||||
env.execute.side_effect = RuntimeError("connection lost")
|
||||
content = "x" * 60_000
|
||||
result = maybe_persist_tool_result(
|
||||
content=content,
|
||||
tool_name="terminal",
|
||||
tool_use_id="tc_exc",
|
||||
env=env,
|
||||
threshold=30_000,
|
||||
)
|
||||
assert "Truncated" in result
|
||||
|
||||
def test_read_file_never_persisted(self):
|
||||
"""read_file has threshold=inf, should never be persisted."""
|
||||
env = MagicMock()
|
||||
content = "x" * 200_000
|
||||
result = maybe_persist_tool_result(
|
||||
content=content,
|
||||
tool_name="read_file",
|
||||
tool_use_id="tc_rf",
|
||||
env=env,
|
||||
threshold=float("inf"),
|
||||
)
|
||||
assert result == content
|
||||
env.execute.assert_not_called()
|
||||
|
||||
def test_uses_registry_threshold_when_not_provided(self):
|
||||
"""When threshold=None, looks up from registry."""
|
||||
env = MagicMock()
|
||||
env.execute.return_value = {"output": "", "returncode": 0}
|
||||
content = "x" * 60_000
|
||||
|
||||
mock_registry = MagicMock()
|
||||
mock_registry.get_max_result_size.return_value = 30_000
|
||||
|
||||
with patch("tools.registry.registry", mock_registry):
|
||||
result = maybe_persist_tool_result(
|
||||
content=content,
|
||||
tool_name="terminal",
|
||||
tool_use_id="tc_reg",
|
||||
env=env,
|
||||
threshold=None,
|
||||
)
|
||||
# Should have persisted since 60K > 30K
|
||||
assert PERSISTED_OUTPUT_TAG in result or "Truncated" in result
|
||||
|
||||
def test_unicode_content_survives(self):
|
||||
env = MagicMock()
|
||||
env.execute.return_value = {"output": "", "returncode": 0}
|
||||
content = "日本語テスト " * 10_000 # ~60K chars of unicode
|
||||
result = maybe_persist_tool_result(
|
||||
content=content,
|
||||
tool_name="terminal",
|
||||
tool_use_id="tc_uni",
|
||||
env=env,
|
||||
threshold=30_000,
|
||||
)
|
||||
assert PERSISTED_OUTPUT_TAG in result
|
||||
# Preview should contain unicode
|
||||
assert "日本語テスト" in result
|
||||
|
||||
def test_empty_content_returns_unchanged(self):
|
||||
result = maybe_persist_tool_result(
|
||||
content="",
|
||||
tool_name="terminal",
|
||||
tool_use_id="tc_empty",
|
||||
env=None,
|
||||
threshold=30_000,
|
||||
)
|
||||
assert result == ""
|
||||
|
||||
def test_whitespace_only_below_threshold(self):
|
||||
content = " " * 100
|
||||
result = maybe_persist_tool_result(
|
||||
content=content,
|
||||
tool_name="terminal",
|
||||
tool_use_id="tc_ws",
|
||||
env=None,
|
||||
threshold=30_000,
|
||||
)
|
||||
assert result == content
|
||||
|
||||
def test_file_path_uses_tool_use_id(self):
|
||||
env = MagicMock()
|
||||
env.execute.return_value = {"output": "", "returncode": 0}
|
||||
content = "x" * 60_000
|
||||
result = maybe_persist_tool_result(
|
||||
content=content,
|
||||
tool_name="terminal",
|
||||
tool_use_id="unique_id_abc",
|
||||
env=env,
|
||||
threshold=30_000,
|
||||
)
|
||||
assert "unique_id_abc.txt" in result
|
||||
|
||||
def test_preview_included_in_persisted_output(self):
|
||||
env = MagicMock()
|
||||
env.execute.return_value = {"output": "", "returncode": 0}
|
||||
# Create content with a distinctive start
|
||||
content = "DISTINCTIVE_START_MARKER" + "x" * 60_000
|
||||
result = maybe_persist_tool_result(
|
||||
content=content,
|
||||
tool_name="terminal",
|
||||
tool_use_id="tc_prev",
|
||||
env=env,
|
||||
threshold=30_000,
|
||||
)
|
||||
assert "DISTINCTIVE_START_MARKER" in result
|
||||
|
||||
def test_threshold_zero_forces_persist(self):
|
||||
env = MagicMock()
|
||||
env.execute.return_value = {"output": "", "returncode": 0}
|
||||
content = "even short content"
|
||||
result = maybe_persist_tool_result(
|
||||
content=content,
|
||||
tool_name="terminal",
|
||||
tool_use_id="tc_zero",
|
||||
env=env,
|
||||
threshold=0,
|
||||
)
|
||||
# Any non-empty content with threshold=0 should be persisted
|
||||
assert PERSISTED_OUTPUT_TAG in result
|
||||
|
||||
|
||||
# ── enforce_turn_budget ───────────────────────────────────────────────
|
||||
|
||||
class TestEnforceTurnBudget:
|
||||
def test_under_budget_no_changes(self):
|
||||
msgs = [
|
||||
{"role": "tool", "tool_call_id": "t1", "content": "small"},
|
||||
{"role": "tool", "tool_call_id": "t2", "content": "also small"},
|
||||
]
|
||||
result = enforce_turn_budget(msgs, env=None, config=BudgetConfig(turn_budget=200_000))
|
||||
assert result[0]["content"] == "small"
|
||||
assert result[1]["content"] == "also small"
|
||||
|
||||
def test_over_budget_largest_persisted_first(self):
|
||||
env = MagicMock()
|
||||
env.execute.return_value = {"output": "", "returncode": 0}
|
||||
msgs = [
|
||||
{"role": "tool", "tool_call_id": "t1", "content": "a" * 80_000},
|
||||
{"role": "tool", "tool_call_id": "t2", "content": "b" * 130_000},
|
||||
]
|
||||
# Total 210K > 200K budget
|
||||
enforce_turn_budget(msgs, env=env, config=BudgetConfig(turn_budget=200_000))
|
||||
# The larger one (130K) should be persisted first
|
||||
assert PERSISTED_OUTPUT_TAG in msgs[1]["content"]
|
||||
|
||||
def test_already_persisted_results_skipped(self):
|
||||
env = MagicMock()
|
||||
env.execute.return_value = {"output": "", "returncode": 0}
|
||||
msgs = [
|
||||
{"role": "tool", "tool_call_id": "t1",
|
||||
"content": f"{PERSISTED_OUTPUT_TAG}\nalready persisted\n{PERSISTED_OUTPUT_CLOSING_TAG}"},
|
||||
{"role": "tool", "tool_call_id": "t2", "content": "x" * 250_000},
|
||||
]
|
||||
enforce_turn_budget(msgs, env=env, config=BudgetConfig(turn_budget=200_000))
|
||||
# t1 should be untouched (already persisted)
|
||||
assert msgs[0]["content"].startswith(PERSISTED_OUTPUT_TAG)
|
||||
# t2 should be persisted
|
||||
assert PERSISTED_OUTPUT_TAG in msgs[1]["content"]
|
||||
|
||||
def test_medium_result_regression(self):
|
||||
"""6 results of 42K chars each (252K total) — each under 100K default
|
||||
threshold but aggregate exceeds 200K budget. L3 should persist."""
|
||||
env = MagicMock()
|
||||
env.execute.return_value = {"output": "", "returncode": 0}
|
||||
msgs = [
|
||||
{"role": "tool", "tool_call_id": f"t{i}", "content": "x" * 42_000}
|
||||
for i in range(6)
|
||||
]
|
||||
enforce_turn_budget(msgs, env=env, config=BudgetConfig(turn_budget=200_000))
|
||||
# At least some results should be persisted to get under 200K
|
||||
persisted_count = sum(
|
||||
1 for m in msgs if PERSISTED_OUTPUT_TAG in m["content"]
|
||||
)
|
||||
assert persisted_count >= 2 # Need to shed at least ~52K
|
||||
|
||||
def test_no_env_falls_back_to_truncation(self):
|
||||
msgs = [
|
||||
{"role": "tool", "tool_call_id": "t1", "content": "x" * 250_000},
|
||||
]
|
||||
enforce_turn_budget(msgs, env=None, config=BudgetConfig(turn_budget=200_000))
|
||||
# Should be truncated (no sandbox available)
|
||||
assert "Truncated" in msgs[0]["content"] or PERSISTED_OUTPUT_TAG in msgs[0]["content"]
|
||||
|
||||
def test_returns_same_list(self):
|
||||
msgs = [{"role": "tool", "tool_call_id": "t1", "content": "ok"}]
|
||||
result = enforce_turn_budget(msgs, env=None, config=BudgetConfig(turn_budget=200_000))
|
||||
assert result is msgs
|
||||
|
||||
def test_empty_messages(self):
|
||||
result = enforce_turn_budget([], env=None, config=BudgetConfig(turn_budget=200_000))
|
||||
assert result == []
|
||||
|
||||
|
||||
# ── Per-tool threshold integration ────────────────────────────────────
|
||||
|
||||
class TestPerToolThresholds:
|
||||
"""Verify registry wiring for per-tool thresholds."""
|
||||
|
||||
def test_registry_has_get_max_result_size(self):
|
||||
from tools.registry import registry
|
||||
assert hasattr(registry, "get_max_result_size")
|
||||
|
||||
def test_default_threshold(self):
|
||||
from tools.registry import registry
|
||||
# Unknown tool should return the default
|
||||
val = registry.get_max_result_size("nonexistent_tool_xyz")
|
||||
assert val == DEFAULT_RESULT_SIZE_CHARS
|
||||
|
||||
def test_terminal_threshold(self):
|
||||
from tools.registry import registry
|
||||
# Trigger import of terminal_tool to register the tool
|
||||
try:
|
||||
import tools.terminal_tool # noqa: F401
|
||||
val = registry.get_max_result_size("terminal")
|
||||
assert val == 100_000
|
||||
except ImportError:
|
||||
pytest.skip("terminal_tool not importable in test env")
|
||||
|
||||
def test_read_file_never_persisted(self):
|
||||
from tools.registry import registry
|
||||
try:
|
||||
import tools.file_tools # noqa: F401
|
||||
val = registry.get_max_result_size("read_file")
|
||||
assert val == float("inf")
|
||||
except ImportError:
|
||||
pytest.skip("file_tools not importable in test env")
|
||||
|
||||
def test_search_files_threshold(self):
|
||||
from tools.registry import registry
|
||||
try:
|
||||
import tools.file_tools # noqa: F401
|
||||
val = registry.get_max_result_size("search_files")
|
||||
assert val == 100_000
|
||||
except ImportError:
|
||||
pytest.skip("file_tools not importable in test env")
|
||||
@@ -0,0 +1,42 @@
|
||||
"""Binary file extensions to skip for text-based operations.
|
||||
|
||||
These files can't be meaningfully compared as text and are often large.
|
||||
Ported from free-code src/constants/files.ts.
|
||||
"""
|
||||
|
||||
BINARY_EXTENSIONS = frozenset({
|
||||
# Images
|
||||
".png", ".jpg", ".jpeg", ".gif", ".bmp", ".ico", ".webp", ".tiff", ".tif",
|
||||
# Videos
|
||||
".mp4", ".mov", ".avi", ".mkv", ".webm", ".wmv", ".flv", ".m4v", ".mpeg", ".mpg",
|
||||
# Audio
|
||||
".mp3", ".wav", ".ogg", ".flac", ".aac", ".m4a", ".wma", ".aiff", ".opus",
|
||||
# Archives
|
||||
".zip", ".tar", ".gz", ".bz2", ".7z", ".rar", ".xz", ".z", ".tgz", ".iso",
|
||||
# Executables/binaries
|
||||
".exe", ".dll", ".so", ".dylib", ".bin", ".o", ".a", ".obj", ".lib",
|
||||
".app", ".msi", ".deb", ".rpm",
|
||||
# Documents (exclude .pdf — text-based, agents may want to inspect)
|
||||
".doc", ".docx", ".xls", ".xlsx", ".ppt", ".pptx",
|
||||
".odt", ".ods", ".odp",
|
||||
# Fonts
|
||||
".ttf", ".otf", ".woff", ".woff2", ".eot",
|
||||
# Bytecode / VM artifacts
|
||||
".pyc", ".pyo", ".class", ".jar", ".war", ".ear", ".node", ".wasm", ".rlib",
|
||||
# Database files
|
||||
".sqlite", ".sqlite3", ".db", ".mdb", ".idx",
|
||||
# Design / 3D
|
||||
".psd", ".ai", ".eps", ".sketch", ".fig", ".xd", ".blend", ".3ds", ".max",
|
||||
# Flash
|
||||
".swf", ".fla",
|
||||
# Lock/profiling data
|
||||
".lockb", ".dat", ".data",
|
||||
})
|
||||
|
||||
|
||||
def has_binary_extension(path: str) -> bool:
|
||||
"""Check if a file path has a binary extension. Pure string check, no I/O."""
|
||||
dot = path.rfind(".")
|
||||
if dot == -1:
|
||||
return False
|
||||
return path[dot:].lower() in BINARY_EXTENSIONS
|
||||
@@ -877,7 +877,11 @@ def _run_browser_command(
|
||||
# Local mode — launch a headless Chromium instance
|
||||
backend_args = ["--session", session_info["session_name"]]
|
||||
|
||||
cmd_parts = browser_cmd.split() + backend_args + [
|
||||
# Keep concrete executable paths intact, even when they contain spaces.
|
||||
# Only the synthetic npx fallback needs to expand into multiple argv items.
|
||||
cmd_prefix = ["npx", "agent-browser"] if browser_cmd == "npx agent-browser" else [browser_cmd]
|
||||
|
||||
cmd_parts = cmd_prefix + backend_args + [
|
||||
"--json",
|
||||
command
|
||||
] + args
|
||||
|
||||
@@ -0,0 +1,52 @@
|
||||
"""Configurable budget constants for tool result persistence.
|
||||
|
||||
Overridable at the RL environment level via HermesAgentEnvConfig fields.
|
||||
Per-tool resolution: pinned > config overrides > registry > default.
|
||||
"""
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Dict
|
||||
|
||||
# Tools whose thresholds must never be overridden.
|
||||
# read_file=inf prevents infinite persist->read->persist loops.
|
||||
PINNED_THRESHOLDS: Dict[str, float] = {
|
||||
"read_file": float("inf"),
|
||||
}
|
||||
|
||||
# Defaults matching the current hardcoded values in tool_result_storage.py.
|
||||
# Kept here as the single source of truth; tool_result_storage.py imports these.
|
||||
DEFAULT_RESULT_SIZE_CHARS: int = 100_000
|
||||
DEFAULT_TURN_BUDGET_CHARS: int = 200_000
|
||||
DEFAULT_PREVIEW_SIZE_CHARS: int = 1_500
|
||||
|
||||
|
||||
@dataclass(frozen=True)
|
||||
class BudgetConfig:
|
||||
"""Immutable budget constants for the 3-layer tool result persistence system.
|
||||
|
||||
Layer 2 (per-result): resolve_threshold(tool_name) -> threshold in chars.
|
||||
Layer 3 (per-turn): turn_budget -> aggregate char budget across all tool
|
||||
results in a single assistant turn.
|
||||
Preview: preview_size -> inline snippet size after persistence.
|
||||
"""
|
||||
|
||||
default_result_size: int = DEFAULT_RESULT_SIZE_CHARS
|
||||
turn_budget: int = DEFAULT_TURN_BUDGET_CHARS
|
||||
preview_size: int = DEFAULT_PREVIEW_SIZE_CHARS
|
||||
tool_overrides: Dict[str, int] = field(default_factory=dict)
|
||||
|
||||
def resolve_threshold(self, tool_name: str) -> int | float:
|
||||
"""Resolve the persistence threshold for a tool.
|
||||
|
||||
Priority: pinned -> tool_overrides -> registry per-tool -> default.
|
||||
"""
|
||||
if tool_name in PINNED_THRESHOLDS:
|
||||
return PINNED_THRESHOLDS[tool_name]
|
||||
if tool_name in self.tool_overrides:
|
||||
return self.tool_overrides[tool_name]
|
||||
from tools.registry import registry
|
||||
return registry.get_max_result_size(tool_name, default=self.default_result_size)
|
||||
|
||||
|
||||
# Default config -- matches current hardcoded behavior exactly.
|
||||
DEFAULT_BUDGET = BudgetConfig()
|
||||
@@ -1343,4 +1343,5 @@ registry.register(
|
||||
enabled_tools=kw.get("enabled_tools")),
|
||||
check_fn=check_sandbox_requirements,
|
||||
emoji="🐍",
|
||||
max_result_size_chars=100_000,
|
||||
)
|
||||
|
||||
@@ -195,6 +195,7 @@ def _format_job(job: Dict[str, Any]) -> Dict[str, Any]:
|
||||
"next_run_at": job.get("next_run_at"),
|
||||
"last_run_at": job.get("last_run_at"),
|
||||
"last_status": job.get("last_status"),
|
||||
"last_delivery_error": job.get("last_delivery_error"),
|
||||
"enabled": job.get("enabled", True),
|
||||
"state": job.get("state", "scheduled" if job.get("enabled", True) else "paused"),
|
||||
"paused_at": job.get("paused_at"),
|
||||
|
||||
@@ -33,6 +33,7 @@ from dataclasses import dataclass, field
|
||||
from typing import Optional, List, Dict, Any
|
||||
from pathlib import Path
|
||||
from hermes_constants import get_hermes_home
|
||||
from tools.binary_extensions import BINARY_EXTENSIONS
|
||||
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
@@ -280,26 +281,6 @@ class FileOperations(ABC):
|
||||
# Shell-based Implementation
|
||||
# =============================================================================
|
||||
|
||||
# Binary file extensions (fast path check)
|
||||
BINARY_EXTENSIONS = {
|
||||
# Images
|
||||
'.png', '.jpg', '.jpeg', '.gif', '.webp', '.bmp', '.ico', '.tiff', '.tif',
|
||||
'.svg', # SVG is text but often treated as binary
|
||||
# Audio/Video
|
||||
'.mp3', '.mp4', '.wav', '.avi', '.mov', '.mkv', '.flac', '.ogg', '.webm',
|
||||
# Archives
|
||||
'.zip', '.tar', '.gz', '.bz2', '.xz', '.7z', '.rar',
|
||||
# Documents
|
||||
'.pdf', '.doc', '.docx', '.xls', '.xlsx', '.ppt', '.pptx',
|
||||
# Compiled/Binary
|
||||
'.exe', '.dll', '.so', '.dylib', '.o', '.a', '.pyc', '.pyo', '.class',
|
||||
'.wasm', '.bin',
|
||||
# Fonts
|
||||
'.ttf', '.otf', '.woff', '.woff2', '.eot',
|
||||
# Other
|
||||
'.db', '.sqlite', '.sqlite3',
|
||||
}
|
||||
|
||||
# Image extensions (subset of binary that we can return as base64)
|
||||
IMAGE_EXTENSIONS = {'.png', '.jpg', '.jpeg', '.gif', '.webp', '.bmp', '.ico'}
|
||||
|
||||
|
||||
+18
-6
@@ -7,6 +7,7 @@ import logging
|
||||
import os
|
||||
import threading
|
||||
from pathlib import Path
|
||||
from tools.binary_extensions import has_binary_extension
|
||||
from tools.file_operations import ShellFileOperations
|
||||
from agent.redact import redact_sensitive_text
|
||||
|
||||
@@ -290,11 +291,22 @@ def read_file_tool(path: str, offset: int = 1, limit: int = 500, task_id: str =
|
||||
),
|
||||
})
|
||||
|
||||
_resolved = Path(path).expanduser().resolve()
|
||||
|
||||
# ── Binary file guard ─────────────────────────────────────────
|
||||
# Block binary files by extension (no I/O).
|
||||
if has_binary_extension(str(_resolved)):
|
||||
_ext = _resolved.suffix.lower()
|
||||
return json.dumps({
|
||||
"error": (
|
||||
f"Cannot read binary file '{path}' ({_ext}). "
|
||||
"Use vision_analyze for images, or terminal to inspect binary files."
|
||||
),
|
||||
})
|
||||
|
||||
# ── Hermes internal path guard ────────────────────────────────
|
||||
# Prevent prompt injection via catalog or hub metadata files.
|
||||
import pathlib as _pathlib
|
||||
from hermes_constants import get_hermes_home as _get_hh
|
||||
_resolved = _pathlib.Path(path).expanduser().resolve()
|
||||
_hermes_home = _get_hh().resolve()
|
||||
_blocked_dirs = [
|
||||
_hermes_home / "skills" / ".hub" / "index-cache",
|
||||
@@ -817,7 +829,7 @@ def _handle_search_files(args, **kw):
|
||||
output_mode=args.get("output_mode", "content"), context=args.get("context", 0), task_id=tid)
|
||||
|
||||
|
||||
registry.register(name="read_file", toolset="file", schema=READ_FILE_SCHEMA, handler=_handle_read_file, check_fn=_check_file_reqs, emoji="📖")
|
||||
registry.register(name="write_file", toolset="file", schema=WRITE_FILE_SCHEMA, handler=_handle_write_file, check_fn=_check_file_reqs, emoji="✍️")
|
||||
registry.register(name="patch", toolset="file", schema=PATCH_SCHEMA, handler=_handle_patch, check_fn=_check_file_reqs, emoji="🔧")
|
||||
registry.register(name="search_files", toolset="file", schema=SEARCH_FILES_SCHEMA, handler=_handle_search_files, check_fn=_check_file_reqs, emoji="🔎")
|
||||
registry.register(name="read_file", toolset="file", schema=READ_FILE_SCHEMA, handler=_handle_read_file, check_fn=_check_file_reqs, emoji="📖", max_result_size_chars=float('inf'))
|
||||
registry.register(name="write_file", toolset="file", schema=WRITE_FILE_SCHEMA, handler=_handle_write_file, check_fn=_check_file_reqs, emoji="✍️", max_result_size_chars=100_000)
|
||||
registry.register(name="patch", toolset="file", schema=PATCH_SCHEMA, handler=_handle_patch, check_fn=_check_file_reqs, emoji="🔧", max_result_size_chars=100_000)
|
||||
registry.register(name="search_files", toolset="file", schema=SEARCH_FILES_SCHEMA, handler=_handle_search_files, check_fn=_check_file_reqs, emoji="🔎", max_result_size_chars=100_000)
|
||||
|
||||
+98
-13
@@ -76,6 +76,7 @@ class ProcessSession:
|
||||
output_buffer: str = "" # Rolling output (last MAX_OUTPUT_CHARS)
|
||||
max_output_chars: int = MAX_OUTPUT_CHARS
|
||||
detached: bool = False # True if recovered from crash (no pipe)
|
||||
pid_scope: str = "host" # "host" for local/PTY PIDs, "sandbox" for env-local PIDs
|
||||
# Watcher/notification metadata (persisted for crash recovery)
|
||||
watcher_platform: str = ""
|
||||
watcher_chat_id: str = ""
|
||||
@@ -127,6 +128,48 @@ class ProcessRegistry:
|
||||
lines.pop(0)
|
||||
return "\n".join(lines)
|
||||
|
||||
@staticmethod
|
||||
def _is_host_pid_alive(pid: Optional[int]) -> bool:
|
||||
"""Best-effort liveness check for host-visible PIDs."""
|
||||
if not pid:
|
||||
return False
|
||||
try:
|
||||
os.kill(pid, 0)
|
||||
return True
|
||||
except (ProcessLookupError, PermissionError):
|
||||
return False
|
||||
|
||||
def _refresh_detached_session(self, session: Optional[ProcessSession]) -> Optional[ProcessSession]:
|
||||
"""Update recovered host-PID sessions when the underlying process has exited."""
|
||||
if session is None or session.exited or not session.detached or session.pid_scope != "host":
|
||||
return session
|
||||
|
||||
if self._is_host_pid_alive(session.pid):
|
||||
return session
|
||||
|
||||
with session._lock:
|
||||
if session.exited:
|
||||
return session
|
||||
session.exited = True
|
||||
# Recovered sessions no longer have a waitable handle, so the real
|
||||
# exit code is unavailable once the original process object is gone.
|
||||
session.exit_code = None
|
||||
|
||||
self._move_to_finished(session)
|
||||
return session
|
||||
|
||||
@staticmethod
|
||||
def _terminate_host_pid(pid: int) -> None:
|
||||
"""Terminate a host-visible PID without requiring the original process handle."""
|
||||
if _IS_WINDOWS:
|
||||
os.kill(pid, signal.SIGTERM)
|
||||
return
|
||||
|
||||
try:
|
||||
os.killpg(os.getpgid(pid), signal.SIGTERM)
|
||||
except (OSError, ProcessLookupError, PermissionError):
|
||||
os.kill(pid, signal.SIGTERM)
|
||||
|
||||
# ----- Spawn -----
|
||||
|
||||
def spawn_local(
|
||||
@@ -269,6 +312,7 @@ class ProcessRegistry:
|
||||
cwd=cwd,
|
||||
started_at=time.time(),
|
||||
env_ref=env,
|
||||
pid_scope="sandbox",
|
||||
)
|
||||
|
||||
# Run the command in the sandbox with output capture
|
||||
@@ -439,7 +483,8 @@ class ProcessRegistry:
|
||||
def get(self, session_id: str) -> Optional[ProcessSession]:
|
||||
"""Get a session by ID (running or finished)."""
|
||||
with self._lock:
|
||||
return self._running.get(session_id) or self._finished.get(session_id)
|
||||
session = self._running.get(session_id) or self._finished.get(session_id)
|
||||
return self._refresh_detached_session(session)
|
||||
|
||||
def poll(self, session_id: str) -> dict:
|
||||
"""Check status and get new output for a background process."""
|
||||
@@ -531,6 +576,7 @@ class ProcessRegistry:
|
||||
deadline = time.monotonic() + effective_timeout
|
||||
|
||||
while time.monotonic() < deadline:
|
||||
session = self._refresh_detached_session(session)
|
||||
if session.exited:
|
||||
result = {
|
||||
"status": "exited",
|
||||
@@ -596,6 +642,25 @@ class ProcessRegistry:
|
||||
elif session.env_ref and session.pid:
|
||||
# Non-local -- kill inside sandbox
|
||||
session.env_ref.execute(f"kill {session.pid} 2>/dev/null", timeout=5)
|
||||
elif session.detached and session.pid_scope == "host" and session.pid:
|
||||
if not self._is_host_pid_alive(session.pid):
|
||||
with session._lock:
|
||||
session.exited = True
|
||||
session.exit_code = None
|
||||
self._move_to_finished(session)
|
||||
return {
|
||||
"status": "already_exited",
|
||||
"exit_code": session.exit_code,
|
||||
}
|
||||
self._terminate_host_pid(session.pid)
|
||||
else:
|
||||
return {
|
||||
"status": "error",
|
||||
"error": (
|
||||
"Recovered process cannot be killed after restart because "
|
||||
"its original runtime handle is no longer available"
|
||||
),
|
||||
}
|
||||
session.exited = True
|
||||
session.exit_code = -15 # SIGTERM
|
||||
self._move_to_finished(session)
|
||||
@@ -640,6 +705,8 @@ class ProcessRegistry:
|
||||
with self._lock:
|
||||
all_sessions = list(self._running.values()) + list(self._finished.values())
|
||||
|
||||
all_sessions = [self._refresh_detached_session(s) for s in all_sessions]
|
||||
|
||||
if task_id:
|
||||
all_sessions = [s for s in all_sessions if s.task_id == task_id]
|
||||
|
||||
@@ -666,6 +733,12 @@ class ProcessRegistry:
|
||||
|
||||
def has_active_processes(self, task_id: str) -> bool:
|
||||
"""Check if there are active (running) processes for a task_id."""
|
||||
with self._lock:
|
||||
sessions = list(self._running.values())
|
||||
|
||||
for session in sessions:
|
||||
self._refresh_detached_session(session)
|
||||
|
||||
with self._lock:
|
||||
return any(
|
||||
s.task_id == task_id and not s.exited
|
||||
@@ -674,6 +747,12 @@ class ProcessRegistry:
|
||||
|
||||
def has_active_for_session(self, session_key: str) -> bool:
|
||||
"""Check if there are active processes for a gateway session key."""
|
||||
with self._lock:
|
||||
sessions = list(self._running.values())
|
||||
|
||||
for session in sessions:
|
||||
self._refresh_detached_session(session)
|
||||
|
||||
with self._lock:
|
||||
return any(
|
||||
s.session_key == session_key and not s.exited
|
||||
@@ -727,6 +806,7 @@ class ProcessRegistry:
|
||||
"session_id": s.id,
|
||||
"command": s.command,
|
||||
"pid": s.pid,
|
||||
"pid_scope": s.pid_scope,
|
||||
"cwd": s.cwd,
|
||||
"started_at": s.started_at,
|
||||
"task_id": s.task_id,
|
||||
@@ -764,13 +844,21 @@ class ProcessRegistry:
|
||||
if not pid:
|
||||
continue
|
||||
|
||||
pid_scope = entry.get("pid_scope", "host")
|
||||
if pid_scope != "host":
|
||||
# Sandbox-backed processes keep only in-sandbox PIDs in the
|
||||
# checkpoint, which are not meaningful to the restarted host
|
||||
# process once the original environment handle is gone.
|
||||
logger.info(
|
||||
"Skipping recovery for non-host process: %s (pid=%s, scope=%s)",
|
||||
entry.get("command", "unknown")[:60],
|
||||
pid,
|
||||
pid_scope,
|
||||
)
|
||||
continue
|
||||
|
||||
# Check if PID is still alive
|
||||
alive = False
|
||||
try:
|
||||
os.kill(pid, 0)
|
||||
alive = True
|
||||
except (ProcessLookupError, PermissionError):
|
||||
pass
|
||||
alive = self._is_host_pid_alive(pid)
|
||||
|
||||
if alive:
|
||||
session = ProcessSession(
|
||||
@@ -779,6 +867,7 @@ class ProcessRegistry:
|
||||
task_id=entry.get("task_id", ""),
|
||||
session_key=entry.get("session_key", ""),
|
||||
pid=pid,
|
||||
pid_scope=pid_scope,
|
||||
cwd=entry.get("cwd"),
|
||||
started_at=entry.get("started_at", time.time()),
|
||||
detached=True, # Can't read output, but can report status + kill
|
||||
@@ -802,14 +891,10 @@ class ProcessRegistry:
|
||||
"platform": session.watcher_platform,
|
||||
"chat_id": session.watcher_chat_id,
|
||||
"thread_id": session.watcher_thread_id,
|
||||
"notify_on_complete": session.notify_on_complete,
|
||||
})
|
||||
|
||||
# Clear the checkpoint (will be rewritten as processes finish)
|
||||
try:
|
||||
from utils import atomic_json_write
|
||||
atomic_json_write(CHECKPOINT_PATH, [])
|
||||
except Exception as e:
|
||||
logger.debug("Could not clear checkpoint file: %s", e, exc_info=True)
|
||||
self._write_checkpoint()
|
||||
|
||||
return recovered
|
||||
|
||||
|
||||
+16
-1
@@ -27,10 +27,12 @@ class ToolEntry:
|
||||
__slots__ = (
|
||||
"name", "toolset", "schema", "handler", "check_fn",
|
||||
"requires_env", "is_async", "description", "emoji",
|
||||
"max_result_size_chars",
|
||||
)
|
||||
|
||||
def __init__(self, name, toolset, schema, handler, check_fn,
|
||||
requires_env, is_async, description, emoji):
|
||||
requires_env, is_async, description, emoji,
|
||||
max_result_size_chars=None):
|
||||
self.name = name
|
||||
self.toolset = toolset
|
||||
self.schema = schema
|
||||
@@ -40,6 +42,7 @@ class ToolEntry:
|
||||
self.is_async = is_async
|
||||
self.description = description
|
||||
self.emoji = emoji
|
||||
self.max_result_size_chars = max_result_size_chars
|
||||
|
||||
|
||||
class ToolRegistry:
|
||||
@@ -64,6 +67,7 @@ class ToolRegistry:
|
||||
is_async: bool = False,
|
||||
description: str = "",
|
||||
emoji: str = "",
|
||||
max_result_size_chars: int | float | None = None,
|
||||
):
|
||||
"""Register a tool. Called at module-import time by each tool file."""
|
||||
existing = self._tools.get(name)
|
||||
@@ -83,6 +87,7 @@ class ToolRegistry:
|
||||
is_async=is_async,
|
||||
description=description or schema.get("description", ""),
|
||||
emoji=emoji,
|
||||
max_result_size_chars=max_result_size_chars,
|
||||
)
|
||||
if check_fn and toolset not in self._toolset_checks:
|
||||
self._toolset_checks[toolset] = check_fn
|
||||
@@ -164,6 +169,16 @@ class ToolRegistry:
|
||||
# Query helpers (replace redundant dicts in model_tools.py)
|
||||
# ------------------------------------------------------------------
|
||||
|
||||
def get_max_result_size(self, name: str, default: int | float | None = None) -> int | float:
|
||||
"""Return per-tool max result size, or *default* (or global default)."""
|
||||
entry = self._tools.get(name)
|
||||
if entry and entry.max_result_size_chars is not None:
|
||||
return entry.max_result_size_chars
|
||||
if default is not None:
|
||||
return default
|
||||
from tools.budget_config import DEFAULT_RESULT_SIZE_CHARS
|
||||
return DEFAULT_RESULT_SIZE_CHARS
|
||||
|
||||
def get_all_tool_names(self) -> List[str]:
|
||||
"""Return sorted list of all registered tool names."""
|
||||
return sorted(self._tools.keys())
|
||||
|
||||
@@ -811,6 +811,12 @@ def _stop_cleanup_thread():
|
||||
pass
|
||||
|
||||
|
||||
def get_active_env(task_id: str):
|
||||
"""Return the active BaseEnvironment for *task_id*, or None."""
|
||||
with _env_lock:
|
||||
return _active_environments.get(task_id)
|
||||
|
||||
|
||||
def get_active_environments_info() -> Dict[str, Any]:
|
||||
"""Get information about currently active environments."""
|
||||
info = {
|
||||
@@ -1617,4 +1623,5 @@ registry.register(
|
||||
handler=_handle_terminal,
|
||||
check_fn=check_terminal_requirements,
|
||||
emoji="💻",
|
||||
max_result_size_chars=100_000,
|
||||
)
|
||||
|
||||
@@ -0,0 +1,204 @@
|
||||
"""Tool result persistence -- preserves large outputs instead of truncating.
|
||||
|
||||
Defense against context-window overflow operates at three levels:
|
||||
|
||||
1. **Per-tool output cap** (inside each tool): Tools like search_files
|
||||
pre-truncate their own output before returning. This is the first line
|
||||
of defense and the only one the tool author controls.
|
||||
|
||||
2. **Per-result persistence** (maybe_persist_tool_result): After a tool
|
||||
returns, if its output exceeds the tool's registered threshold
|
||||
(registry.get_max_result_size), the full output is written INTO THE
|
||||
SANDBOX at /tmp/hermes-results/{tool_use_id}.txt via env.execute().
|
||||
The in-context content is replaced with a preview + file path reference.
|
||||
The model can read_file to access the full output on any backend.
|
||||
|
||||
3. **Per-turn aggregate budget** (enforce_turn_budget): After all tool
|
||||
results in a single assistant turn are collected, if the total exceeds
|
||||
MAX_TURN_BUDGET_CHARS (200K), the largest non-persisted results are
|
||||
spilled to disk until the aggregate is under budget. This catches cases
|
||||
where many medium-sized results combine to overflow context.
|
||||
"""
|
||||
|
||||
import logging
|
||||
import uuid
|
||||
|
||||
from tools.budget_config import (
|
||||
DEFAULT_PREVIEW_SIZE_CHARS,
|
||||
BudgetConfig,
|
||||
DEFAULT_BUDGET,
|
||||
)
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
PERSISTED_OUTPUT_TAG = "<persisted-output>"
|
||||
PERSISTED_OUTPUT_CLOSING_TAG = "</persisted-output>"
|
||||
STORAGE_DIR = "/tmp/hermes-results"
|
||||
HEREDOC_MARKER = "HERMES_PERSIST_EOF"
|
||||
_BUDGET_TOOL_NAME = "__budget_enforcement__"
|
||||
|
||||
|
||||
def generate_preview(content: str, max_chars: int = DEFAULT_PREVIEW_SIZE_CHARS) -> tuple[str, bool]:
|
||||
"""Truncate at last newline within max_chars. Returns (preview, has_more)."""
|
||||
if len(content) <= max_chars:
|
||||
return content, False
|
||||
truncated = content[:max_chars]
|
||||
last_nl = truncated.rfind("\n")
|
||||
if last_nl > max_chars // 2:
|
||||
truncated = truncated[:last_nl + 1]
|
||||
return truncated, True
|
||||
|
||||
|
||||
def _heredoc_marker(content: str) -> str:
|
||||
"""Return a heredoc delimiter that doesn't collide with content."""
|
||||
if HEREDOC_MARKER not in content:
|
||||
return HEREDOC_MARKER
|
||||
return f"HERMES_PERSIST_{uuid.uuid4().hex[:8]}"
|
||||
|
||||
|
||||
def _write_to_sandbox(content: str, remote_path: str, env) -> bool:
|
||||
"""Write content into the sandbox via env.execute(). Returns True on success."""
|
||||
marker = _heredoc_marker(content)
|
||||
cmd = (
|
||||
f"mkdir -p {STORAGE_DIR} && cat > {remote_path} << '{marker}'\n"
|
||||
f"{content}\n"
|
||||
f"{marker}"
|
||||
)
|
||||
result = env.execute(cmd, timeout=30)
|
||||
return result.get("returncode", 1) == 0
|
||||
|
||||
|
||||
def _build_persisted_message(
|
||||
preview: str,
|
||||
has_more: bool,
|
||||
original_size: int,
|
||||
file_path: str,
|
||||
) -> str:
|
||||
"""Build the <persisted-output> replacement block."""
|
||||
size_kb = original_size / 1024
|
||||
if size_kb >= 1024:
|
||||
size_str = f"{size_kb / 1024:.1f} MB"
|
||||
else:
|
||||
size_str = f"{size_kb:.1f} KB"
|
||||
|
||||
msg = f"{PERSISTED_OUTPUT_TAG}\n"
|
||||
msg += f"This tool result was too large ({original_size:,} characters, {size_str}).\n"
|
||||
msg += f"Full output saved to: {file_path}\n"
|
||||
msg += "Use the read_file tool with offset and limit to access specific sections of this output.\n\n"
|
||||
msg += f"Preview (first {len(preview)} chars):\n"
|
||||
msg += preview
|
||||
if has_more:
|
||||
msg += "\n..."
|
||||
msg += f"\n{PERSISTED_OUTPUT_CLOSING_TAG}"
|
||||
return msg
|
||||
|
||||
|
||||
def maybe_persist_tool_result(
|
||||
content: str,
|
||||
tool_name: str,
|
||||
tool_use_id: str,
|
||||
env=None,
|
||||
config: BudgetConfig = DEFAULT_BUDGET,
|
||||
threshold: int | float | None = None,
|
||||
) -> str:
|
||||
"""Layer 2: persist oversized result into the sandbox, return preview + path.
|
||||
|
||||
Writes via env.execute() so the file is accessible from any backend
|
||||
(local, Docker, SSH, Modal, Daytona). Falls back to inline truncation
|
||||
if write fails or no env is available.
|
||||
|
||||
Args:
|
||||
content: Raw tool result string.
|
||||
tool_name: Name of the tool (used for threshold lookup).
|
||||
tool_use_id: Unique ID for this tool call (used as filename).
|
||||
env: The active BaseEnvironment instance, or None.
|
||||
config: BudgetConfig controlling thresholds and preview size.
|
||||
threshold: Explicit override; takes precedence over config resolution.
|
||||
|
||||
Returns:
|
||||
Original content if small, or <persisted-output> replacement.
|
||||
"""
|
||||
effective_threshold = threshold if threshold is not None else config.resolve_threshold(tool_name)
|
||||
|
||||
if effective_threshold == float("inf"):
|
||||
return content
|
||||
|
||||
if len(content) <= effective_threshold:
|
||||
return content
|
||||
|
||||
remote_path = f"{STORAGE_DIR}/{tool_use_id}.txt"
|
||||
preview, has_more = generate_preview(content, max_chars=config.preview_size)
|
||||
|
||||
if env is not None:
|
||||
try:
|
||||
if _write_to_sandbox(content, remote_path, env):
|
||||
logger.info(
|
||||
"Persisted large tool result: %s (%s, %d chars -> %s)",
|
||||
tool_name, tool_use_id, len(content), remote_path,
|
||||
)
|
||||
return _build_persisted_message(preview, has_more, len(content), remote_path)
|
||||
except Exception as exc:
|
||||
logger.warning("Sandbox write failed for %s: %s", tool_use_id, exc)
|
||||
|
||||
logger.info(
|
||||
"Inline-truncating large tool result: %s (%d chars, no sandbox write)",
|
||||
tool_name, len(content),
|
||||
)
|
||||
return (
|
||||
f"{preview}\n\n"
|
||||
f"[Truncated: tool response was {len(content):,} chars. "
|
||||
f"Full output could not be saved to sandbox.]"
|
||||
)
|
||||
|
||||
|
||||
def enforce_turn_budget(
|
||||
tool_messages: list[dict],
|
||||
env=None,
|
||||
config: BudgetConfig = DEFAULT_BUDGET,
|
||||
) -> list[dict]:
|
||||
"""Layer 3: enforce aggregate budget across all tool results in a turn.
|
||||
|
||||
If total chars exceed budget, persist the largest non-persisted results
|
||||
first (via sandbox write) until under budget. Already-persisted results
|
||||
are skipped.
|
||||
|
||||
Mutates the list in-place and returns it.
|
||||
"""
|
||||
candidates = []
|
||||
total_size = 0
|
||||
for i, msg in enumerate(tool_messages):
|
||||
content = msg.get("content", "")
|
||||
size = len(content)
|
||||
total_size += size
|
||||
if PERSISTED_OUTPUT_TAG not in content:
|
||||
candidates.append((i, size))
|
||||
|
||||
if total_size <= config.turn_budget:
|
||||
return tool_messages
|
||||
|
||||
candidates.sort(key=lambda x: x[1], reverse=True)
|
||||
|
||||
for idx, size in candidates:
|
||||
if total_size <= config.turn_budget:
|
||||
break
|
||||
msg = tool_messages[idx]
|
||||
content = msg["content"]
|
||||
tool_use_id = msg.get("tool_call_id", f"budget_{idx}")
|
||||
|
||||
replacement = maybe_persist_tool_result(
|
||||
content=content,
|
||||
tool_name=_BUDGET_TOOL_NAME,
|
||||
tool_use_id=tool_use_id,
|
||||
env=env,
|
||||
config=config,
|
||||
threshold=0,
|
||||
)
|
||||
if replacement != content:
|
||||
total_size -= size
|
||||
total_size += len(replacement)
|
||||
tool_messages[idx]["content"] = replacement
|
||||
logger.info(
|
||||
"Budget enforcement: persisted tool result %s (%d chars)",
|
||||
tool_use_id, size,
|
||||
)
|
||||
|
||||
return tool_messages
|
||||
@@ -2085,6 +2085,7 @@ registry.register(
|
||||
check_fn=check_web_api_key,
|
||||
requires_env=_web_requires_env(),
|
||||
emoji="🔍",
|
||||
max_result_size_chars=100_000,
|
||||
)
|
||||
registry.register(
|
||||
name="web_extract",
|
||||
@@ -2096,4 +2097,5 @@ registry.register(
|
||||
requires_env=_web_requires_env(),
|
||||
is_async=True,
|
||||
emoji="📄",
|
||||
max_result_size_chars=100_000,
|
||||
)
|
||||
|
||||
@@ -44,6 +44,7 @@ import fire
|
||||
from rich.progress import Progress, SpinnerColumn, TextColumn, BarColumn, TaskProgressColumn, TimeElapsedColumn, TimeRemainingColumn
|
||||
from rich.console import Console
|
||||
from hermes_constants import OPENROUTER_BASE_URL
|
||||
from agent.retry_utils import jittered_backoff
|
||||
|
||||
# Load environment variables
|
||||
from dotenv import load_dotenv
|
||||
@@ -585,7 +586,7 @@ Write only the summary, starting with "[CONTEXT SUMMARY]:" prefix."""
|
||||
self.logger.warning(f"Summarization attempt {attempt + 1} failed: {e}")
|
||||
|
||||
if attempt < self.config.max_retries - 1:
|
||||
time.sleep(self.config.retry_delay * (attempt + 1))
|
||||
time.sleep(jittered_backoff(attempt + 1, base_delay=self.config.retry_delay, max_delay=30.0))
|
||||
else:
|
||||
# Fallback: create a basic summary
|
||||
return "[CONTEXT SUMMARY]: [Summary generation failed - previous turns contained tool calls and responses that have been compressed to save context space.]"
|
||||
@@ -647,7 +648,7 @@ Write only the summary, starting with "[CONTEXT SUMMARY]:" prefix."""
|
||||
self.logger.warning(f"Summarization attempt {attempt + 1} failed: {e}")
|
||||
|
||||
if attempt < self.config.max_retries - 1:
|
||||
await asyncio.sleep(self.config.retry_delay * (attempt + 1))
|
||||
await asyncio.sleep(jittered_backoff(attempt + 1, base_delay=self.config.retry_delay, max_delay=30.0))
|
||||
else:
|
||||
# Fallback: create a basic summary
|
||||
return "[CONTEXT SUMMARY]: [Summary generation failed - previous turns contained tool calls and responses that have been compressed to save context space.]"
|
||||
|
||||
@@ -196,6 +196,55 @@ branding:
|
||||
tool_prefix: "▏"
|
||||
```
|
||||
|
||||
## Hermes Mod — Visual Skin Editor
|
||||
|
||||
[Hermes Mod](https://github.com/cocktailpeanut/hermes-mod) is a community-built web UI for creating and managing skins visually. Instead of writing YAML by hand, you get a point-and-click editor with live preview.
|
||||
|
||||
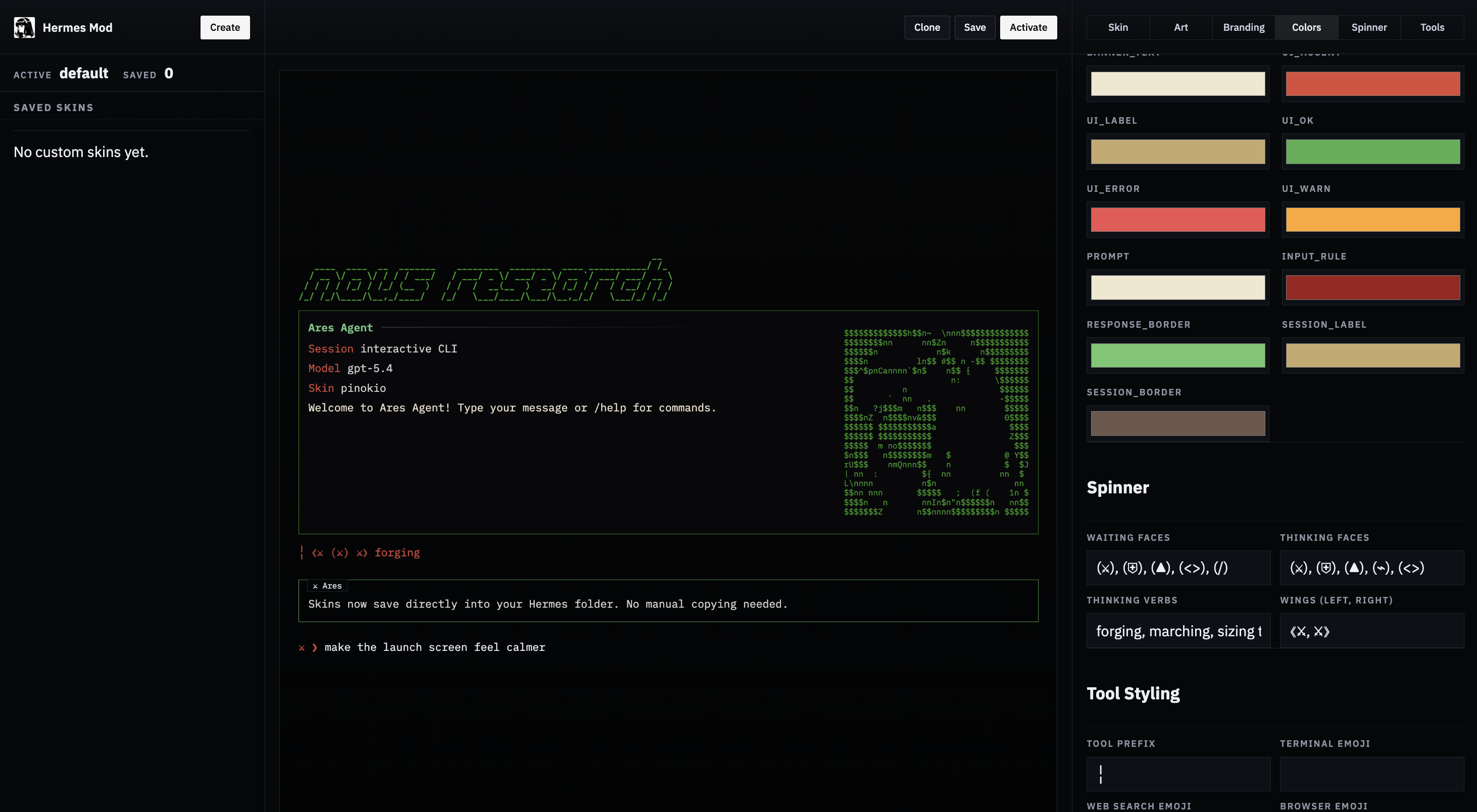
|
||||
|
||||
**What it does:**
|
||||
|
||||
- Lists all built-in and custom skins
|
||||
- Opens any skin into a visual editor with all Hermes skin fields (colors, spinner, branding, tool prefix, tool emojis)
|
||||
- Generates `banner_logo` text art from a text prompt
|
||||
- Converts uploaded images (PNG, JPG, GIF, WEBP) into `banner_hero` ASCII art with multiple render styles (braille, ASCII ramp, blocks, dots)
|
||||
- Saves directly to `~/.hermes/skins/`
|
||||
- Activates a skin by updating `~/.hermes/config.yaml`
|
||||
- Shows the generated YAML and a live preview
|
||||
|
||||
### Install
|
||||
|
||||
**Option 1 — Pinokio (1-click):**
|
||||
|
||||
Find it on [pinokio.computer](https://pinokio.computer) and install with one click.
|
||||
|
||||
**Option 2 — npx (quickest from terminal):**
|
||||
|
||||
```bash
|
||||
npx -y hermes-mod
|
||||
```
|
||||
|
||||
**Option 3 — Manual:**
|
||||
|
||||
```bash
|
||||
git clone https://github.com/cocktailpeanut/hermes-mod.git
|
||||
cd hermes-mod/app
|
||||
npm install
|
||||
npm start
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
1. Start the app (via Pinokio or terminal).
|
||||
2. Open **Skin Studio**.
|
||||
3. Choose a built-in or custom skin to edit.
|
||||
4. Generate a logo from text and/or upload an image for hero art. Pick a render style and width.
|
||||
5. Edit colors, spinner, branding, and other fields.
|
||||
6. Click **Save** to write the skin YAML to `~/.hermes/skins/`.
|
||||
7. Click **Activate** to set it as the current skin (updates `display.skin` in `config.yaml`).
|
||||
|
||||
Hermes Mod respects the `HERMES_HOME` environment variable, so it works with [profiles](/docs/user-guide/profiles) too.
|
||||
|
||||
## Operational notes
|
||||
|
||||
- Built-in skins load from `hermes_cli/skin_engine.py`.
|
||||
|
||||
Reference in New Issue
Block a user